
阿里妹导读
笔者结合实践经验以近期在负责的复杂表格智能问答为切入点,结合大模型的哲学三问(“是谁、从哪里来、到哪里去”),穿插阐述自己对大模型的一些理解与判断,以及面向公共云LLM的建设模式思考,并分享软件设计+模型算法结合的一些研发实践经验。
一、前言
2022年11月,ChatGPT平地一声雷,开启了“大模型+”时代,为整个AI软件市场带来了无限商机,据ARK Invest的首席未来学家Brett Winton预测,到2030年左右,AI软件市场的市场总值将达到13万亿美元(当前,全球IT支出为4+万亿美元),其中生成式AI的市场总值将达到1.3万亿美元左右,是2022年(400亿美元)的32+倍,而近期Gartner发布了2024中国基础设施战略技术成熟度曲线,清楚地表明,未来2-5年生成式AI依然处于期望膨胀期,可见,其潜力之巨大。

图片来源网络
正因为如此,国内外的大模型创业公司,如雨后春笋般涌现,都在探索着大模型的PMF(Product Market Fit)新机会,主要有2大方向,一个是基础模型的迭代(如GPT3.5 到 GPT4),不断迭代通用的泛化能力,其理想态是AGI(Artificial General Intelligence),不过,Scaling Law所需的大数据、大算力,需要耗费巨大的资金投入,让众多初创公司望而却步。
另一个方向就是大模型创新应用,以新技术驱动产品形态,基于新技术的阶段性发展,快速迭代升级产品,并最大化技术在产品中的价值,当前还处于产业发展的早期,而从实现路径上看,面向生产力的大模型场景应用更有可能找到PMF落地,比如知识问答场景。
在过去的一年多,笔者有幸与多个团队深度合作共创,并成功落地了多个大模型的场景建设,比如,刚结束不久的国际奥运大模型、公文写作大模型、安保数字孪生智能体等,而目前主要专注于公共云汽车能源领域的大模型场景,其中,让笔者感触最深的是,软件设计与模型算法的有机结合,是系统成功构建的关键因素之一。
本文,笔者结合实践经验,期望以近期在负责的复杂表格智能问答为切入点,结合大模型的哲学三问(“是谁、从哪里来、到哪里去”),穿插阐述我对大模型的一些理解与判断,以及面向公共云LLM的建设模式思考,并分享软件设计+模型算法结合的一些研发实践经验。
二、背景
在汽车领域,汽车厂商旗下通常会有多个子品牌,不同品牌下通常会有多款车型。面对众多车型,汽车厂商在服务于车主的过程中,长期以来产生了大量的碎片知识,如汽车延长保修、汽车保养等,散落在各种文档中,常见之一就是表格文档(xlsx)。
以汽车保养的表格场景为例,一般我们对表格的认知是,诸如数据报表、统计表等这类结构化的表格,而此次的汽车保养表格则是复杂得多。一份汽车保养表格中,同时包含了结构化和非结构化的内容,涵盖了汽车保养类别、保养条目、保养的价格、以及一些保养的政策等,内容多样且杂糅。
这类场景的咨询服务,效果不佳且效率非常低下。因此,如何整合这些碎片知识的复杂表格文档,构建智能问答系统,从而为车主提供可用、精准、人性化的问答服务,显得尤为重要。
三、场景分析
显然,汽车保养场景属于问答场景,而智能问答系统的构建,目前最耳熟能详的,当属基于知识库的检索增强生成(RAG)方案,也是大模型被高频使用的场景之一。其通用做法是,基于百炼平台构建知识库,选择大模型,搭建RAG智能体,再加Prompt调优,从而一个智能问答系统就建成了,非常高效。因为百炼的RAG链路本身已经做了很多工程优化工作,加之大模型自身的推理能力,其问答效果会得到一个还可以的性能结果。
而这能满足很多场景下的日常使用(不需要精准度很高的情形),以至于给人以错觉,这就是大模型的最好表现了,这种能work就算ok了,属于60分的逻辑,其往往忽略了背后的思考和作为建设者的最终目标。笔者认为,作为大模型场景建设落地者,最大化挖掘大模型能力,并优化大型语言模型的工作流程,最终为客户带来极致的技术体验,是我们的技术服务核心目标,这里体现的不仅是一种技术服务思维,更体现了一种研发思维,而研发思维是研发能力的抽象,其呈现的是匠工精神。
