当飞书多维表格接入deepseekR1以及其他AI全家桶之后,真的是牛逼炸了。
从现在开始,你真的能用一个多维表格,一个人干掉一支队伍了,并且连你自己都能干掉了,不夸张……

先展示下我随便做的几个多维表格工作流,全部接入了deepseek,以及配合其他识图,总结,信息处理等大模型,后续还可以接入语音模型,视频模型………
第一个是全自动的文案生成多维表格,作用是一键搞定公众号文章撰写,同步简化成微头条内容,然后 是转化成短视频文案用于录制短视频,以及改写重新原创,用于二次分发。
而这一切,就只需要把首列的内容填入即可,简直不要太省事儿。

第二个是全自动ai绘图生成多维表格。效果能达到只需要上传参考图,就可以自动生成中英文画面提示词,以及绘制新的图片,批量绘图的神器啊简直是。

还有很多。。。
今天就来教你如何快速使用飞书的多维表格,接入deepseek,以及结合自己的工作流生成全自动的效率表格。
下载飞书,注册登陆这些就不用说了,结尾最后可以直接找到网址。
主页新建一个多维表格,其实和一般的表格一样,你需要第一列填入一些字段。
就拿我自己平时制作AI视频为例,现在我想要把生图的过程做成全自动的,该怎么做?
先拆解工作流:
找到参考图——识别参考图为中文描述——生成英文提示词——用midjourney生成新图片。
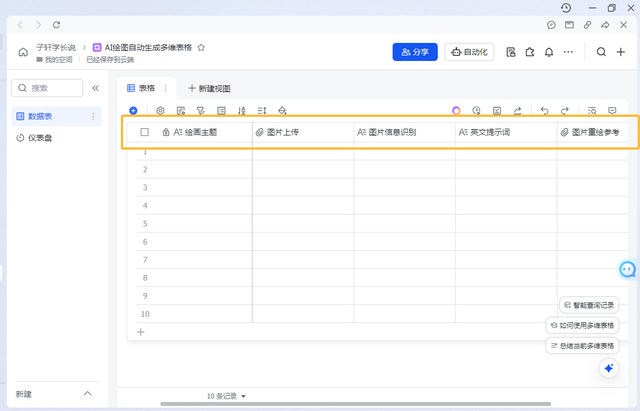
这个工作流就是表格第一列所需要填入的。
可以看到截图当中我已经全部填入的效果。图片上传是核心,最后能达到的效果就是只需要上传图片,其他的空格就全部填满了。

接下来就是设置每一列的字段如何和AI挂钩。
上传图片之后,首先要识别图片为中文描述,所以点击图片信息识别这一列,可以看到字段类型,选择文本就行,因为最终你得到的结果是文本。
然后点击搜索字段捷径,这里是图片,所以需要搜索一个图片识别的大模型。
目前接入能用的就是豆包的AI视觉识别。

选择之后,还需要进行具体的配置,在原图这里选择你要识别的那一列图片,也就是“图片上传”这一列,然后可以自定义指令,额外控制你的要求,类似于你和ai交流的时候使用的提示词。


点击确定之后就会根据你上传的图片ai自动开始处理了,可以看到截图里面的结果,描述的是非常详细的,也比较精准。

然后下一列英文提示词就更简单了,简单一点的方法是可以选中第一个单元格,会出来一个填充按钮,它会根据字段本身的含义自动理解,然后生成表格内的内容,也就是它参考前一列的中文,就直接开始翻译了,非常快。


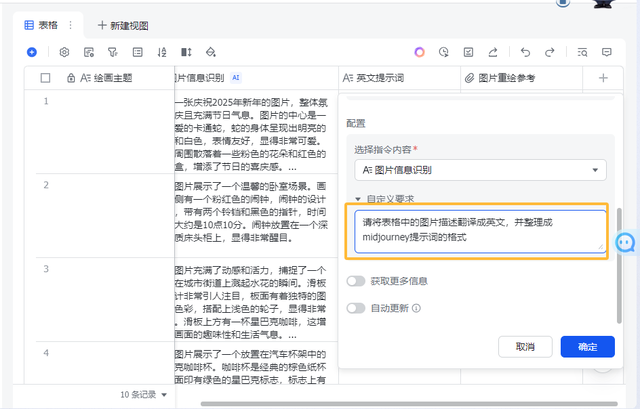
当然你也可以接入deepseek,同样在字段表格的地方双击跳出选择搜索字段捷径,然后找到deepseekr1模型。
同样点击选择指令内容,就是要让deepseek处理哪一列的内容,我选择了“图片信息识别”这一列,然后输入自定义的提示词:请将表格中的图片描述翻译成英文,并整理成midjourney提示词的格式。

deepseek只是让它做个翻译官就太浪费了,我直接让它整理提示词格式输出成midjourney的提示词格式。
当然更加复杂的提示词指令也没有问题,deepseek本来就是推理大模型。
确定之后,同样开始自动处理,生成结果,真的是效率太高了。

我第一次用的时候惊呆了,再次颠覆了我对于效率的认知,以前费劲吧啦和ai连续对话提要求,再也不需要了。
同时让多个ai给你在一个地方打工也更容易了。
更牛逼的是deepseek的接入,输出质量直接起飞~

最后一列图片重绘一样的设置方法,只不过要提醒的是,图片生成的你想要用midjourney或者flux等模型,那就是要正常付费买api的tokens了。

来看看最终效果图:

直接让我这个懒人成废人了。只剩下操作鼠标,点击上传的工作了/捂脸/
再看一个更牛逼的。如果你还不会设计,官方提供了近60个模版的多维表格,涵盖了各个需求,ai搜索的,智能简历解析的,ai绘画的,读取网页链接的,一键写故事的。。。。。。


不得不说,飞书接入deepseek,是真的非常明智的选择,直接牛逼炸了。
