马教授的围棋课上,一个新来的学生引起了大家的注意。
这个学生既不会说话,也不懂得手势,甚至没有实际的双手。
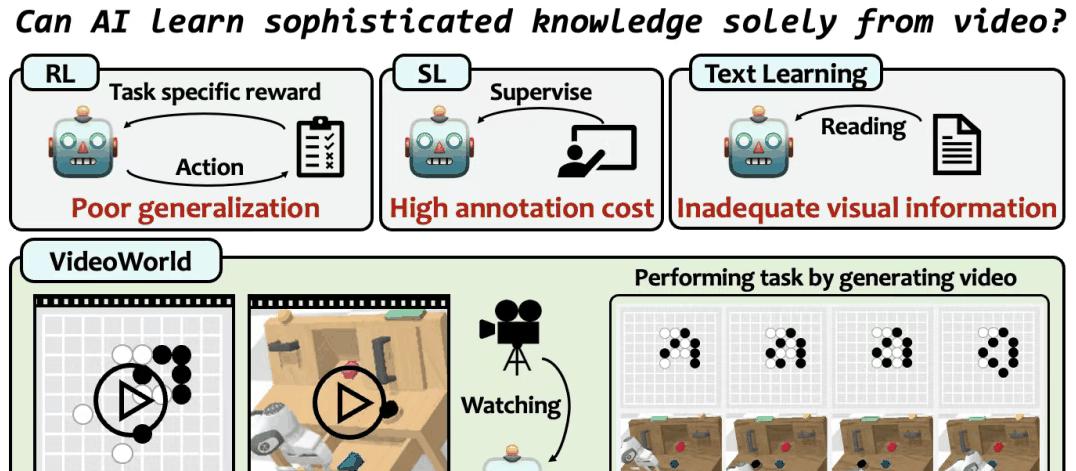
他不是一个人,而是一台电脑,运行着名为VideoWorld的人工智能模型。
这台电脑能够通过观看围棋比赛的视频,学会如何下棋,而且水平已经达到了职业五段!
围棋圈里的不少人对此议论纷纷,有人称赞这项技术的先进,也有人质疑它学习的可靠性和应用前景。
我们一起走进VideoWorld,揭开它的面纱。

打破常规:AI如何不依赖文字学习?
在人们的印象里,人工智能的学习和进步离不开大量的文字数据。

无论是聊天机器人根据上下文回答问题,还是文字识别软件从扫描的文件中提取内容,这些都说明了语言模型在AI发展中的重要地位。
但是,VideoWorld打破了这个常规。
它的设计者希望通过观察视觉信息,跳过文字,直接让AI理解世界。
这听起来有些天方夜谭,但不妨想象一下,人类婴儿也是这么学习的。
就像婴儿通过观察父母的行为学习基本的生活技能,VideoWorld也是通过视频中的信息,捕捉到对象的动作和时机,逐渐理解所需的规则和策略。
这个过程不需要任何文字标签或说明,只依赖视觉信息就能学会。
再回想一下自然界中的灵长类动物。
大猩猩和猩猩们是靠视觉而不是文字学习行为的。

他们通过观察成年动物的动作,模仿并实践,最终学会了觅食、建立社会关系等等。
大猩猩不会通过一段文字说明书来学习如何觅食,它们靠的是眼睛和大脑的协调。
这种直观、自然的学习方式对AI的设计者们启发很大。
魏云超教授和他的团队正是从这种自然界的学习模式中找到了新思路,设计了VideoWorld,让AI通过视频进行直观学习。
所以,我们可以说,VideoWorld展现了灵长类动物的学习模式在人工智能中的应用。
它不仅省去了语言文字的麻烦,还将视觉学习的直观性发挥到了极致。

技术进步如何提升AI的自主学习能力?
VideoWorld的突破性技术背后,有着深厚的理论基础和技术支持。

北京交通大学与豆包大模型团队一同研究开发了这个模型,通过视频生成实验,使得这些AI能掌握推理、规划和决策的复杂能力。
这些能力原本是在需要强化学习的情况下才能获得的,但VideoWorld在没有任何奖励机制或搜索策略的情况下,依然能实现。
这样的设计,大大提高了自主学习的效率和灵活性。

团队的研究结果显示,不仅仅是围棋,VideoWorld在多种机器人场景中也表现出色。
无论是机械臂操作还是复杂的控制任务,人工智能都能够从视频中学习并执行。
这不仅仅意味着技术进步,更是展示了科学家们如何通过创新的模型设计,让AI可以更高效地自我提升。
VideoWorld的潜能与未来应用前景VideoWorld的成功展示,不仅让AI在推理和规划上更上一层楼,还为未来各个领域的应用开辟了新道路。
例如在自动驾驶中,车辆需要实时处理大量的视觉信息。

VideoWorld的技术可以让车辆更好地理解和决策,从而提升驾驶安全性和效率。
在医疗影像分析中,模型通过学习大量医学图像数据,可以辅助医生诊断和做出治疗规划。
当然,VideoWorld的技术目前还处于实验阶段,需要更强的算力和更大规模的数据进行测试。

魏云超教授和他的团队相信,这样的突破性尝试已经为未来的智能技术提供了新的方向。
这个项目不仅展示了团队的实力,更给我们带来了对未来AI技术发展的憧憬。
对传统AI学习方式的反思与总结
我们在传统的AI学习中,见惯了依赖文字模型的方式,比如GPT-4这类模型通过大量的文字数据进行训练,然后才有了现在的自然语言处理能力。
VideoWorld则呈现出一种完全不同的学习方式,让我们反思:AI学习的路径是否可以更接近人类和动物的天然学习方式?
我们是否可以跳出依赖海量文字的数据框住,不断探索视觉和其他感官的信息整合?
VideoWorld不仅实现了技术上的新突破,还为AI技术的未来发展提供了新的思路。
这种不依赖语言模型的学习方式,让人们看到了纯视觉信息的潜力和可能性。
这是对现有AI学习方式的一次革新,希望这项技术能继续发展,为我们带来更多惊喜和可能性。
在这个数字化和智能化不断进步的时代,我们需要更多像VideoWorld一样的创新,让人工智能更人性化,更接近自然的学习。
或许,随着科技的进步,我们会看到越来越多这样的AI,不再依赖文字数据,而是通过自己“眼见为实”来认识和理解这个世界。
