其实并没有标准定义。一般认为,消息中间件属于分布式系统中一个子系统,关注于数据的发送和接收,利用高效可靠的异步消息传递机制对分布式系统中的其余各个子系统进行集成。
高效:对于消息的处理处理速度快。
可靠:一般消息中间件都会有消息持久化机制和其他的机制确保消息不丢失。
异步:指发送完一个请求,不需要等待返回,随时可以再发送下一个请求,既不需要等待。
一句话总结,我们消息中间件不生产消息,只是消息的搬运工。
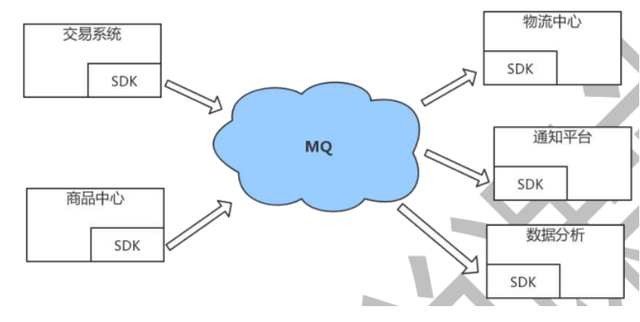 为什么要用消息中间件?
为什么要用消息中间件?假设一个电商交易的场景,用户下单之后调用库存系统减库存,然后需要调用物流系统进行发货,如果交易、库存、物流是属于一个系统的,那么就是接口调用。但是随着系统的发展,各个模块越来越庞大、业务逻辑越来越复杂,必然是要做服务化和业务拆分的。这个时候就需要考虑这些系统之间如何交互,一般的处理方式就是 RPC(Remote Procedure Call)(具体实现 dubbo,SpringCloud)。系统继续发展,可能一笔交易后续需要调用几十个接口来执行业务,比如还有风控系统、短信服务等等。这个时候就需要消息中间件登场来解决问题了。所以消息中间件主要解决分布式系统之间消息的传递,同时为分布式系统中其他子系统提供了松耦合的架构,同时还有以下好处:
低耦合
低耦合,不管是程序还是模块之间,使用消息中间件进行间接通信。
异步通信能力
异步通信能力,使得子系统之间得以充分执行自己的逻辑而无需等待。
缓冲能力
缓冲能力,消息中间件像是一个巨大的蓄水池,将高峰期大量的请求存储下来慢慢交给后台进行处理,对于秒杀业务来说尤为重要。
伸缩性
伸缩性,是指通过不断向集群中加入服务器的手段来缓解不断上升的用户并发访问压力和不断增长的数据存储需求。就像弹簧一样挂东西一样,用户多,伸一点,用户少,浅一点,啊,不对,缩一点。是伸缩,不是深浅。衡量架构是否高伸缩性的主要标准就是是否可用多台服务器构建集群,是否容易向集群中添加新的服务器。加入新的服务器后是否可以提供和原来服务器无差别的服务。集群中可容纳的总的服务器数量是否有限制。
扩展性
扩展性,主要标准就是在网站增加新的业务产品时,是否可以实现对现有产品透明无影响,不需要任何改动或者很少改动既有业务功能就可以上线新产品。比如用户购买电影票的应用,现在我们要增加一个功能,用户买了铁血战士的票后,随机抽取用户送异形的限量周边。怎么做到不改动用户购
票功能的基础上增加这个功能。熟悉设计模式的同学,应该很眼熟,这是设计模式中的开闭原则(对扩展开放,对修改关闭)在架构层面的一个原则。
和 RPC 有何区别?RPC 和消息中间件的场景的差异很大程度上在于就是“依赖性”和“同步性”。


依赖性:
比如短信通知服务并不是交易环节必须的,并不影响下单流程,不是强依赖,所以交易系统不应该依赖短信服务。如果是 RPC 调用,短信通知服务挂了,整个业务就挂了(不考虑熔断),这个就是依赖性导致的,而消息中间件则没有这个依赖性。
消息中间件出现以后对于交易场景可能是调用库存中心等强依赖系统执行业务,之后发布一条消息(这条消息存储于消息中间件中)。像是短信通知服务、数据统计服务等等都是依赖于消息中间件去消费这条消息来完成自己的业务逻辑。
同步性:
RPC 方式是典型的同步方式(其实当前也有异步的),让远程调用像本地调用。消息中间件方式属于异步方式。
在异步里面MQ是首选。RPC异步只适用于部分场景。


相同点:都是分布式下面的通信方式。
消息中间件有些什么使用场景?异步处理
场景说明:用户注册后,需要发注册邮件和注册短信或者相关push。传统的做法有两种 1.串行的方式;2.并行方式。
(1)串行方式:将注册信息写入数据库成功后,发送注册邮件,再发送注册短信。以上三个任务全部完成后,返回给客户端。

(2)并行方式:将注册信息写入数据库成功后,发送注册邮件的同时,发送注册短信。以上三个任务完成后,返回给客户端。与串行的差别是,并行的方式可以提高处理的时间。
假设三个业务节点每个使用 50 毫秒钟,不考虑网络等其他开销,则串行方式的时间是 150 毫秒,并行的时间可能是 100 毫秒。