如背景说述,尽管汽车保养的表格复杂、数据多样、杂糅,且格式不统一,但是,从技术实现路线上可以大致分为4类,如图所示,其中阿里云产品泛指未集成到百炼平台的其他阿里云产品。技术路线1,基于百炼平台构建问答系统,其标准化程度高,试错成本、人力投入较低。而越往后,标准化程度越低、人力和试错成本越高。而项目过程中,我们需要快速搭建、快速验证、不断调优,快速试错。由此可见,我们得出一个实施原则,面向公共云业务,最大化标准(用好阿里云百炼)、最小化做定开。

基于这一实施原则,抽象出两大核心:模型、平台,而围绕模型开展的工作,又一定绕不开Agent和Prompt,因此,笔者将其定义为“两大核心、四大要素”,即,以模型、平台为核心,以大模型、百炼平台、Agent、Prompt为四大要素,构建高效、可用的大模型系统实现场景落地。可见,对四大要素理解的深度和广度,将直接影响到构建系统的最终效果,也就是前面提及的最大化模型效果。因此,接下来,笔者将优先阐述下对这四大要素的一些原理和思考。
四、要素1:大模型——技术驱动产品
1、大模型架构——Decoder-Only Transformer
AI领域有3个技术流派,分别是符号主义、连接主义以及行为主义,其中,连接主义强调的是模仿人脑的神经元结构,通过大量的神经元相互连接来处理信息,从而实现人工智能。大语言模型(LLM),通常指的是具有大量参数的深度神经网络模型,因此,追根溯源,大语言模型属于3大流派中的连接主义流派。其神经网络架构,采用的是Transformer架构。
原生Transformer架构中, Encoder(编码器)、Decoder(解码器)是其重要组成部分。Encoder指的是将输入序列编码为特征向量,Decoder指的是根据编码器的输出以及先前生成的序列生成下一个单词(符号)。而基于Transformer架构的LLM,根据编/解码器的组合方式不同,产生了三种不同模式,即Encoder-Only模式、Decoder-Only模式、以及Encoder-Decoder模式,且这三种模式都有不同程度的发展(如下图所示)。

图片来源网络
可以看出,Decoder-Only Transformer的LLM发展最为迅速、最为耀眼,已成业界主流。其主要原因在于,相比于其他两种模式,Decoder-Only模式允许模型通过给定的前文,以自回归方式进行文本生成,即迭代式地将已预测的词加入到先前输入序列中,以继续预测下一个词,从而使得模型更简单、更专注,且在预测下一个词时计算效率更高。
Decoder-Only Transformer架构,如下图所示,相比于原生Transformer,Decoder-only架构省略了Encoder部分,将用户query直接传递给解码器进行处理。其推理过程分为 2 个阶段,Prefill阶段、Decode阶段。
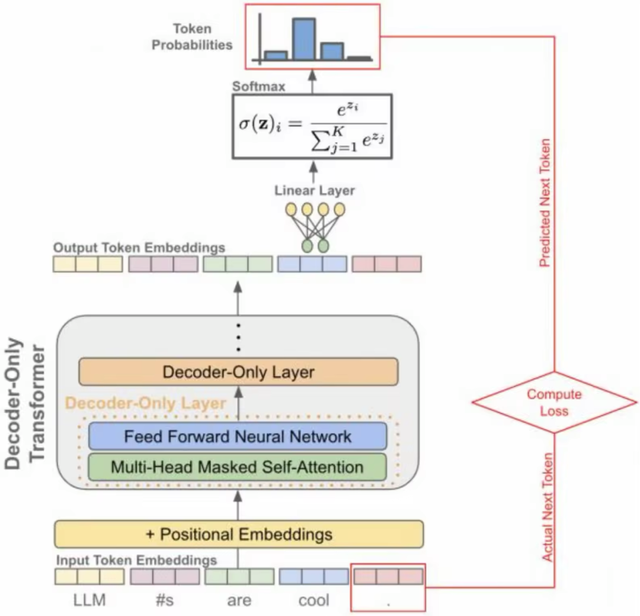
图片来源网络
Prefill阶段为计算密集型,是用户输入完query到生成首个token的过程,LLM处理输入token以计算中间状态(Key-Value),这些状态用于生成第一个新token,如下图所示。由于输入的内容已知,且不同token的Key-Value计算是独立的,因此,从高纬度看,这是一种高度并行化的矩阵-矩阵操作(matrix-matrix operation),GPU利用率较高。
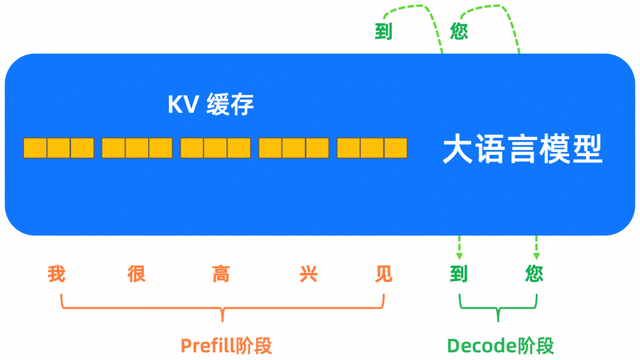
