
阿里妹导读
本文深入探讨当前最前沿的prompt engineering方案,结合OpenAI、Anthropic和Google等大模型公司的资料,以及开源社区中宝贵的prompt技巧分享,全面解析这一领域的实践策略。
一、背景
随着新一代模型的不断涌现,如GPT-4和Gemini版本,其在理解上下文方面的能力显著提升,prompt长度和复杂度限制越来越宽泛。在本文中,我们将深入探讨当前最前沿的prompt engineering方案,结合OpenAI、Anthropic和Google等大模型公司的资料,以及开源社区中宝贵的prompt技巧分享,全面解析这一领域的实践策略。这篇文章旨在为您提供丰富而详尽的指南,帮助您在大模型的应用与开发过程中,实现更高级、更精准的互动效果。当然过程中也感谢各位大佬的指导帮助,并在此感谢请教和合作的每个人,就不一一列举了,也欢迎大家的指正和探讨。
二、prompt原则&技巧
首先,最权威的提示词教程,莫过于ChatGPT官方文档里的6个写提示词的建议,如下对文档做了总结。

2.1 指令清晰、详细
首先,指令要清晰。要准确表达你的需求,避免让GPT去猜测你的意图。如果你要生成较短的内容,就要求GPT简短回答;如果不想结果太简单,就用专业标准;不满意格式时,示例你期望的格式;总之减少GPT的猜测,我们可以得到更准确的响应。如何做到指令清晰呢?6个建议如下:
2.1.1 问题里包含更多细节在向ChatGPT提问时,应包含相关且重要细节,否则,GPT可能会胡乱猜测。例:
不好的提示词:谁是总统?更好的提示词:谁是 2021 年的墨西哥总统,选举的频率如何?在向ChatGPT提问的时候,要在问题里,包含相关的、重要的细节。 否则的话,ChatGPT就会给你瞎猜。不好的提示词: 总结会议记录。 更好的提示词: 将会议记录总结成一个段落。然后编写演讲者的Markdown列表及其要点。最后,列出演讲者建议的下一步行动或行动项目(如果有)。2.1.2 让模型角色扮演指定模型在回复中扮演特定角色。GitHub人设大全:
https://github.com/f/awesome-chatgpt-prompts
例:
不好的提示词:如何控制消极情绪?更好的提示词:我想让你担任心理健康顾问。我将为您提供一个寻求指导和建议的人,以管理他们的情绪、压力、焦虑和其他心理健康问题。您应该利用您的认知行为疗法、冥想技巧、正念练习和其他治疗方法的知识来制定个人可以实施的策略,以改善他们的整体健康状况。我的第一个请求是“如何控制消极情绪?”2.1.3 使用分隔符
使用三重引号、XML标签、章节标题等分隔符,帮助划分文本的不同部分,便于大模型更好地理解。
对于简单的内容,有分隔符和没有分隔符,得到的结果,可能差别不大。但是,任务越复杂,消除任务的歧义就越重要。大模型是为我们生成内容的,不要把它的算力,浪费在了理解我们输入的内容上。
例:
用三重引号分隔将三重引号中的古诗翻译成现代汉语。 """ 关关雎鸠,在河之洲。 窈窕淑女,君子好逑。 参差荇菜,左右流之。 窈窕淑女,寤寐求之。 求之不得,寤寐思服。 悠哉悠哉,辗转反侧。 参差荇菜,左右采之。 窈窕淑女,琴瑟友之。 参差荇菜,左右芼之。 窈窕淑女,钟鼓乐之。 """用XML标签分隔您将获得一对关于同一主题的文章(用 XML 标记分隔),先总结一下每篇文章的论点。然后指出他们中的哪一个提出了更好的论点并解释原因。<article> 在这里插入第一篇文章</article>2.1.4 指定完成任务所需的步骤
详细写出任务所需的步骤,可使模型更容易按步骤执行。
例:
使用以下步骤完成用户请求。第 1 步:在三重引号内的文本中用一句话总结,加前缀“Summary:”。第 2 步:将摘要翻译成西班牙语,加前缀“Translation:”。"""在此插入文本"""2.1.5 提供示例
通过示例让模型理解你的需求,多用于难以描述的任务或特殊风格中。
例:
假设你是一个旅行博主,你希望模型能以引人入胜的方式描述各种旅游地点。你可以这样写提示词:你是一个旅行博主,我会在三重括号内给你提供示例。你模仿示例,写出5个回答。提示词:告诉我关于上海的事。""" 提示词:告诉我关于巴黎的事。回答:巴黎,犹如一首经久不衰的交响乐,每个角落都充满了艺术与浪漫的气息; 埃菲尔铁塔,卢浮宫,塞纳河都如同乐章,述说着这座城市的历史与未来。 """2.1.6 设定回答的长度
要求大模型根据单词/字数、段落数量、要点数量生成回答,这样大模型生成的答案更有条理。
例:
用大约 50 个字总结以下文本,并总结为两个段落,三个要点。"""插入文本"""2.2 提供参考文本
给模型提供可信的信息来编写答案,或者引用参考文本编写答案,避免胡乱回答。
例:
使用以下文章回答问题。如果找不到答案,回复“我找不到答案”。"""插入文章"""问题:插入问题2.3 将复杂任务拆分
将复杂任务分解成简单步骤,方便模型操作,提高准确性。
2.3.1 问题分类先把这些任务按类型分类,然后给每一种类型的任务都制定一套相应的步骤或者指令。使用这种方法的好处就是,每一次我们只需要关注当前的任务和相应的步骤或者指令,这样就可以降低出错的几率,而且也能节省成本。因为处理大任务需要的电脑运行费用,通常会比处理小任务的费用要高。
例:
您是一个网络专家,将收到客户服务查询。将每个查询分为主要类别和次要类别。主要类别:计费、技术支持、账户管理或一般查询。次要类别:退订或升级、添加支付方式、收费说明、对收费提出异议。根据不同的类别给出详细的解答。假设客户需要“故障排除”方面的帮助。你将需要处理一些需要技术支持进行故障排查的客户服务咨询。请按照以下步骤帮助用户:● 让他们检查路由器的所有线缆是否都已连接。注意,线缆随着时间的推移容易松动是常见的问题。● 如果所有的线缆都已连接,但问题依然存在,请询问他们正在使用的路由器型号。● 现在你需要指导他们如何重启设备: ○ 如果型号是 MTD-327J,建议他们按住红色按钮 5 秒钟,然后等待 5 分钟后再测试连接。 ○ 如果型号是 MTD-327S,建议他们拔掉电源后再插入,然后等待 5 分钟后再测试连接。● 如果客户在重启设备并等待 5 分钟后问题依然存在,通过输出 {"IT support requested"} 将他们转接到 IT 支持。● 如果用户开始提问与此主题无关的问题,那么确认他们是否想结束当前的故障排查聊天,并根据以下方案对他们的请求进行分类2.3.2 分段总结长文/长对话分段总结,再汇总,即总结前一部分的时候,带上之前的内容。多轮对话中,这样更利于后面回答的准确生成。
例:
问:请输入内容回答1: [段落1内容总结]问2:请输入内容回答2: [段落2内容总结] + [回答1]请根据以上格式提供每段的内容,这样能更好地对每一段进行总结,并逐步汇总所有内容,有助于生成最终的回答。2.4 给大模型时间“思考”
2.4.1 生成自己的答案再下结论让模型先自行解决问题,之后比较并评估学生答案的正确性,让模型回答更有条理,也可提高准确性。
例:
首先想出你自己解决这个数学题的方法,然后将您的解决方案与学生的解决方案进行比较,并评估学生的解决方案是否正确。在您自己完成问题之前,不要判断学生的解决方案是否正确。2.4.2 隐藏推理过程
在给用户答案前,模型先在内部思考,不展示部分思考过程,即一个"内心独白(inner monologue)"的技巧。这样同样让模型回答更有条理,提高准确性,也不会干扰用户期望的输出。
例:
按照以下步骤回答用户查询。 第 1 步 - 首先找出您自己的问题解决方案。不要依赖学生的解决方案,因为它可能不正确。将您为此步骤所做的所有工作用三重引号 (""") 括起来。 第 2 步 - 将您的解决方案与学生的解决方案进行比较,并评估学生的解决方案是否正确。将您为此步骤所做的所有工作用三重引号 (""") 括起来。 第 3 步 - 如果学生犯了错误,请确定您可以在不给出答案的情况下给学生什么提示。将您为此步骤所做的所有工作用三重引号 (""") 括起来。 第 4 步 - 如果学生犯了错误,请向学生提供上一步的提示(三重引号外)。不要写“第 4 步 - ...”,而写“提示:”。2.4.3 让模型反思回答让大模型再去找找看有没有之前漏掉的内容,往往能让模型的输出结果,变得更好。