小结:如以上案例描述,传统的方式系统的性能(并发量,吞吐量,响应时间)会有瓶颈。如何解决这个问题呢?
引入消息队列,将不是必须的业务逻辑,异步处理。
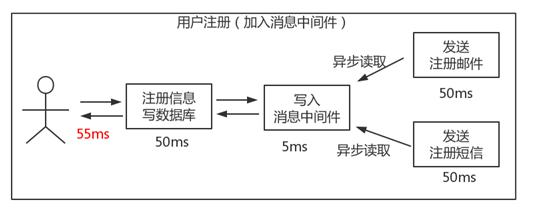
按照以上约定,用户的响应时间相当于是注册信息写入数据库的时间,也就是 50 毫秒。注册邮件,发送短信写入消息队列后,直接返回,因此写入消息队列的速度很快,基本可以忽略,因此用户的响应时间可能是 50 毫秒。因此架构改变后,系统的吞吐量提高到每秒 20 QPS。比串行提高了 3 倍,比并行提高了两倍。
应用解耦场景说明:用户下单后,订单系统需要通知库存系统。传统的做法是,订单系统调用库存系统的接口。
传统模式的缺点:
1) 假如库存系统无法访问,则订单减库存将失败,从而导致订单失败;
2) 订单系统与库存系统耦合;

如何解决以上问题呢?引入应用消息队列后的方案
订单系统:用户下单后,订单系统完成持久化处理,将消息写入消息队列,返回用户订单下单成功。
库存系统:订阅下单的消息,采用拉/推的方式,获取下单信息,库存系统根据下单信息,进行库存操作。

假如:在下单时库存系统不能正常使用。也不影响正常下单,因为下单后,订单系统写入消息队列就不再关心其他的后续操作了。实现订单系统与库存系统的应用解耦。
流量削峰流量削峰也是消息队列中的常用场景,一般在秒杀或团抢活动中使用广泛。
应用场景:秒杀活动,一般会因为流量过大,导致流量暴增,应用挂掉。为解决这个问题,一般需要在应用前端加入消息队列:可以控制活动的人数;可以缓解短时间内高流量压垮应用。
用户的请求,服务器接收后,首先写入消息队列。假如消息队列长度超过最大数量,则直接抛弃用户请求或跳转到错误页面;秒杀业务根据消息队列中的请求信息,再做后续处理。
日志处理日志处理是指将消息队列用在日志处理中,比如 Kafka 的应用,解决大量日志传输的问题。架构简化如下:

日志采集客户端,负责日志数据采集,定时写入 Kafka 队列:Kafka 消息队列,负责日志数据的接收,存储和转发;日志处理应用:订阅并消费 kafka队列中的日志数据;
消息通讯
消息通讯是指,消息队列一般都内置了高效的通信机制,因此也可以用在纯的消息通讯。比如实现点对点消息队列,或者聊天室等。
点对点通讯:客户端 A 和客户端 B 使用同一队列,进行消息通讯。
聊天室通讯:客户端 A,客户端 B,客户端 N 订阅同一主题,进行消息发布和接收。实现类似聊天室效果。
消息中间件的编年史
卡夫卡与法国作家马塞尔·普鲁斯特,爱尔兰作家詹姆斯·乔伊斯并称为西方现代主义文学的先驱和大师。《变形记》是卡夫卡的短篇代表作,是卡夫卡的艺术成就中的一座高峰,被认为是 20 世纪最伟大的小说作品之一。
常见的消息中间件比较