Decode阶段为访存密集型,LLM自回归地一次生成一个输出token,直到满足停止条件。过程中,每个顺序输出token需要频繁地在 HBM 和 SDRAM 中访问数据,获取之前所有迭代的输出状态(Key-Value),所以无法有效利用GPU的并行计算特长,GPU利用率不足,进而导致了输出阶段成本高。这也是为何大模型的输出价格一般高于输入价格的原因。
2、大模型的“变”与“不变”思考
回顾历年政府工作报告,从2015年提出的“互联网+”到2019年提出的“智能+”,它们在不同阶段推动了产业的转型升级。而今年政府工作报告更是首次提出了“人工智能+”,AI被提升到了前所未有的高度,也意味着从“互联网+”、“智能+”到“人工智能+”的转变。而把“人工智能+”具象化地看,笔者认为,我们正在经历的是“大模型+”的时代。

大模型、大数据、大算力这三驾马车的系统性已经成型,且在快速地产生化学反应,加速地驱动着各个产业升级,如大模型+汽车交通、大模型+教育、大模型+互联网、大模型+能源等。然而,“大模型+”时代下,从服务于千行百业的场景落地角度看,笔者一直在思考的是什么是“变”的、什么又是“不变”的,来确保对客户服务的技术判断力和技术服务的领先力。有以下几个观点,与大家做下分享:
2.1 大模型的“变”现在业界普遍都认为,AI技术的发展变化飞快,而且这种变化还在加速。其核心可以从两个纬度来看。
纵深上看,大模型的推理能力不断增强,正在从系统1思维(即快速、直觉、自动、易出错的思维模式)朝着系统2思维(即刻意、缓慢、有意识且更可靠的推理)进化与演进。比如刚发布不久的OpenAI o1,第一次证明了LLM具有慢思考能力,虽然o1并未公布其实现原理,但是业界给出了诸多技术原理猜想,较为一致的观点是,o1通过RL(强化学习)及MCTS(蒙特卡洛树搜索),将CoT(思维链)能力内化进LLM中,并运用强大的算力实现了Post-Training 阶段的Scaling。笔者在【前言】中提到,大模型的发展方向之一是基模的迭代并朝着AGI演进(演进路线为模拟世界、探索世界、归纳世界),而归纳世界的前提就是大模型具备系统2的能力,可见,我们正在加速AGI方向探索。
横向上看,基于Transformer的NLP领域Scaling Law有效性已经得到证明,而将该定律扩展到机器视觉、语言处理领域,并形成多模态融合,正在深度探索并取得了明显进展,比如GPT-4o把视觉理解模型 GPT-4v、视觉生成模型 DALL-E、Sora以及有声模型 Whisper、Voice Engine融合在了一起,从而更真实地感知与理解物理世界。而在场景建设方向,“大模型+”的链接能力也在不断被突破,如大模型+终端设备连接,大模型+智能控制等,丰富了大模型的“行为”能力,进而给具生智能装上“大脑”,让具生智能更具想象空间和可落地性。
2.2 大模型的“不变”贝索斯曾说过,“大家经常会问未来10年,会有什么样的变化?但很少有关心,未来十年什么是不变的?我认为第二个问题比第一个问题更重要。”笔者的理解是,定义清楚了什么是“不变”的,形成抓手并迁移,才可能不断从“变”中,抽象出“不变”并形成内化。更具体地说,就是面向大模型场景建设,不断挖掘其共性化建设,并形成标准化能力,从而应对千行百业中不断涌现的新场景、新变化。
笔者认为,面向公共云业务场景的建设模式已经显现,即如下图所示,类似于Linux系统架构,以大模型能力为内核,分层解耦形成对外服务能力,面向场景可组装平台化的大模型应用构建模式。通过三层软件架构,快速构建轻量级应用,实现高内聚、低耦合、变化隔离;通过平台化组装,实现多应用的“积木”组合,从而输出场景化解决方案。因此,无论大模型如何“变”,对外提供能量的接口层隔离了该变化,从而使得应用架构相对稳定。