例:
You will be provided with a document delimited by triple quotes. Your task is to select excerpts which pertain to the following question: "What significant paradigm shifts have occurred in the history of artificial intelligence." Ensure that excerpts contain all relevant context needed to interpret them - in other words don't extract small snippets that are missing important context. Please think about your answers and answer carefully.2.5 使用外部工具
2.5.1 嵌入(embedding)使用基于嵌入的搜索来实现高效的知识检索,利用外部信息作为其输入的一部分,有助于模型生成更加明智和最新的回答,即RAG(Retrieval-Augmented Generation)。
例:
如果用户提出关于特定电影的问题,结合```高质量的电影信息(如演员、导演等)```来回答用户的问题。2.5.2 调用API提供文档与代码示例,指导模型使用API,使用代码或者调用外部的API,产生的输出一起输入给模型使用,来进行更精确推理。
例:
结合```文档与代码示例```您可以通过将生成的Python代码/API调用结果括在三重反引号中来进行下面的计算,```代码在这里/API调用结果在这里```使用它来执行计算。注:执行模型生成的代码或API可能本身并不安全,需要一个沙盒代码执行环境来限制不受信任的代码可能造成的危害。
2.6 系统地测试更改
有时候很难判断新的指令或设计是让你的系统变得更好还是更糟。对于小样本量来说,很难区分真正的改进还是偶然运气。也许这种变化可以提高某些输入的性能,但却损害了其他方面的性能,所以建立一个系统测试流程更有必要。
2.6.1 指标评估以img2code指标对比,需要从页面整体布局、细节、字体等方面,详细评估code生成的好坏
例:
 2.6.2 模型评估
2.6.2 模型评估把模型输出的结果,统一输入模型进行打分评估。
例:
请根据评估标准给结果打分,如下:● 准确性(Accuracy) ○ 定义:模型生成的回答是否准确且符合事实。 ○ 评分标准: ■ 0-2分:回答严重不准确或与事实明显不符。 ■ 3-5分:回答部分正确,但有明显错误或遗漏关键信息。 ■ 6-8分:回答大部分正确,但有细微错误或偏差。 ■ 9-10分:回答完全准确且无可挑剔。● 理解能力(Comprehension) ○ 定义:模型是否正确理解了用户提出的问题或指示。 ○ 评分标准: ■ 0-2分:完全没有理解问题,回答与问题无关。 ■ 3-5分:部分理解了问题,但回答不完全相关。 ■ 6-8分:大部分理解了问题,但有细微的误解。 ■ 9-10分:完全理解问题,并能提供相关的回答。● 生成能力(Generation) ○ 定义:模型生成的文本是否流畅、自然,并且符合上下文逻辑。 ○ 评分标准: ■ 0-2分:生成的文本不连贯,逻辑混乱或难以理解。 ■ 3-5分:生成的文本有部分连贯,但存在明显的逻辑错误或不自然之处。 ■ 6-8分:生成的文本大部分连贯,逻辑合理,但有少许不自然之处。 ■ 9-10分:生成的文本完全连贯,自然且逻辑清晰。2.6.3 人工评估有些美观、简洁等任务较主观,需要人工筛选,根据选定的baseline,给出评价。举例如下:

三、大厂方案
CO-STAR无疑为我们的prompt工作提供了一个非常好的出发点,但对prompt engineering有所了解的同学可以发现,它提供的更多的是针对一些相关简单直观任务的通用方案,缺少了针对复杂的问题的prompt技巧,例如Few-Shot, Though Chain, Self-Reflection。我们转换视角,看一看anthropic、google等其他家公司的prompt技巧,看有没有相关说明来补充CO-STAR方案。
3.1 Anthropic
Anthropic最突出的特点是严谨。在官网资料的最开始就强调,prompt engineering绝大部分工作内容应该放在建立一个完善的评估指标,设计鲁棒的测试用例,而不是编写prompt上。

具体流程如下:
定义任务和成功标准开发测试用例设计初步prompt测试prompt调整prompt完善prompt这里主要关注具体的prompt技巧,整理了如下:
清晰直接提供清晰的指令和上下文内容指导模型的输出;复杂任务提供指定时,将其分解为编号步骤或要点;使用示例给出带有完整输出格式的示例,准确性,一致性以及更好的性能;角色化指定分配一个角色,提供角色的清晰详细的背景信息,使大模型以特定方式做出响应,提高其准确性和性能,并调整其语气和举止以匹配所需的上下文(技术含量高,特定的交流风格,更好的基础性能);标签化使用xml标签;将提示的关键部分(例如说明、示例或输入数据)包装在 XML 标记中,可以帮助 Claude 更好地理解上下文;输入变量和结构化输出处,保证标签描述和内容一致;Chain Prompt连锁提示;多步骤,复杂任务;自我反馈输出;并行处理;鼓励模型循序渐进的思考;COT更复杂的问题,可以指定思考步骤;显示的使用xml将思考和结果分开,<thinking> and <answer>;预填模型的输出;类似incontext learning方式,用几句话引导输出;控制输出格式,明确制定输出细节;所需格式的开头预填充 Assistant 字段。当使用 JSON 或 HTML 等结构化格式时,非常有用;重写鼓励模型自反馈;合理利用上下文;数据指令分离;将指令内容单独提供,实际的数据放在随后的输入中。可以看到绝大部分内容,前面都已经提到。
预填模型的输出,应该是其中的特色,可能和Claude独特的训练方式有关,在其他的prompt提示技巧中都很少提及;数据指令分离,是一个很有价值的prompt方式;Prompt Generator。Anthropic最有趣的一部分,是提供了一个称之为“MetaPrompt”的自动化提示生成工具,可以指导 Claude 生成适合您的特定任务的高质量提示。提示生成器作为解决“空白页问题”的工具特别有用,提供测试和迭代的起点,遵循上面提到的所有最佳实践,例如思维链和将数据指令分离。
官网也提到了自动化提示生成工具的缺点:
只针对单轮对话有较好的效果;只针对Claude3 Optus模型;并不是最佳指示一个好的基础起点;MetaPrompt实际上就是一个非常详尽的,提供了大量例子的提示词,由于过长这里就不填写原文。原始链接在这里,可以自行查看:
https://colab.research.google.com/drive/1SoAajN8CBYTl79VyTwxtxncfCWlHlyy9#scrollTo=BOYnM7A3g6HB
个人感觉意义不是很大,宣传的意义为主。
3.2 Google
Google作为老牌大厂,最近提出的Gemini系列模型依然极具竞争力。官方的prompt提示教程依然保持了老牌作风,是三个大厂里面最详尽的,甚至专门是一本四十多页的书,对新手非常友好。

核心的四个要点,可以看到也是和之前的概念如出一辙,但提供了很详细的例子(实际文章中绝大部分都是例子)。
Persona:人格化Task:任务本身Context:上下文Format:格式下文就是一个非常好的涵盖四个要点的prompt,每行对应其中一点。
You are a Google Cloud program manager. Draft an executive summary email to [persona]based on [details about relevant program docs]. Limit to bullet points.3.3 方案总结
可以看到几个大厂相关的prompt技巧总结,完全可以融入到CO-STAR这个框架中。我们需要强调或者增加的是:
Persona:人格角色化;XML:更多的使用分割符;Prefill-respone:预填模型的输出;Example:增加例子;Response:必要的时候可以置顶输出的长度;Reflection :自我反思;COT:Object中让模型在回答问题之前给出较为详细的推理;最重要的是:要有完善的测试集、测试指标,给系统&Prompt做准确的评估;四、实践示例
我们这里实践的任务,是当前比较火热的Img2code方向,自动化生成前端代码。简单来说输入一张图片,可以在几分钟内将任何图像转换为干净,高质量的的HTML和CSS代码。

之前的代表性项目如微软的sketch2code,尽管在2018年引起了一定关注,但因UI理解不足、生成的代码质量不高等原因逐渐式微,也和当时没有tailwind这种较好的html端直接渲染效果的技术有一定关系,该方案逐渐没落。商业化的产品路线,走向了依靠设计稿进行内容提取的另外一条路线,代表工作阿里的imgcook,腾讯的codefun,但上述问题依然存在。

大模型时代的到来,使这一任务得以简化,并适用于新手和有经验的用户。
新技术主要包括两大部分:
a.内容理解:理解图像的布局和内容。
b.代码输出:生成tailwind风格的HTML文件,并支持高级的JavaScript框架创建动态应用程序(如React/Vue等)。

如下,我们取实际场景的小程序截图为例,实践我们的prompt技巧。使用的原始图片如下:


我们不采用任何技巧,直接instruct gpt4o执行这项工作:
Generate code for a minipp page that looks exactly like this. Return html code and only the full code in <html></html> tags.得到的图片不成形,大模型无法很好理解,如下:


通过如上Prompt原则优化后,生成的有点小程序的样子,但布局依旧不好。
You are an expert Tailwind developerYou take screenshots of a reference miniapp page from the user, and then build single page apps using Tailwind, HTML and JS.Please follow these guidelines:- Ensure the app looks exactly like the provided screenshot.<省略部分prompt>Here is the reference information for images:<省略部分prompt>In terms of libraries,- You can use Google Fonts<省略部分prompt>Return only the full code in <html></html> tags.<省略部分prompt>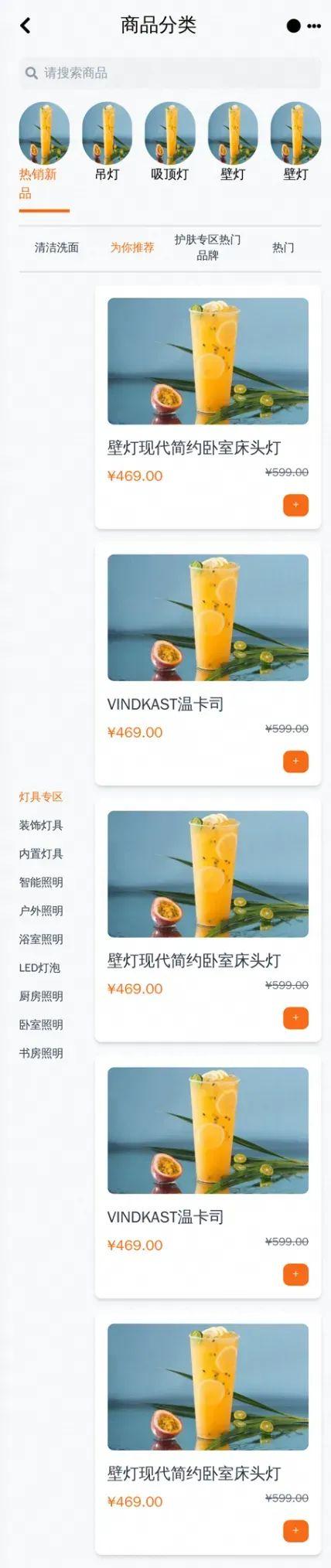

经过Prompt中的高级技巧CO-STAR优化(下一篇会重点介绍,敬请期待),整体风格更加接近小程序,对应的prompt如下:
#CONTEXT#You take screenshots of a reference miniapp page from the user, and then build single page apps using Tailwind, HTML and JS.##############OBJECTIVE#Build a single-page app using Tailwind, HTML, and JS based on a provided screenshot, ensuring it matches the design precisely. Include necessary images and text as specified.Guidelines to follow:- Ensure the app looks exactly like the provided screenshot.<省略部分prompt>Reference information for images:<省略部分prompt>Libraries:- You can use Google Fonts.<省略部分prompt>##############STYLE#Detailed and precise.##############TONE#Professional and instructional.##############AUDIENCE#Developers and technical stakeholders.##############RESPONSE#<html><head> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <script src="https://cdn.tailwindcss.com"></script> <link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/font-awesome/5.15.3/css/all.min.css"></link></head><body> <省略部分prompt></body></html>Return only the full code in <html></html> tags. <省略部分prompt>

再增加COT、Reflection技巧,通过COT给出页面的布局信息,再通过Reflection模型自迭代,生成的布局和细节会更好。


五、进一步
另外,实在不想自己写提示词,也会有些网站可以使用,如:
1)https://www.aishort.top/

2)Awesome chatgpt prompts
https://github.com/PlexPt/awesome-chatgpt-prompts-zh
3)假如自己写了一版Prompt,要自动优化,可参考:
https://promptperfect.jina.ai/interactive

最后,实践中发现,模型本身智能是基础(0->60分),Prompt提升确实很有用,但更多的是锦上添花(60->90分)。
六、写在结尾
在此向所有在阿里云海外业务-行业解决方案研发Superapp AI项目研发组共同努力的同事们致以诚挚的感谢。正是大家一起持续创新,使得我们能够深入探讨Prompt engineering的前沿领域。希望这篇文章能激发更多的创意,助力大家在大模型的应用与开发中不断探索新的可能性。
