
因为业务需要,笔者有幸参与设计和开发了涉及数十亿量级的图片素材调度、处理和索引使用的平台-产业AI素材库,在平台的建设落地过程中,踩了许多坑,也有了一些工程落地上的实践总结,希望分享给大家。

导入实践总结
素材库建设之初,涉及的图片素材单次导入不过百万,不过随着算法侧针对图片素材训练的模型的“胃口”急速增长,单次图片素材导入的需求直接突破到了数十亿级。在实践中发现,最开始完全借助于dataworks平台节点调度能力的那套架构,面对如此海量的数据导入已经捉襟见肘:数据的导入和处理已无法在24小时内完成,甚至超过一周(超过24小时会触发dataworks session 超时的异常),成为了图片素材快速投入训练和使用的阻碍。于是,我们重新设计了一套导入链路,以解决这个问题。简化的导入框架设计如下:
 ▐1. 使用聚簇表提高处理并行效率
▐1. 使用聚簇表提高处理并行效率clustered by | range clustered by (<col_name> [, <col_name>, ...])
[sorted by (<col_name> [asc | desc] [, <col_name> [asc | desc] ...])] into <number_of_buckets> buckets:可选。用于创建聚簇表时设置表的Shuffle和Sort属性。
在调研odps表的时候,发现其提供了在创表时候指定聚簇列从而提高并行效率的能力,其语法如上。其分为【Hash聚簇表】和【range聚簇表】,以Hash聚簇表为例,MaxCompute将对指定列进行Hash运算,按照Hash值分散到各个Bucket中。对于join优化场景,要求两个表的哈希桶数目成倍数关系,例如256和512。建议哈希桶的数量统一使用2n,例如512、1024、2048或4096,这样系统可以自动进行哈希桶的分裂和合并,提升执行效率。
需要注意的是,若想使用聚簇表提升并行速度,实践中发现,需要保证数据的源表和输入表都是聚簇表,且最好采用统一的分桶数目和分桶策略。
▐2. 使用数据分片提高并行及容错率一次亿级图片素材的导入,即使使用了聚簇表,导入效率仍然会退化到难以接受的程度,且中途某个处理节点的失败,将会导致整个工作流的失败,重新发起导入将会是一个巨大的成本。所以在聚簇表的基础上,我们引入了分片机制:通过一定的算法,将整个导入工作拆分为多个分片执行,每个分片保证处理的图片不超过千万。这样带来的明显好处有:
大大增加导入工作的容错,当任务出错的时候,只需要重跑出错分片即可;极高的利用了机器资源同时并行多个分片,且这个并行度是可控的;增加了对于任务更细粒度的控制。以下是我们一次1.5亿图片素材导入的工作流截图,可以看到1.5亿的图片素材被分为了38个分片进行执行,每个分片处理的素材量级只是百万级,处理完成只需要小时级的时间:
 ▐3. 关于图片key生成算法的抉择
▐3. 关于图片key生成算法的抉择关于图片key,我们基于自己的场景有如下诉求:
对于一张图片,其key应该具有全局唯一性。在极低概率的前提下,接受生成key的碰撞(即对于不同的图片,产生了同一个key)。对于key的生成方案,我们也做了如下的调研(一些代码实现见附录1):
方法
简介
优点
缺陷
感知哈希算法(perceptualhash algorithm)
使用离散余弦变换(DCT)对图片进行降噪等进行预处理,再提取其图片特征,生成一个key
1.不受图片大小缩放影响,只要图片的整体结构保持不变,hash结果值就不变。
2.能够避免伽马校正或颜色直方图被调整带来的影响。
3.可基于hash值的汉明距离计算图片的相似度。
1.有一定的计算开销。
2.因为是对图片进行收缩计算,收缩的小,信息丢失少但是hash值变长且计算开销指数增长;若收缩的大,信息丢失大,碰撞概率急剧增加。
均值哈希算法(Average hash algorithm)
通过对图片灰度均值比较,生成一组图片指纹。
1.计算简单,只需计算图像的平均灰度值并进行比较。
2.可基于hash值的汉明距离计算图片的相似度。
1.细节丢失严重,碰撞概率极大。
2.抗噪声能力弱。
差值感知算法(Difference hash algorithm)
通过比较相邻像素的亮度差异来生成哈希。
1.能较好地保留图像的细节信息。
2.计算简单,开销不是很大。
3.可基于hash值的汉明距离计算图片的相似度。
1.对图像尺寸敏感。
2.高对比度变化区域的影响大于低对比度区域,也容易构造出碰撞。
图片MD5
直接根据图像信息进行MD5加签
1.简单暴力。
2.一张图稍微有点更改,生成的key就不同。
3.碰撞概率低。
1.无法基于hash值的汉明距离计算图片的相似度,即完全无法感知相似图。
通过上述对比分析,其实最佳方案应该是:

其中全局唯一key作为主键索引,图像指纹用于快速的相似比较和检索(现在很多数据库是支持汉明距离计算的)。
不过在具体的实践中,我们基于计算成本的考虑,只采用了图像MD5生成唯一key,并没有同步的计算图像指纹。
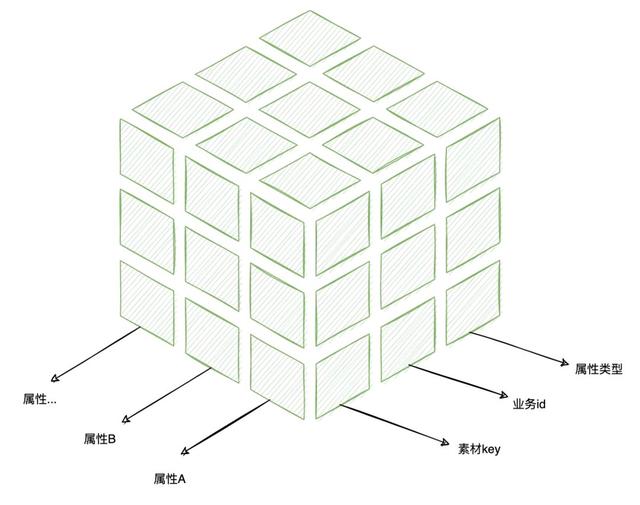
▐4. 使用cube表支持图片属性的自由扩展在定义图片素材的时候,我们可以发现图片可以拆解为和图片本身绑定的、不随业务变更的基础元信息和会随着使用场景不同而变更的业务属性。
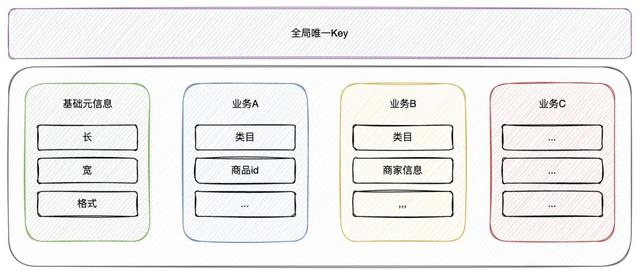
若业务属性在一定范围内是可枚举的,则我们可以简单的用一张大宽表来承载,但当属性是不确定的且可自由扩展的,cube表无疑是一种更好的选择:

调度实践总结
dataworks平台本身提供了节点调度的能力,但是这些调度是预先规划好的、周期性的。我们的大部分场景是触发式调度:使用者发起导入或索引任务,任务立即开始执行,而非等到指定时间(如每天固定时刻)才被拉起执行。经过调研,我们依托dataworks开放的open-api,构建了一套我们自己的任务调度框架。
▐1. Open-apidataworks提供了一系列的开放能力,需要通过在IHave申请一个buc账号来调用这些能力。
▐2. 任务执行框架设计参考市面上成熟的任务执行框架,我们也采取了任务和任务执行实例分离的设计思想,同时引入了触发记录的概念,在实例级别调度控制的基础上,扩展了对于整体调度执行的把控:
 2.1. 领域模型概念阐述2.1.1. 任务
2.1. 领域模型概念阐述2.1.1. 任务一次工作流的统称,比如一次图片素材导入任务,可以拆解为以下的工作流程:
素材准备;数据分片&分桶;素材key生成以及素材上传OSS;基础属性写入;扩展属性写入;任务应该具有这几个基本属性:
任务类型;调度属性:包括调度类型(一次性调度或周期性调度)和调度所依赖的时间信息等;调度依赖:包含任务执行所需要的一些配置信息,如图片素材应该从哪里以什么样的筛选条件读取;状态。要注意的是,任务本身并不能被执行,只有经过触发且实例化后,才能被执行。
2.1.2. 触发器&触发记录通过触发器,触发任务并生成一条触发记录,然后依据触发记录将任务进行实例化。
2.1.3. 任务实例任务的最小可执行单元。实例之间具有依赖关系,只有前置依赖被执行完成,实例才可以被执行;同时实例具有分组,所以可以在分组维度进行并发控制。实例具有以下基本属性:
实例类型:目前支持odps节点,odps sql和java执行实例;实例依赖节点;实例分组;实例归属的任务;实例归属的生成记录;执行状态。2.2. 任务触发示例展示
在任务维度,可以获取所有的触发记录,在触发记录维度,可以进行实例的批量操作(终止和重跑);在实例维度,可以查看实例具体的执行状态以及进行最细粒度的执行控制:单实例级别的任务终止和重跑。