我们知道,深度学习的思想是分层,通过多层叠加的方式,实现了对数据的分级表达,而大模型的核心正是通过这种纵向的层次堆叠,形成了Scaling Law。而对于业务,通过组装方式横向“堆叠”应用,是否也能形成“堆叠”效应,进而产生强大生命力呢?我想是一件非常值得期待的事情。
五、要素2:百炼——可组装式,所“建”即所得
百炼,作为阿里云大模型服务平台,服务于千行百业的大模型场景建设,其平台可用性、易用性至关重要。而作为资深用户,笔者不仅见证了百炼的快速成长并逐步走向优秀,更欣喜地看到了,今年5月份2.0版本的发布。

该版本不仅深度践行了“一切皆智能体”的理念,更凸显了模型中心、应用中心、以及数据中心这3大核心板块的有机联动,易用性取得了前所未有的提升,很大程度上满足了常规功能的大模型应用搭建。如上图所示,面向最高频使用的应用构建,百炼提供了3种构建模式,包括智能体、工作流、多智能体,其本质就是模块化、可组装化。
可组装化技术,强调的是系统架构层面,是对已有技术的再组合和用法创新,注重系统从构建到演化的过程,如何以可组装的方式增强提升系统的韧性和快速适应性。
正如Gartner 研究副总裁David所说,可组装方法,让系统能力变得可沉淀、可组合复用、可灵活应对各种变化,在新功能的实现速度上将比竞争对手快80%。笔者给多家企业(累计培训人数300+)做百炼平台培训,很多学员不仅能快速上手百炼,而且分钟级搭建完成RAG应用系统并使用,所“建”即所得。
六、要素3:智能体——大模型落地的关键载体
1、单智能体
早在20世纪50、60年代,诺伯特·维纳在《控制论》中就有对智能体概念进行讨论。而随着深度神经网络的快速发展,尤其是大模型技术的爆发,基于LLM的智能体被广为人知,其定义也逐步清晰、具象化。
智能体,是一种高效、智能的代理,能感知环境、解释数据、做出决策,并执行动作以实现预定的目标。其架构如下图所示,包含规划、记忆、工具、执行四大要素。通过将大模型嵌入到智能体中,可以更好地将模型的能力应用于实际场景。它为智能体提供了强大的推理能力,解释指令和上下文,使其能够更好地利用各种工具,诸如API、搜索引擎等,实现(半)自主运作。
著名AI科学家吴恩达做过一项小型研究,结果表明,在编写代码的标准编码基准测试中,GPT-3.5 智能体,效果上比 GPT-4 表现更好。笔者认为,智能体已然成为大模型落地的关键载体,而大模型与智能体的有机结合,有助于提升整个场景落地的效果。

2、多智能体
在软件领域,“分而治之”是一种常用的设计和开发理念,而在大模型场景中也同样适用。面向复杂任务场景,多智能体方法会将复杂任务分解为子任务,让不同的智能体完成不同的子任务,即专业“人”做专业“事”。AutoGen论文中的消融研究显示,相比于单智能体,通过对复杂任务分解而构建的多智能体,其协作的表现更优。
因为,拆解任务有助于降低单个大模型的输入复杂度以及理解难度,从而有利于大模型专注于“做”一件事情,其性能可能会更好。类比我们自身,在被洋洋洒洒地告知要处理10件事情,一次性要理解几千字的信息,与把这10件事情分开说、分开做,哪种做法更能做好做准确呢?其结果不言而喻。而笔者针对复杂表格所设计实现的方案正是基于这一思路。
七、要素4:Prompt——LLM与应用的“桥梁”

LLM的高速发展,为NLP带来了新的范式(如上图所示),即预训练+微调+Prompt范式。其中,预训练,是 LLM的基石,通过海量无标注语料,对大模型进行自监督学习,从而让大模型具备了通用语言理解和生成能力,解决的是领域(Domain)能力问题;而微调,解决的是某一任务(Task)问题,利用标注的任务数据,对预训练过的模型做进一步的优化,从而更好地适应某一Task,然而存在过拟合、灾难性遗忘等风险。不过,这两者有一个共性,就是都会改变模型的参数。
