Python具有强大的数据分析和处理能力,使用Python做数据分析需掌握pandas、matplotlib、seaborn这三个Python包,掌握Python数据分析知识,可帮助我们更好地发现数据背后的规律和趋势,为业务决策提供支持。
使用Pandas数据读取首先,导入pandas库,pandas库有强大的数据处理能力,使用read_excel函数可导入数据,只要导入文件路径即可导入数据,head可以预览前5行数据。
import pandas as pddf=pd.read_excel(r'C:\Desktop\电商销售数据-23年8月.xlsx')df.head()#预览前5行数据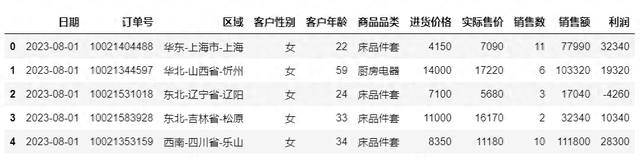
info函数可以看各个字段的信息,包括非空值计数,数据类型,比如,这里的日期为日期型数据,区域为字符型数据,客户年龄为数值型数据。
df.info()#数据信息预览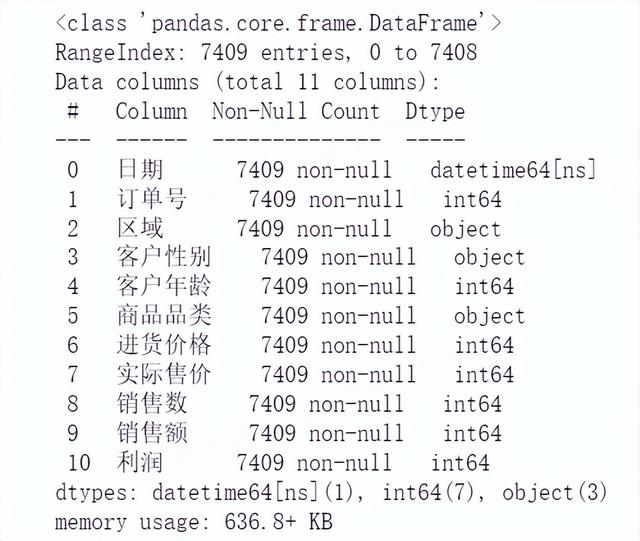
使用describe函数对数据进行描述统计,描述统计内容包括计数、平均值、标准差、最小值、最大值等,比如对客户年龄进行描述统计,平均客户年龄为42岁,年龄最小的客户为22岁,年龄最大的客户为62岁。
df.describe()#数据描述统计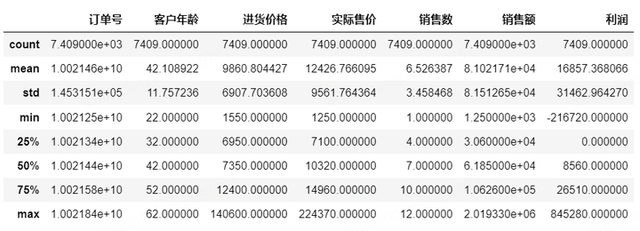 使用Pandas数据排序
使用Pandas数据排序sort_values函数可用于数据排序,by导入排序的数据列,默认排序是升序排序。
df.sort_values(by='销售额',inplace=True)#默认升序排序df
ascending=False参数可以降序排列。
df.sort_values(by='销售额',inplace=True,ascending=False)#降序排序df
如果要自定义排序,比如商品品类升序排序,销售额降序排序,by导入自定义数据列,ascending设置参数,True升序排序,False降序排序。
df.sort_values(by=['商品品类','销售额'],ascending=[True,False],inplace=True)#自定义排序df 使用Pandas数据过滤
使用Pandas数据过滤数据筛选使用数据框[]筛选,数据框里面写条件用于数据筛选,&当条件均满足时筛选,==满足特定条件筛选,这里表示筛选客户性别是男且客户年龄大于60的数据。
df[(df['客户性别']=='男')&(df['客户年龄']>60)]#数据筛选&与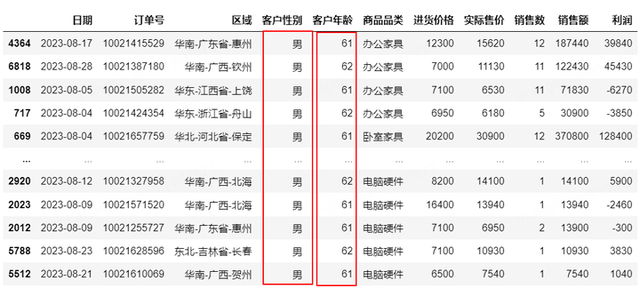
下面筛选区域是“西北-甘肃省-白银”或者商品品类是“电脑硬件”的数据,& 当条件均满足时筛选,| 满足其一条件时筛选数据。
df[(df['区域']=='西北-甘肃省-白银')|(df['商品品类']=='电脑硬件')]#数据筛选|或
isin可筛选特定标签的数据,()内写具体的筛选标签即可,比如下面筛选特定订单号的数据。
df[df['订单号'].isin(['10021296335','10021669688','10021250896','10021434444','10021412817'])] 使用Pandas数据拆分
使用Pandas数据拆分通过str.split方法对列中的数据进行拆分,expand参数设置为True,将返回包含拆分后的数据的DataFrame对象,如下将区域拆分为“省份”和“城市”两列。