素材输出能力建设总结
支持海量图片的导入存储后,如何快速、灵活、安全的让图片素材投入到不同使用场景,成为了更重要的命题。在线素材输出使用我们采用了Opensearch、Holo和Mysql:
Opensearch:支持向量检索,支持以图搜图,查询速度很快。Holo:基于postgreSql,亿级数据的索引构建只需要分钟级,支持简单的按照属性查询的场景。Mysql:因为是分表存储,所以只支持主键查询的场景。而离线素材输出使用,经过调研和实践,我们发现【参数化View】是个很不错的方式。
▐参数化VIEWMaxCompute传统的VIEW,底层可以封装一段逻辑复杂的SQL脚本,调用者可以像读普通表一样调用VIEW,不关心底层实现。由此VIEW实现了一定的封装与重用,使用非常广泛。
但是这样的VIEW不能接受任何调用者传递的参数,例如某个VIEW读取一个底层表,但是调用者想提供一个表对底层数据进行过滤,或者传递其他参数,都不支持。
这样限制了传统VIEW在代码重用方面的能力,用户仍经常需要多次复制类似的代码。MaxCompute基于2.0新SQL引擎支持带参数的VIEW,可以传入任意表或者其他变量,定制VIEW的行为。
使用参数化VIEW最大的好处,就是在保证数据隔离的基础上,能最大程度上进行底层封装Sql的复用。
最终我们的离线输出能力框架如图所示:

其中底层的素材元信息视图和业务属性视图是可以复用的,任何的业务定制视图都可以通过在其上层加一层过滤来进行业务之间的数据隔离。

结语
在整套能力体系建设完成的过程中,经历了两次大版本的迭代。每次的大更迭,都是因为前一次版本的框架设计在图片素材突破到新的量级时遇到了难以解决的问题。所以工程落地的时候,往往需要比现有场景往后考虑更多。但是在真正的实践中,往后考虑太多又会带来过度设计的困局,所以工程落地,很多时候也是trade-off的艺术,其中取舍是否合理和精妙,考验的是设计者对于系统和业务场景的深入了解和思考。

附录
▐图像感知哈希算法的python实现帮助大家对于图像hash的生成和通过汉明距离计算相似度有个体感。
import cv2import numpy as npfrom tfsClient import tfsClientfrom PIL import Imagefrom io import BytesIO# 感知hash算法def pic_p_hash(img, hash_size = 32): img = cv2.resize(img,(hash_size, hash_size)) # 将图像转换为灰度 gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) img = img.astype(np.float32) # 计算DCT(离散余弦变换) dct = cv2.dct(np.float32(gray)) # 取DCT的左上角8x8区域 dct = dct[:hash_size, :hash_size] # 计算均值 avg = np.mean(dct) # 生成哈希 phash = (dct > avg).astype(int) phash = phash.flatten() phash_str = ''.join([str(x) for x in phash.flatten()]) phash_hex = hex(int(phash_str, 2))[2:].zfill(hash_size // 4) return phash_hex#均值哈希算法def pic_avg_hash(img): # 缩放为8*8 img = cv2.resize(img, (8, 8), interpolation=cv2.INTER_CUBIC) # 转换为灰度图 gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # s为像素和初值为0,hash_str为hash值初值为'' s = 0 hash_str = '' # 遍历累加求像素和 for i in range(8): for j in range(8): s = s + gray[i, j] # 求平均灰度 avg = s / 64 # 灰度大于平均值为1相反为0生成图片的hash值 for i in range(8): for j in range(8): if gray[i, j] > avg: hash_str = hash_str + '1' else: hash_str = hash_str + '0' return hash_str#差值感知算法def pic_dif_hash(img): #缩放8*8 img=cv2.resize(img,(9,8),interpolation=cv2.INTER_CUBIC) #转换灰度图 gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) hash_str='' #每行前一个像素大于后一个像素为1,相反为0,生成哈希 for i in range(8): for j in range(8): if gray[i,j]>gray[i,j+1]: hash_str=hash_str+'1' else: hash_str=hash_str+'0' return hash_str#Hash值对比def hash_cmp(hash1,hash2): n=0 #hash长度不同则返回-1代表传参出错 if len(hash1) != len(hash2): return -1 #遍历判断 for i in range(len(hash1)): #不相等则n计数+1,n最终为相似度 if hash1[i]!=hash2[i]: n=n+1 return nif __name__ == '__main__': img1 = cv2.imread('/Users/bixi/Documents/整理归档/产业中心/图库/图库治理/测试图片/a.jpeg') img2 = cv2.imread('/Users/bixi/Documents/整理归档/产业中心/图库/图库治理/测试图片/b.jpeg') img3 = cv2.imread('/Users/bixi/Documents/整理归档/产业中心/图库/图库治理/测试图片/c.jpeg') img4 = cv2.imread('/Users/bixi/Documents/整理归档/产业中心/图库/图库治理/测试图片/d.png') img5 = cv2.imread('/Users/bixi/Documents/整理归档/产业中心/图库/图库治理/测试图片/e.jpeg') imgHash1 = pic_p_hash(img1, 32) imgHash2 = pic_p_hash(img2, 32) imgHash3 = pic_p_hash(img3, 32) imgHash4 = pic_p_hash(img4, 32) imgHash5 = pic_p_hash(img5, 32) print(imgHash5) cmp1 = hash_cmp(imgHash1, imgHash2) cmp2 = hash_cmp(imgHash1, imgHash3) cmp3 = hash_cmp(imgHash1, imgHash4) cmp4 = hash_cmp(imgHash1, imgHash5) print(cmp1) print(cmp2) print(cmp3) print(cmp4)