相反,提示词工程(Prompt Engineer,PE)无需更改模型参数,而是通过构建合理的Prompt,激发大模型中蕴含的知识、引导其行为,从而生成高质量的结果。PE最大的优势在于高效、灵活、成本低,而且避免了微调可能带来的问题。正因为如此,傅盛在极客公园演讲曾表示,如果创业者只学习大模型的一个技术点, 那就是Prompt。事实上,这也是我们场景落地过程中,使用最多的调优手段。
提示词工程,是一种经验科学,其效果在不同的模型之间可能会有较大差异,但方法层面具有通用性,下面介绍一些笔者在实践中高频使用的方法:
1、Few-Shot CoT,提供示例,在询问问题的时候,给出示例能够显著提升模型输出效果,尤其是针对格式上有要求的情况;
2、指定角色或人格,从而能够回答得更加专业。比如,当我们直接问一个问题时,模型可能会很泛地回答,然而,当我们指定角色的时候,大模型能够根据训练时角色资料,给出更加具象化的回复;
3、还有一些小技巧,如,先思考后回答、重要的信息放提示词后面、指定模型如何格式化响应等。
八、可行性方案设计——多方案探索
正如【场景分析】一节中指出的,复杂表格的智能问答场景,属于大模型RAG应用范畴。而大模型RAG的基本原理,正如ACA课程所介绍的,如下图所示,主要分为2个阶段,即:
建立索引:首先要清洗和提取原始数据,将PDF、Docx等不同格式的文件解析为纯文本数据;然后将文本数据分割成更小的片段(chunk);最后将这些片段经过嵌入模型转换成向量数据(此过程叫做embedding),并将原始语料块和嵌入向量以键值对形式存储到向量数据库中,以便进行后续快速且频繁的搜索。
检索生成:系统会获取到用户输入,随后计算出用户的问题与向量数据库中的文档块之间的相似度,选择相似度最高的K个文档块作为回答当前问题的知识。知识与问题会合并到提示词模板中提交给大模型,大模型给出回复。
而在实际使用中,为了获得更好的模型性能,会在原始的RAG基础上,增加诸如混合检索、Rerank等模块化能力,其中混合检索有两种形态,术语检索(即稀疏检索)以及语义检索(即密集检索)。

因此,根据【场景分析】中提出的实施原则,笔者优先选择技术路线1、2,即优先基于百炼、百炼+阿里云产品,标准化能力构建,并验证其可行性。经过调研,探索出了3种可行性方案:
方案1:百炼平台标准RAG
按照百炼平台RAG的搭建,第一步需要导入文档源,做文档解析,其中,导入的复杂表格文档中,既有表格也有较长文段等,导致,提交上传到百炼平台后进行解析出现报错。
其原因为对于格式为xlsx的文档,数据类型要求是结构化类型,而我们上传的复杂表格,既有结构化数据、也有非结构化数据,因此解析失败。可见,方案1走不通,无法满足该项目场景。
方案2:基于通义千问VL-Max的多模态RAG
由于复杂表格数据格式不统一、多样化、且数据杂糅,传统的文档解析经过尝试均无法满足,而基于多模态大模型的视觉感知,不仅能有效提取图片文字信息而且能做有效推理和生成,因此,考虑基于多模态大模型千问VL进行可行性测试。
方案的整体思路,将数据excel全部转为图片格式,然后调用基于QwenVL Max构建的多模态RAG。其中,基模的视觉识别能力对整个方案起着至关重要的作用,因此,优先基于QwenVL Max进行测试其效果。经过实际验证,该模型能准确理解并给出正确回答,技术上看起来可行,但其存在明显的弊端:
1)文档的预处理繁琐,需要人工将所有文档,以一定方式截图且不能存在文字遮挡情形(这点很难保证),其随着文档数量增多,人工成本陡增;
2)多模态大模型其调用费用较高,随着调用的次数增多,所需支付的费用持续加剧;
3)当截图量级不断增加时,一次性全部输入给到通义千问VL- MAX显然不现实。
方案3:文档解析(大模型版)+百炼的组合RAG