df_split=df['区域'].str.split(pat='-',expand=True)#数据拆分df['区域']=df_split.iloc[:,0]df['省份']=df_split.iloc[:,1]df['城市']=df_split.iloc[:,2]df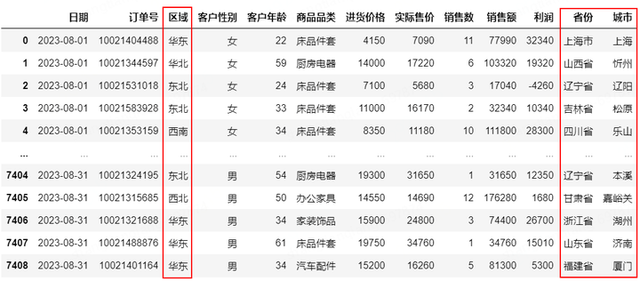 使用Pandas统计运算
使用Pandas统计运算对数据进行统计运算,count用于计数,比如这里对订单号计数,计数结果有7409单。
df['订单号'].count()#计数7409
如果对商品品类非重复计数,可以先使用unique返回非重复的列表,然后使用len对列表计数,返回结果商品品类有8个非重复值。
len(df['商品品类'].unique())#非重复计数8
对销售数求和,sum用于求和,这里结果显示销售数总数为48354个。
df['销售数'].sum()#求和48354
对每一个商品品类的订单数计数,使用groupby分组计数,即可得到每一个商品品类的订单数。
df.groupby(['商品品类'])['订单号'].count().reset_index()#分组计数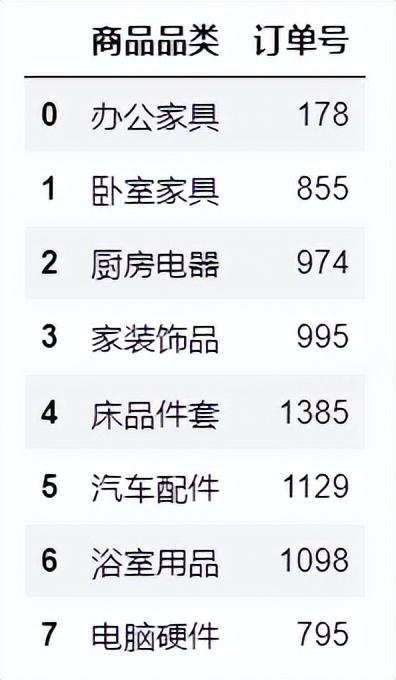 使用Python数据作图
使用Python数据作图Python中的matplotlib和seaborn库有强大的数据可视化功能,对各个区域的销售数计数,导入matplotlib包,传入销售数据列,并对具体的图表参数进行设置,可得出华南区域的销售数占比最大为36.3%,西南区域的销售数占比最小为3.1%。
import matplotlib.pyplot as plt import matplotlib.style as pslplt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签plt.rcParams['axes.unicode_minus']=False #用来正常显示负号psl.use('ggplot')df_QY=df.groupby(['区域'])['销售数'].count().reset_index()#饼图labels = df_QY['区域'].tolist()explode = [0.05,0.05,0,0,0,0] # 用于突出显示数据df_QY['销售数'].plot(kind='pie',figsize=(9,6), autopct='%.1f%%',#数据标签 labels=labels, startangle=260, #初始角度 explode=explode, # 突出显示数据 pctdistance=0.87, # 设置百分比标签与圆心的距离 textprops = {'fontsize':12, 'color':'k'}, # 设置文本标签的属性值 )plt.title("各区域销售数占比")plt.show()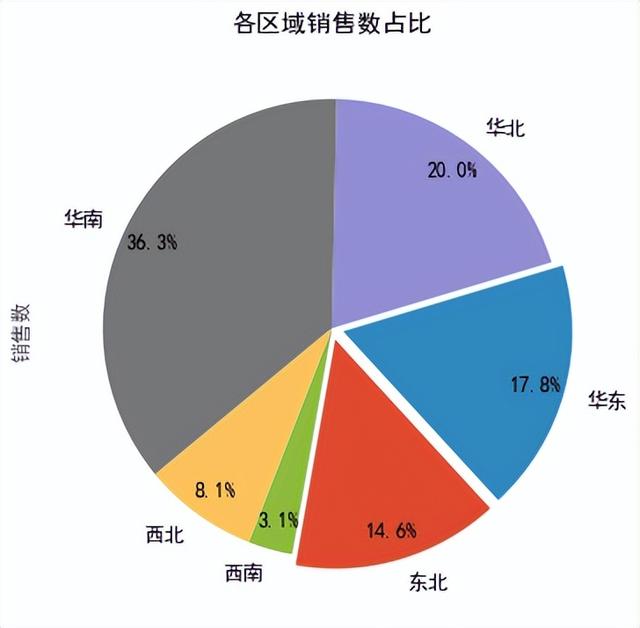
对利润做箱线图,使用boxplot函数,并对箱线图图表的参数进行设置,可得出利润的数据分布情况,箱线图中的大多数利润数据都超过了箱线图的上下限。
import matplotlib.pyplot as plt import matplotlib.style as pslplt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签plt.rcParams['axes.unicode_minus']=False #用来正常显示负号psl.use('ggplot')plt.title('利润箱线图')df_XB=df[df['区域']=='西北']#箱线图plt.boxplot(x=df_XB['利润'],#指定绘制箱线图的数据 whis=1.5, #指定1.5倍的四分位数差 