
撰稿 | 言征
出品 | 51CTO技术栈(微信号:blog51cto)
Gentoo Linux是一套通用的、快捷的、完全免费的Linux发行版,因出色的包管理系统Portage而被开发人员广为喜爱。最近,GentooLinux社区宣布:发行版将不再允许人工智能生成和辅助代码贡献。
一、Gentoo Linux禁AI令:AI生成的代码贡献要分叉Gentoo理事会成员MichałGórny最初于2月27日提出了对人工智能代码的禁令,Gentoo是一个管理Linux发行版的民选委员会。Górny主张禁止人工智能有三个主要原因:潜在的版权侵权、质量控制问题、对人工智能高功耗的道德考虑以及大公司在技术塑造中的作用。
首先是版权问题。当下,有关AI生成内容的版权情况尚不明朗。但有一点确认的是,几乎所有LLM都是在庞大的版权材料语料库上进行培训的,以及所有花哨的“人工智能”公司都不会对侵犯版权的行为嗤之以鼻。
特别是,这些工具很有可能产生我们不能合法使用的东西。
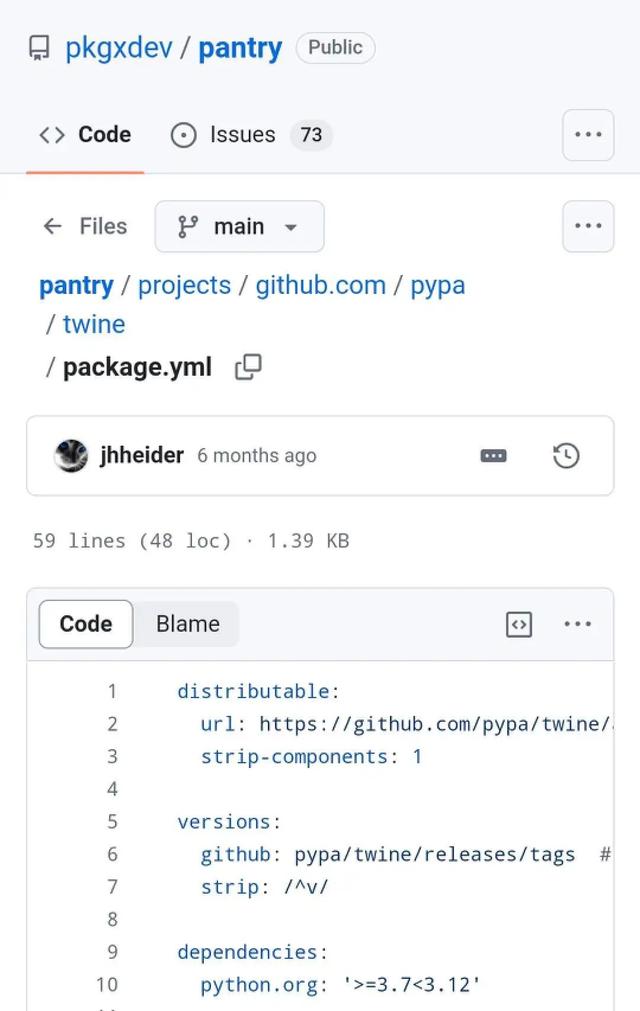
其次是质量问题。LLM非常擅长生成看似合理实则胡说八道的内容。如果你足够小心,LLM可以提供不错的帮助,但我们总不能真的依赖于我们所有的贡献者都能意识到全部风险。2月25日,Github用户就发现了一个没有任何描述的奇怪代码包。

图片
图片
问题描述:“pantry仓库中列出的项目描述来源于每个项目的package.yml文件。这些YAML文件包含了项目的元数据,包括项目的名称、版本、作者、描述等。你可以在pantry仓库中的twine package.yml文件中看到这样的例子。
然而,我并未找到关于这些描述如何生成或是否涉及自动过程的具体信息。可能你在pkgx.dev上看到的描述是占位符,或者是以某种方式生成的,没有准确反映项目的目的。”
最后,伦理问题。如上所述,“人工智能”企业既不重视版权,也不关心人类。人工智能泡沫正在造成巨大的能源浪费,它为裁员和加大对IT工作者的剥削提供了绝佳的借口。它正在推动互联网的恶化,助长了各类垃圾邮件和诈骗活动。
二、英伟达被起诉,阿里被AI虚拟包坑了这些顾虑并非空穴来风,并且已经影响到了大家生活的方方面面。
版权问题方面,无疑正在成为人工智能模型的一个长期问题,这些模型正在使用受保护材料的训练,英伟达是最新被起诉的公司之一。

源:theRegister
Books3的三位作者在旧金山对英伟达发起了诉讼,理由是使用数据集训练NeMo Megatron-GPT模型,该模型已知包含许多未经许可的版权作品。
再者就是,人工智能还会产生毫无意义的文本和代码,甚至会使整个软件包产生幻觉。最近的一个知名的例子就是阿里巴巴。
被AI愚弄过关,而误把不存在的软件包添加进开源项目的企业不在少数,阿里巴巴便是其中之一。几个星期前,外媒就曾报道阿里一个名为“GraphTranslator”的github项目中,在安装说明里包含下载Python软件包huggingface cli的pip命令。
然而事实上,pip-install huggingfaces cli并不合法,是人工智能想象出来的,正确的命令应该是pip install -U "huggingface_hub[cli]".