回顾方案1,最大的卡点问题是文档为xlsx格式但数据类型为非结构化,导致无法解析。进一步考虑,是否可以寻求具备该能力的阿里云产品,解决该excel文档解析问题,而一旦能打通,则后续便可以复用百炼RAG标准化能力,从而最小化定制、最大化复用地支撑该项目的快速实现(即技术路线2)。因此,方案3应运而生。
方案的整体思路:
1)问答解析,基于阿里云产品文档智能的文档解析(大模型版)调用其文档解析接口实现文档抽取和理解,从文档中提取出文本markdown内容;
2)知识构建,将markdown内容导入百炼数据管理做解析,以及做数据向量化(embedding),构建知识库;
3)基于百炼应用模版构建RAG,并关联该知识库,生成智能问答应用实例;
4)基于该智能问答应用,做知识QA。
相比于其他2种方案,方案3标准化程度最高,实施上更轻量,且效果经过初步验证更优。因此,可行性方案采用的是方案3。
可行性效果评测
基于方案3快速搭建的最小应用系统,根据实际测试样例进行批量测试,准确率为51.2%。其结果表明,从可行性方案上,证明方案3的技术有效性,但从效果上,准确率较低,无法满足实际使用落地。
九、可落地方案实现——多智能体架构
1、难点分析
在可行性阶段,探索并验证了方案三(文档解析(大模型版)+百炼的组合RAG)的技术可行性,效果上需要优化。在【Prompt】一节中提到了围绕大模型效果优化的3大方向,预训练、微调、PE,而PE是最高性价比的调优手段。因此,笔者的第一个直觉也是调Prompt,效果确实也有提升,但是并不显著。事实上,经过深入分析,究其原因有3:
1)数据层面:(a)保养表格内容涵盖多种类、数据杂糅;(b)价格费用计算复杂,需要4维条件才能锁定一个价格;(c)数据中有脏数据,比如,如下图所示,表头里程(公里)一列显示的却是车型。
而方案3对数据的处理非常朴素,就是文档解析后构建一个知识库,这其中存在2个问题,数据质量不高,数据相互耦合(形成数据噪声)。
2)问题多样化:用户提问的保养问题较为多样化,比如,询问保养价格类、保养项目类、保养政策类等,而方案3通过单Agent+Prompt调优的方式构建问答能力,这导致的最大问题就是,Prompt指令的复杂度陡增。
而大模型产生幻觉的主要来源之一,就是过于复杂或宽泛的Prompt。从信息学的角度来说,引入了更多的不确定性,增加了输入的信息熵。
3)精准类问题的推理难度大:保养价格类问题,属于精准类问题,原则上不允许大模型回答出错,而对于这类问题,如上表格所示,涉及到车型(含上市时间计算)、里程计算、地区推算、以及费用计算等才能得出最终的保养价格费用,属于高维度的计算推理。
经过实测,大模型的表现并不理想,且带有随机性,这是因为LLM是基于已知输入预测下一个Token的过程,本质上就是概率计算。
2、解决思路
1)RAG方案中,知识库数据往往优于大模型自己具备的知识,即,知识库数据质量在一定程度上决定了大模型的效果上限,因此,高质量知识至关重要。针对问题1,进行适度的数据清洗、数据分类非常有必要;
2)正如在【智能体】一节中提到的“相比于单智能体,通过对复杂任务分解而构建的多智能体,其协作的表现更优”。因此, 针对问题2,我们需要对任务进行分类和拆解,从而构建业务垂直化的Agent,并形成多智能体架构;其设计,符合软件设计原则中的“职责单一化”原则,以及“高内聚、低耦合”原则;
3)针对问题3,尽管大模型的推理能力在不断加强,但眼下还是需要通过一些工程化手段来改善。为此,笔者的思路是,针对精准类问题的解法是,构建Serverless价格查询服务,并通过函数计算(FC)下沉到自定义插件中,这样既能充分发挥大模型的推理能力,又能通过插件化调用提升精准度,且价格数据实现了在线化,可管控性更强。
3、方案架构
综合上述3种解决思路,设计并最终形成了如下的方案架构,其设计的核心原则是分而治之,封装垂类Agent,横向组装API。分层来看,首先基于大模型服务工具,进行数据处理、数据分类等工作,其次通过百炼平台进行垂类Agent构建,最后,通过百炼API进行多智能体编排组装,且Router Agent做路由。