如果一般的业务系统要引入 MQ,怎么选型:
用户访问量在 ActiveMQ 的可承受范围内,而且确实主要是基于解耦和异步来用的,可以考虑 ActiveMQ,也比较贴近 Java 工程师的使用习惯,但是ActiveMQ 现在停止维护了,同时 ActiveMQ 并发不高,所以业务量一定的情况下可以考虑使用。
RabbitMQ 作为一个纯正血统的消息中间件,有着高级消息协议 AMQP 的完美结合,在消息中间件中地位无可取代,但是 erlang 语言阻止了我们去深入研究和掌控,对公司而言,底层技术无法控制,但是确实是开源的,有比较稳定的支持,活跃度也高。
对自己公司技术实力有绝对自信的,可以用 RocketMQ 。
所以中小型公司,技术实力较为一般,技术挑战不是特别高,用 ActiveMQ、RabbitMQ 是不错的选择;大型公司,基础架构研发实力较强,用 RocketMQ是很好的选择。
如果是大数据领域的实时计算、日志采集等场景,用 Kafka 是业内标准的,绝对没问题,社区活跃度很高,几乎是全世界这个领域的事实性规范。
整体上来看,使用文件系统的消息中间件(kafka、rokcetMq)性能是最好的,所以基于文件系统存储的消息中间件是发展趋势。(从存储方式和效率来看 文件系统>KV 存储>关系型数据库)
AMQP 概论是应用层协议的一个开放标准,为面向消息的中间件设计。基于此协议的客户端与消息中间件可传递消息,并不受客户端/中间件不同产品,不同的开发语言等条件的限制。目标是实现一种在全行业广泛使用的标准消息中间件技术,以便降低企业和系统集成的开销,并且向大众提供工业级的集成服务。
主要实现有 RabbitMQ。
客户端与 RabbitMQ 的通讯连接首先作为客户端(无论是生产者还是消费者),你如果要与 RabbitMQ 通讯的话,你们之间必须创建一条 TCP 连接,当然同时建立连接后,客户端还必须发送一条“问候语”让彼此知道我们都是符合 AMQP 的语言的,比如你跟别人打招呼一般会说“你好!”,你跟国外的美女一般会说“hello!”一样。你们确认好“语言”之后,就相当于客户端和 RabbitMQ 通过“认证”了。你们之间可以创建一条 AMQP 的信道。
信道概念:信道是生产者/消费者与 RabbitMQ 通信的渠道。信道是建立在 TCP 连接上的虚拟连接,什么意思呢?就是说 rabbitmq 在一条 TCP 上建立成百上千个信道来达到多个线程处理,这个 TCP 被多个线程共享,每个线程对应一个信道,信道在 RabbitMQ 都有唯一的 ID ,保证了信道私有性,对应上唯一的线程使用。
疑问:为什么不建立多个 TCP 连接呢?原因是 rabbit 保证性能,系统为每个线程开辟一个 TCP 是非常消耗性能,每秒成百上千的建立销毁 TCP 会严重消耗系统。所以 rabbitmq 选择建立多个信道(建立在 tcp 的虚拟连接)连接到 rabbit 上。
从技术上讲,这被称之为“多路复用”,对于执行多个任务的多线程或者异步应用程序来说,它非常有用。
RabbitMQ 中使用 AMQP生产者、消费者、消息
生产者: 消息的创建者,发送到 rabbitmq;
消费者:连接到 rabbitmq,订阅到队列上,消费消息,持续订阅(basicConsumer)和单条订阅(basicGet).
消息 :包含有效载荷和标签,有效载荷指要传输的数据,,标签描述了有效载荷,并且 rabbitmq 用它来决定谁获得消息,消费者只能拿到有效载荷,并不知道生产者是谁。
交换器、队列、绑定、路由键
队列通过路由键(routing key,某种确定的规则)绑定到交换器,生产者将消息发布到交换器,交换器根据绑定的路由键将消息路由到特定队列,然后由订阅这个队列的消费者进行接收。(routing_key 和 绑定键 binding_key 的最大长度是 255 个字节)
消息的确认消费者收到的每一条消息都必须进行确认(自动确认和自行确认)。
消费者在声明队列时,可以指定 autoAck 参数,当 autoAck=false 时,RabbitMQ 会等待消费者显式发回 ack 信号后才从内存(和磁盘,如果是持久化消息的话)中移去消息。否则,RabbitMQ 会在队列中消息被消费后立即删除它。
采用消息确认机制后,只要令 autoAck=false,消费者就有足够的时间处理消息(任务),不用担心处理消息过程中消费者进程挂掉后消息丢失的问题,因为 RabbitMQ 会一直持有消息直到消费者显式调用 basicAck 为止。
当 autoAck=false 时,对于 RabbitMQ 服务器端而言,队列中的消息分成了两部分:一部分是等待投递给消费者的消息;一部分是已经投递给消费者,但是还没有收到消费者 ack 信号的消息。如果服务器端一直没有收到消费者的 ack 信号,并且消费此消息的消费者已经断开连接,则服务器端会安排该消息重新进入队列,等待投递给下一个消费者(也可能还是原来的那个消费者)。
RabbitMQ 不会为未 ack 的消息设置超时时间,它判断此消息是否需要重新投递给消费者的唯一依据是消费该消息的消费者连接是否已经断开。这么设计的原因是 RabbitMQ 允许消费者消费一条消息的时间可以很久很久。
常见问题如果消息达到无人订阅的队列会怎么办?消息会一直在队列中等待,RabbitMq 默认队列是无限长度的。
多个消费者订阅到同一队列怎么办?消息以循环的方式发送给消费者,每个消息只会发送给一个消费者。
消息路由到了不存在的队列怎么办?一般情况下,凉拌,RabbitMq 会忽略,当这个消息不存在,也就是这消息丢了。
交换器类型共有四种 direct,fanout,topic,headers,其中headers(几乎和 direct 一样)不实用,可以忽略。
Direct
路由键完全匹配,消息被投递到对应的队列, direct 交换器是默认交换器。声明一个队列时,会自动绑定到默认交换器,并且以队列名称作为路由键:channel->basic_public($msg,’’,’queue-name’)

Fanout
消息广播到绑定的队列,不管队列绑定了什么路由键,消息经过交换器,每个队列都有一份。

Topic
通过使用“*”和“#”通配符进行处理,使来自不同源头的消息到达同一个队列,”.”将路由键分为了几个标识符,“*”匹配 1 个,“#”匹配一个或多个。

【记得点个赞哦】
相信技术改变生活
