

(1)向量数据库概述
数据库即用来组织、存储和管理数据的仓库,允许用户和程序以各种方式访问和处理数据。数据库的设计旨在管理大量信息,同时支持快速访问、高效查询、可靠的事务处理和并发访问。
向量数据库(Vector Database)是指以向量形式存储数据集合的数据库,通常通过对原始数据应用某种变换或嵌入函数生成向量并进行管理、存储、检索,是非关系型数据库的一种。相较于传统数据库,向量数据库的核心在于数据向量化和相似性搜索。
(1)数据存储形式
传统数据库通常以表格形式存储结构化数据,向量数据库则通过Embedding技术,将非结构化数据转换为向量数据进行存储,可以将文本、图像、音频、视频等数据转换为高维度的向量,能够更高效地处理更大规模数据。
(2)数据索引与查询方式
传统数据库使用传统的索引结构(B树、哈希索引等),基于精确的数值或关键字进行查询,结果是明确符合条件的数据记录。向量数据库则是模糊查询,使用kd-tree、LSH、HNSW等特殊的索引方式,通过计算一个向量与其他所有向量之间的距离快速在大规模向量数据集中找到最相似的向量,支持复杂的查询操作,如相似性搜索、范围查询等。
表1 向量数据库、关系数据库对比

信息来源:孙雨生、曾俊皓《向量数据库及其应用研究》
(2)向量数据库发展历程及应用场景
向量数据库并非全新的事物,而是随着向量检索需求的发展而发展,最早可以追溯到2012年深度神经网络的崛起,向量成为处理非结构化数据(如图像、音频、视频)的重要数据结构,从而催生了向量数据库的发展。
……
图 1 向量数据库流行度排名
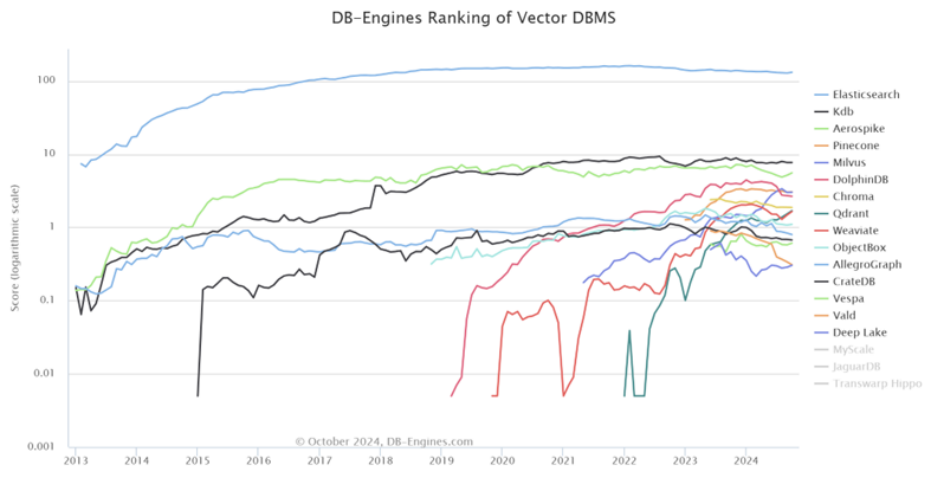
信息来源:DB-engines官网
从下游需求看,2023年以前向量数据库的应用主要集中在图像搜索、自然语言处理、推荐系统等领域内,需求相对小众。
表 2 向量数据库典型应用场景

信息来源:墨天轮《2023 年中国数据库行业年度分析报告》
2023年起,随着大规模生成式 模型的崛起,以人工智能(Artificial Intelligence,AI)为代表的新一代信息技术快速创新应用,带动数据处理需求的爆发式增长以及数据类型的多元化,向量数据库有望得到更加广泛的应用。互联网作为AI率先推进和落地的场景,各大巨头陆续下场研发向量数据库产品。
向量数据库之所以能够成为大模型发展的技术基座,主因非结构化数据应用的增加和大模型发展,导致传统数据库在高维数据存储、查询、任务响应上逐渐显露瓶颈,而向量数据库能够高效地存储、利用相似性度查询快速索引数据,使其可以在大模型训练和推理阶段提升任务的效率,同时降低算力成本。
(1)训练阶段
数据导入时,向量数据库可以将非结构化数据进行清洗、筛选,统一数据格式,便于后续交互计算。
……
(2)推理阶段
首先,由于大模型是基于已有数据训练而得出的,训练数据在时间和空间上均有限制,而向量数据库可以作为外部知识库的角色,作为知识库的扩展插件为大模型进行知识增强,减少大模型生成时可能出现的“幻觉效应”。
……