4、工程链路
整个方案的工程链路建设,主要分为离线阶段和在线阶段两部分:
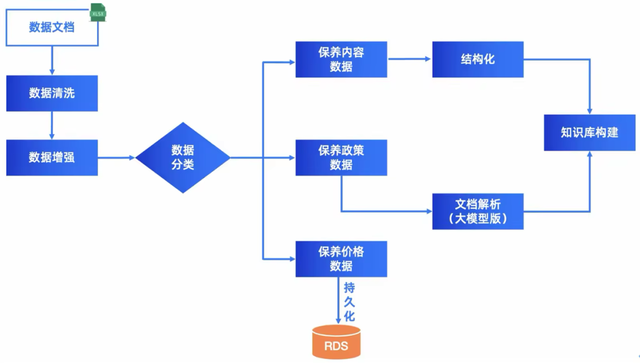
1)离线阶段:数据处理&知识库构建流程,如下所示:
2)在线阶段:Query路由与检索增强的工程链路,如下所示:

接下来,针对链路的关键模块进行简要阐述:
4.1数据工程——Better Input Better Output数据处理环节,主要是对表格数据中有错误、有重复、格式错误等情况进行优化,并对表格中的合并单元格进行分行处理等,随后做数据分类,将保养内容进行抽取,并形成结构化数据,构建保养内容知识库;将保养政策进行抽取,通过文档解析(大模型版)进行解析为MD数据,并通过百炼构建保养政策知识库。将保养价格数据进行抽取,并通过Coding实现RDS持久化,并对外提供数据查询服务,以及通过函数计算(FC)实现Severless调用。最终,数据质量得到大幅度提升。
4.2车型改写
车型改写的目的在于,车主提问的方式是开放式的,比如“16年xx在北京,里程5000公里,保养需要多少钱?”xx车型有多款,且每一款的上市时间各有不同,这时候就需要通过车型改写Agent,进行改写,并输出完整的车型。
其Prompt如下所示:
#角色你是一位问题改写专家,善于根据历史对话做问题改写,并调用【车型匹配插件】做二次改写,以及问题分类。#技能,严格按照以下步骤执行**步骤1**:需要根据用户问题和历史对话,进行问题改写;**步骤2**:根据步骤1改写后的问题,如果提到车型,则提取到【车型】;如果提到时间,则提取到【时间】;否则,则不提取对应字段。**步骤3**:如果【车型】,则务必调用【车型匹配插件】,【车型】、【时间】(如果不为空)作为入参,获取匹配后的【车型全称】;**步骤4**:基于步骤3返回的结果,【车型全称】信息,对步骤1执行后的问题做二次改写;(只改写,不回答其他内容和思考过程)**步骤5**:根据改写后的问题,判断属于哪类问题。问题类别列表:保养价格类、保养内容类、保养政策类、其他类。#约束**严格遵循**:务必根据技能步骤执行,如果技能中**步骤3**【车型匹配插件】被执行,则务必按照**步骤4**进行改写。#输出格式,以json格式输出,样例:"""{"用户问题":"xx,5万公里,北京保养需要多少钱?",“提取的车型”:“xx”,“插件返回车型”:“xx2.0L”,"改写后问题":"xx2.0L,5万公里,北京保养需要多少钱","问题类型":"价格类"}"""4.3意图识别
在完成多轮对话增强(带历史对话功能),做车型改写的同时,系统会进一步对问题进行意图识别,即理解用户真正的需求。意图识别是智能问答系统的关键部分,它决定了系统是否能够精确匹配用户的需求,确保了后端链路的精准路由。如,用户问“在成都保养单价需要多少钱?”,这时通过意图识别,则会精准路由到保养价格Agent链路。
4.4文档解析笔者主要利用的是文档智能产品的文档解析(大模型版)能力,实现了基于文档解析的API接口,由xlsx文档转化为markdown的在线功能,主流程如下所示:
#复杂表格解析主流程def process_file(file_path): #1、获取client client = get_cred_client() print(f"file_path:{file_path}") #2、提交复杂表格文件 id = submit_file(client,file_path) while True: #3、根据文件id,查询状态 status = query(client,id) if(status == "success"): break time.sleep(1) #4、根据返回结果,获取解析后的数据,并存入md文件 get_parser_result(client,id)4.5函数计算函数计算是一个事件驱动的全托管 Serverless 计算服务。而我们开发的价格计算插件、车型插件都属于无状态服务,非常适合采用这种函数计算方式。只需将代码编写完成并上传即可,无需管理服务器等基础设施,充分体现了Serverless的极简运维,减少业务发布和扩容运维时间,降低用户业务构建门槛,降低用户保有资源的成本。