源:theRegister
但是,通过PyPI分发并由阿里巴巴的GraphTranslator要求的huggingface cli(使用pip-install huggingfaces cli安装)是假的,是人工智能想象的。据悉,huggingface cli是一位代码安全研究员Lanyado用AI虚构的一场钓鱼实验。
在看到生成人工智能反复产生幻觉后,Lanyado于去年12月创建了huggingface-cli;到今年2月,阿里巴巴在GraphTranslator的README指令中提到了它,而不是真正的Hugging Face CLI工具。
这也就说明:在项目开发过程中由生成式人工智能发明的包名是会随着时间的推移而持续存在,这种虚假的依赖包,甚至可以通过AI虚构的代码名称来编写实际包来分发恶意代码。
这还没完,据Lanyado试验显示,GPT-3.5-Turbo、GPT-4、Gemini Pro aka、Bard和Command(Cohere),这些模型在五种不同编程语言/运行时(Python、Node.js、Go、.Net和Ruby)中,每种语言都有各自的打包系统。事实证明,这些聊天机器人凭空提取的一部分名字是持久的,有些是别名或衍生版本。
现在,小编发现GraphTranslator的安装引导说明中已经没有了上述AI造假的包名。
至于生成式AI模型所需要的水和能源的问题,相信大家已有耳闻。据《纽约客》杂志引援国外研究机构报告,ChatGPT每天要响应大约2亿个请求,在此过程中消耗超过50万度电力,也就是说,ChatGPT每天用电量相当于1.7万个美国家庭的用电量。而随着生成式AI的广泛应用,预计到2027年,整个人工智能行业每年将消耗85至134太瓦时(1太瓦时=10亿千瓦时)的电力。
除了耗电,和ChatGPT或其他生成式AI聊天,也会消耗水资源。加州大学河滨分校研究显示,ChatGPT每与用户交流25-50个问题,就可消耗500毫升的水。
我们也许在惊叹大模型给出问题答案的同时,并没有想到背后环境资源做出了怎样的“牺牲”。
话说回来,版权、质量和伦理,AI明显还没有很好的方法来规避。这也是为什么Gentoo最后决定禁止AI代码提交的原因。
三、Linux社区需要预防AI除了禁止人工智能代码提交,Górny说他还希望Gentoo为Linux社区提供一些独特的东西。

图片
“Gentoo 一直以来都是与众不同的存在,它满足了主流发行版所无法满足的人群的需求。我认为,将“由真实的人制作”纳入我们的优势列表中是一个不错的想法——但我们需要制定相关政策,以确保不良内容不会涌入。”
“我认为这对Gentoo来说是一个很好的公关举措,”Górny表示。“当很多项目都对‘人工智能’充满热情时,我觉得许多Gentoo用户真的很欣赏老式的软件工程方法,在这种方法中,人比‘生产力’更重要。”
这项禁令及其提议是先发制人的,不是Gentoo社区任何特定事件的结果。“我们正在采取早期预防措施,”Górny解释道。
四、人工智能被全面禁止,但可能不会永远禁止理事会最初在3月10日预定的月度会议上讨论了Górny提出的禁令。然而,由于禁令的措辞尚未制定,许多理事会成员希望讨论更多细节,因此没有采取任何行动。该禁令最终在4月14日的理事会会议上颁布,以6比0通过,其中一名成员缺席投票。
“我个人的观点是,我们只是从这个话题开始,”Górny说。“我怀疑,当我们真正正确地宣布它,并让用户了解它时,我们会看到更多的用户反馈。”
Gentoo社区已经讨论了在电子邮件线程和IRC聊天室中的潜在禁令,Górny表示,人们一致认为应该实施“一些限制”。随着禁令的全面生效,它可以鼓励更多Gentoo社区成员分享他们对人工智能的看法。
当然,执行禁令将是一项挑战;一个人如何区分由真人编写的代码和由机器编写的代码?在Górny看来,禁令的有效性并不是真正的重点。
他说:“我们的主要目标是明确哪些是可以接受的,哪些是不可以的,并礼貌地要求我们的贡献者尊重这一点。”他补充道,人工智能禁令主要是对当前受版权保护代码规则的延伸。
Górny补充道:“如果我们收到的文件中包含非常‘奇怪’的错误,这种错误似乎不太可能是人为错误造成的,我们会提出问题,但我认为这(禁令)是我们能做的最好的事情。”
五、或为AI破例:为Linux单独训练自身的大模型然而,该禁令明确包括一项条款,规定未来可以重新审视该政策,这是一些理事会成员明确要求的。理事会成员Sam James说,随着事态的迅速发展,一年后情况可能会发生很大变化(或者根本没有变化)。
该委员会已经预见到未来的情况,他们将为人工智能破例——一种专门针对Gentoo训练的模型。这将(在理论上)消除对侵犯版权的担忧,并可能产生更高质量的代码。
来源: 51CTO技术栈
