这篇论文的标题是《LLMs Know More Than They Show: On the Intrinsic Representation of LLM Hallucinations》,由 Hadas Orgad、Michael Toker、Zorik Gekhman、Roi Reichart、Idan Szpektor、Hadas Kotek 和 Yonatan Belinkov完成。以下是论文的详细介绍:
摘要大型语言模型(LLMs)经常产生错误,包括事实不准确、偏见和推理失败,这些统称为“幻觉”。最近的研究表明,LLMs的内部状态中编码了关于输出真实性的信息,这些信息可以用来检测错误。在这项工作中,我们发现LLMs的内部表示编码了比之前认知的更多关于真实性的信息。我们首先发现,真实性信息集中在特定的标记中,利用这一特性显著提高了错误检测的性能。然而,我们也展示了这样的错误检测器无法在不同数据集之间泛化,这意味着,与之前的观点相反,真实性的编码并不是普遍的,而是多面的。接下来,我们显示内部表示也可以用来预测模型可能会犯的错误类型,从而促进量身定制的缓解策略的发展。最后,我们揭示了LLMs的内部编码与外部行为之间的差异:它们可能会编码正确答案,但却一致产生错误答案。综合来看,这些见解加深了我们从模型内部视角理解LLM错误的能力,可以为未来增强错误分析和缓解策略的研究提供指导。
研究背景大型语言模型(LLMs)在生成文本时,常常会出现事实错误、偏见和推理失败等问题,这些错误被称为“幻觉”(hallucinations)。近期研究表明,LLMs 的内部状态确实包含有关其输出真实性的信息。
 主要贡献证明了 LLMs 的内部表示比之前认识的要丰富得多,包含更多有关输出真实性的信息。提出了一种利用这些内部表示来检测和纠正错误的方法。研究方法
主要贡献证明了 LLMs 的内部表示比之前认识的要丰富得多,包含更多有关输出真实性的信息。提出了一种利用这些内部表示来检测和纠正错误的方法。研究方法研究人员通过分析 LLMs 的内部状态,发现了其对输出真实性的编码信息。他们利用这些信息开发了一种新的检测和纠正错误的方法。
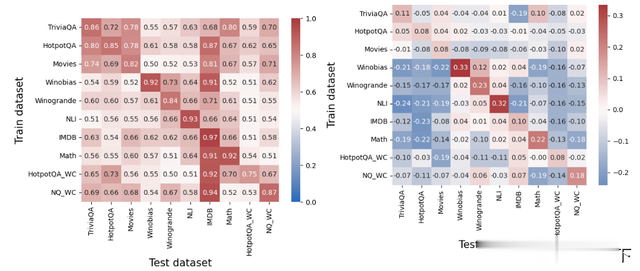 实验结果
实验结果实验结果显示,利用内部表示信息的方法能够有效地检测和纠正 LLMs 的错误,提高了模型的准确性。
 结论
结论LLMs 的内部表示包含了更多有关输出真实性的信息,这些信息可以用于检测和纠正错误,从而提高模型的准确性。
一句话总结利用大型语言模型的内部表示信息,可以有效检测和纠正其生成的错误。
论文链接https://arxiv.org/abs/2410.02707