widths=0.1, #指定箱线图中箱子的宽度为0.3 showmeans=True, #显示均值 #patch_artist=True, #填充箱子的颜色 #boxprops={'facecolor':'RoyalBlue'}, #指定箱子的填充色为宝蓝色 flierprops={'markerfacecolor':'red','markeredgecolor':'red','markersize':3}, #指定异常值的填充色、边框色和大小 meanprops={'marker':'h','markerfacecolor':'black','markersize':8}, #指定中位数的标记符号(虚线)和颜色 medianprops={'linestyle':'--','color':'orange'}, #指定均值点的标记符号(六边形)、填充色和大小 labels=['西北'] )plt.show()
对销售数做折线图,导入seaborn库,日期列做为X轴,销售数作为Y轴,由折线图可以看到销售数随日期的波动变化趋势。
import seaborn as sns import matplotlib.pyplot as plt plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签plt.rcParams['axes.unicode_minus']=False #用来正常显示负号plt.figure(figsize=(10,6)) # 使用Seaborn绘制折线图 sns.lineplot(data=df, x='日期', y='销售数', color='blue') # 设置图表标题和轴标签 plt.title('销售数折线图') plt.xlabel('日期') plt.ylabel('销售额') # 显示图形 plt.show()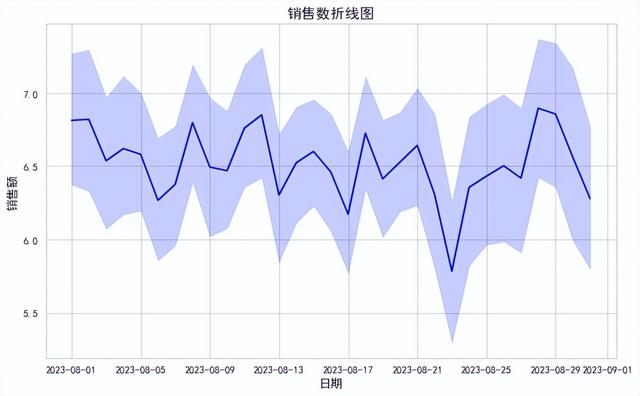
对商品品类做词云图进行展示,wordcloud库可专门做词云图,通过使用字典统计商品类别数量,创建词云对象后,使用matplotlib绘制词云图,由词云图可以看出床品件套的品类最多,办公家具的品类最少。
from wordcloud import WordCloud import matplotlib.pyplot as plt # 商品类别列表product_categories = df['商品品类'].tolist() # 使用字典统计商品类别数量 category_counts = dict() for category in product_categories: if category in category_counts: category_counts[category] += 1 else: category_counts[category] = 1 #创建词云对象 wordcloud = WordCloud(font_path='simhei.ttf', background_color='white').generate_from_frequencies(category_counts) # 使用matplotlib绘制词云图 plt.figure(figsize=(9, 6)) plt.imshow(wordcloud, interpolation='bilinear') plt.axis("off") plt.show()
利用Python进行数据分析需熟练掌握pandas、matplotlib、seaborn等Python库,还要具备编程和数据分析基本技能。如果你想学习更多Python数据分析知识,可以关注我,持续分享数据分析知识,帮助你更好地掌握Python!
