

在产业智能化进程中,如何高效融合企业专有知识资产,构建领域专属认知引擎,是企业迈向智能决策与高效运营的关键。然而,传统检索增强生成(RAG)技术受限于语言单模态处理能力,仅能实现文本知识库与文本查询之间的浅层理解,难以满足复杂业务场景的需求,在实际应用中暴露出两大缺陷:
信息表征缺失:忽略知识库中多模态富文档的视觉语义信息,如版面结构、图表关系、公式特征等;
模态交互受限:无法支持图文混合查询、跨模态关联检索等多样化需求。
针对以上痛点,我们发布了紫东太初多模态检索增强生成框架—Taichu-mRAG。该框架基于统一多模态细粒度检索引擎和紫东太初多模态大模型,旨在提升内容理解与生成质量,实现对多模态信息的协同感知、精准检索与深度推理问答。

Taichu-mRAG 在多模态富文档理解、多模态细粒度实体属性问答两大权威基准上取得突破性进展:
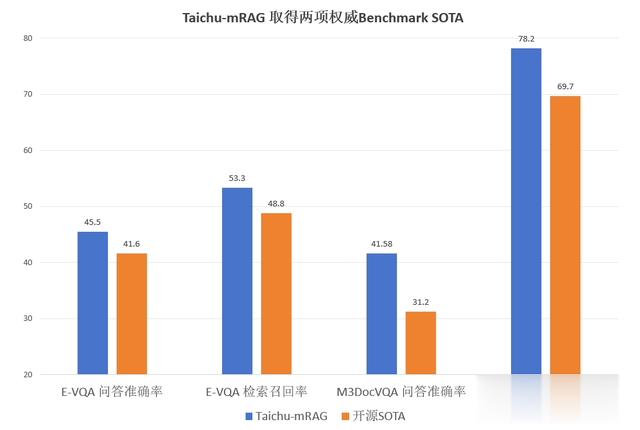
在 M3DocVQA 数据集上端到端问答准确率比开源SOTA M3DocRAG相对提升33%,多模态检索召回率相对提升12%;
在 E-VQA 数据集上端到端问答准确率比开源SOTA EchoSight相对提升9%,多模态检索召回率相对提升9%。

3.1 Taichu-mRAG整体架构
面向新一代智能问答场景,Taichu-mRAG 整体架构包含四大核心模块:Query理解模块、多模态混合索引召回模块、多模态精排模块、多模态增强答案生成模块。

Query理解模块
该模块根据用户Query 及对话上下文深度挖掘用户需求,判断是否需要触发全文理解,并结合对话历史对用户 Query 进行智能扩展、改写,使得改写后的 Query 可以更精准地检索到相关知识。
多模态混合索引与召回模块
该模块包含特征抽取、索引建库及多路召回。在知识库构建过程中,我们先对富文档进行多维度理解、分块,抽取出子级检索单元块;包括基于版面识别的区域级分块、基于纯视觉信息的页面级分块、基于文本语义的滑窗分块;之后,通过多模态Embedding模型抽取这些检索分块的语义特征,在统一语义空间内进行 ANN 索引建库。当收到改写的 Query 后,我们采用多路召回,并行执行四路检索:跨模态索引、关键Term倒排索引、基础语义索引、知识扩展语义索引,高效召回和用户需求最相关的 TopN 知识片段。
多模态精排模块
多模态精排模块负责对召回的 TopN 知识片段进行精细化排序,更加关注细粒度语义信息,有利于处理高难度场景,从而进一步提升多模态大模型的问答精准度。该模块采用单塔结构,深度融合Query、文本、图像、布局特征等信息,确保排序结果更加精准稳定。
多模态答案生成模块
答案生成模块根据前序模块给出的相关参考知识和用户原始Query,联合生成最终的答案,并给出答案的参考片段,便于用户进行答案溯源。当候选片段无法覆盖答案时,多模态大模型会根据用户自定义配置选择拒答或者依赖多模态大模型自身知识进行开放式回答。这一模块不仅生成准确的答案,还提供了答案的来源和依据,增强了答案的可信度和可解释性。
3.2 Taichu-mRAG多模态检索
Taichu-mRAG 的多模态检索引擎采用了双层级父子关联索引机制和多路异构特征联合检索技术:
双层级父子关联索引机制
基于多模态结构感知的层级式分块技术可有效解决多模态数据检索中的粒度适配与上下文整合难题。双层级父子索引技术核心是父级语义单元、子级检索单元的智能分块和关联策略。
子级检索单元为基础单元,核心价值在于根据用户 Query精准召回语义最相关的细粒度语义片段,确保召回的精准性;子级检索单元可包含多种单元形式,如基于滑动窗口的文本片段单元、 图像单元、表格单元、图文混合单元等。父级语义单元为跨模态知识容器,核心价值是为关联的子级检索单元提供完整的上下文信息输入给大模型,提升大模型的回答精度和完整度。
父、子语义单元的切分及关联映射核心在于对以下多种策略的灵活组合: (1)语义理解分块:基于句子、段落、图像、图表多模态 Embedding 计算相似度,当连续内容相似度低于特定阈值时则进行切割。(2)结构化分块:基于布局分析技术,对PDF、PPT、Markdown 等文档按章节、标题或页面、语义块边界进行切割。(3)滑动窗口分块 :设置字符重叠范围及滑动窗口大小,通过滑动窗口对文档内容进行切割。
多路异构特征联合检索
Taichu-mRAG 检索引擎采用多路异构特征联合索引的召回机制,在多模态、复杂富文档理解场景下形成互补增强的检索矩阵,保证了检索系统的精准性和产业落地可行性,多路异构特征索引概况如下:

其中,多模态Embedding模型充分利用多模态大模型的语义理解能力,经过多粒度多阶段学习,实现多种模态在统一空间的语义表征,支持文本、图像、图表、公式等多种混合形式。模型有效缓解了模态偏差问题,同时也具备出色的单模态语义表征能力。
3.3 紫东太初多模态大模型
紫东太初多模态大模型(Taichu-MLLM)具备强大的视觉理解能力和若干特性,支持动态分辨率、图文及多语言输入、图文混排模式等。同时为了更好促进Taichu-mRAG的产业落地应用,针对落地应用过程中的重点需求,我们对Taichu-MLLM 特定能力进行了重点优化:
扩展上下文长度到128k,支持超长文本和多张高清图片输入;
优化拒答指令遵循能力,提升拒答精度,具备准确、稳定的拒答能力;
优化溯源能力,模型同时生成答案和引用来源,便于用户溯源查证,提高答案可解释性。

编辑搜图

编辑搜图

编辑搜图