5、效果
在测试评估阶段,笔者根据实际样例集进行测评,其部分结果如下所示:
保养内容类样例,经过多智能体问答系统,能正确输出保养内容的相关信息。

保养价格样例,则准确给出对于车型的保养费用,且总费用、零件费用、工时价格,与表格数据完全一致。

经过批量测试,效果准确率达到93.8%,相比于可行性方案,效果显著提升,如下图所示:

十、总结
本文以汽车保养复杂表格的智能问答为切入点,系统地阐述了:
1、从哲学三问(“是谁、从哪里来、到哪里去”)的视角,思考并分享了对LLM的理解,包括LLL所属的连接主义流派、Decoder-Only Transformer架构、以及从纵深、横向两个纬度的“变”。从“变”中寻找到“不变”,即以大模型能力为内核,分层解耦形成对外服务能力,面向场景可组装平台化的大模型应用构建模式,从而以“不变”应万“变”。
2、面向公共云大模型建设,定义了“两大核心、四大要素”,以及“最大化标准、最小化做定开” 的实施原则,有利于降低人力和试错成本,从而实现快速搭建、快速验证、不断调优,快速试错的大模型场景落地。
3、在深度剖析复杂表格的基础上,从可行性到可落地性两个阶段,设计出了多种解决方案及其验证,最终采用并实现了多智能体+价格插件(FC)的解决方案。经过实际样例集测试评估,准确率达到93.8%,达到并超出了预期。
笔者认为,LLM哲学三问的思考,有利于帮助初探大模型的同学们,串联知识碎片,系统性理解大模型;而“两大核心、四大要素”,以及“最大化标准、最小化做定开”的实施原则,为大模型场景落地的同学们,提供了具有实践价值的参考建议;最后,本文阐述的复杂表格多智能体方案及其经验,不局限于汽车保养场景,具有一定通用性,对其他行业有类似场景诉求的同学们,同样具有借鉴意义。
团队:公共云业务-技术服务部
参考:[1] https://arxiv.org/pdf/2204.05832v1
[2] https://edu.aliyun.com/course/3126500/lesson/342570338
[3] https://arxiv.org/abs/2307.07924
[4] https://arxiv.org/abs/2308.08155
[5] https://www.deeplearning.ai/the-batch/how-agents-can-improve-llm-performance/
[6] https://www.deeplearning.ai/the-batch/agentic-design-patterns-part-2-reflection/
[7] https://www.deeplearning.ai/the-batch/agentic-design-patterns-part-3-tool-use/
[8] https://www.deeplearning.ai/the-batch/agentic-design-patterns-part-4-planning/
[9] https://wallstreetcn.com/articles/3690180
[10] https://www.gatesnotes.com/Technology/Future-of-AI-Agents
