据微信公众号“中科院物理所” 30 日的消息,犹如一石激起千层浪,近日,中科院物理所在江苏省溧阳市举办了一场别开生面的“天目杯”理论物理竞赛,并用 DeepSeek-R1、GPT-o1 和 Claude-sonnet 这三个犹如三头六臂般的 AI 模型对竞赛试题进行了测试,其中 DeepSeek-R1 犹如鹤立鸡群,表现最为出色。原文链接:我们用最近如日中天的 DeepSeek 挑战了物理所出的竞赛题,结果……|内附答案。本次测试犹如一场精彩绝伦的演出,通过 8 段对话完美呈现,第一段如序幕拉开,介绍任务和格式要求。随后,7 道题目题干如七颗璀璨的明珠,依次发送(部分题目含图片描述),AI 们则如八仙过海,各显神通,依次回复,中间无人工反馈。随后,4 个模型的答卷如四份珍贵的答卷,分别发送给 7 位阅卷人,阅卷方式与“天目杯”竞赛如出一辙。最终,所有题目得分如众星捧月般汇总,结果如下
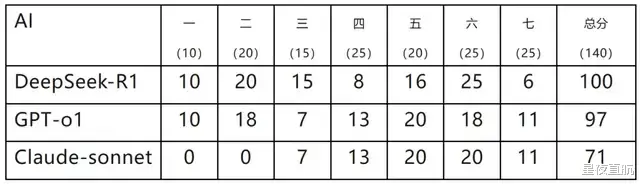
结果点评如下:
1. DeepSeek-R1 犹如一匹黑马,在众多选手中脱颖而出,表现最为出色。基础题(前三题分数尽收囊中),第六题更是取得了人类选手中未曾出现的满分佳绩,第七题得分稍低,似乎是因为未能参透题干中“证明”的深意,只是简单地重述了待证明的结论,故而无法得分。查看其思考过程,其中不乏可以给予过程分的精彩步骤,然而在最后的答案中,这些步骤却犹如昙花一现,未能得以体现。

2. GPT-o1 的总分与 DeepSeek 旗鼓相当。在基础题(二题、三题)中,由于计算失误,导致了一定的失分。相较于 DeepSeek,o1 的答卷风格更贴近人类,犹如一颗璀璨的明珠,在以证明题为主的最后一题中,得分稍高。

3. Claude-sonnet 则如同一匹失蹄的骏马,在前两题中连连失误,惨遭零分的厄运,但后续的表现却与 o1 不相上下,就连扣分点也如出一辙。

4. 倘若将 AI 的成绩与人类成绩相提并论,那么 DeepSeek-R1 足以跻身前三名(荣获特优奖),但与人类的最高分 125 分相比,仍存在较大的差距;GPT-o1 则可挺进前五名(荣获特优奖),Claude-sonnet 亦可位列前十名(荣获优秀奖)。
测试人员惊叹道,AI 的思路犹如行云流水般顺畅,几乎没有让其束手无策的难题,甚至常常能在须臾之间找到正确的解题思路。然而,与人类迥异的是,它们在拥有正确思路后,却会在一些看似微不足道的错误中徘徊不前。就如同通过审视 R1 的第七题思考过程,人们会发现它早在初始阶段就知晓应当运用简正坐标来解题,能够想到这关键一步的考生,几乎可以百分之百地求解出正确的简正坐标。
可是,R1 却好似在反复的猜测和试错中迷失了方向,直至最终也未能得出简正坐标的表达式。不仅如此,所有的 AI 似乎都难以领悟“严密”的证明究竟意味着何等严苛的要求,它们似乎仅仅认为只要在形式上拼凑出答案,便算是完成了证明。此外,AI 亦如同人类一般,也会频繁地犯下诸多“偶然”的错误。例如,在模拟测试时,Claude-sonnet 能够准确无误地解出第一题的答案,但在正式测试的那一刻,它却偏偏出现了失误。