(1)行业产品和市场规模
截止 2023年6月,全球数据库产品共有 655 款。除了早期的两款网状数据库和层次数据库,在剩余的653个数据库产品中,关系型数据库为309个,非关系型数据库有344个,占比分别为47.3%和52.7%,非关系型数据库中向量数据库仅占比4.1%。
我国数据库产品数量则以关系型为主,关系型数据库和非关系型数据库占比分别为65.5%和34.5%,非关系型数据库中向量数据库数量占比约1%。
图 2 中国数据库产品类型分布

信息来源:中国信通院《数据库发展研究报告(2023年)》
市场规模方面,根据市场研究机构 Markets and Markerts 预测,2023年-2028年,全球向量数据库市场规模预计将从15亿美元增长到43亿美元,预计年复合增长率为23.3%。
图 3 全球向量数据库市场规模(单位:十亿美元)

信息来源:Markets and Markerts
(2)行业主要参与方及融资情况
目前,向量数据库市场主要由初创公司和科技巨头占据,可分为开源和闭源,国外开源厂商Weaviate、Qdrant、Vespa等,闭源如Pinecone,国内Milvus、DingoDB、商业数据库如TensorDB、Om-iBASE、ArcVector等。
图 4 中国数据库产品类型分布
信息来源:Markets and Markerts
由于产业仍处于发展早期,市场尚处于培育阶段,尚未形成部分厂商垄断的市场格局,各厂商向量数据库有其特色,进行差异化竞争,如Pinecone与OpenAI合作,可实现完全托管与可扩展,Weaviate提供自我托管选项,Chroma轻量易用,Milvus 成熟、可扩展, Milvus Cloud专注AI应用,Qdrant是开源向量搜索引擎,人脸识别技术领先。
表 3 国内外主流向量数据库比较

信息来源:整理
借助AI大模型的火热,向量数据库也迎来了更多资本的关注,近年有多家知名向量数据库厂商获得融资,国内厂商情况如下:
表 4 国内向量数据库厂商融资情况

信息来源:研究整理
海外厂商中,Pinecone、Weaviate、Vespa、Qdrant、Chroma等厂商受资本偏好:

信息来源:融中研究整理
(3)向量数据库的技术路径
从技术路径上看,现有向量数据库产品可以分为两类,专业的向量数据库(Native)或使用传统数据库增加向量检索功能(Extend)。Native向量数据库还可进一步分为两种类型mostly vector(只有向量检索)和mostly hybrid(支持混合检索),分别适用于不同应用场景。
……
表 6 不同技术路径的向量数据库产品特点

信息来源:融中研究整理
比较不同技术路径的向量数据库产品表现发现,在传统数据库上增加向量检索功能的方案在优化和查询丰富性上更成熟,Native向量数据库则在向量数据检索效率方面表现更优秀。
……
(4)向量数据库的商业化落地
从商业化落地上看,行业整体仍处于探索阶段,初创公司多选择开源方式培育生态,同时积极进行商业化探索。但由于国内外云服务商业模式的市场培育程度和用户付费意愿存在差异,因此向量数据库公司的商业化路径不尽相同。
以Weaviate为例,Weaviate可选择基于自身云服务或基于第三方公有云SaaS服务(包括AWS、Azure、谷歌)使用产品。基于自身云服务的分为标准版、企业版、商务版,起步价分别为25美元/月、135美元/月、450美元/月;基于第三方公有云SaaS服务的则按照资源使用量进行收费。
表 7 海外主流向量数据库定价

信息来源:融中研究整理
国内情况:云生态培育时间较短,用户付费意愿较低,且B端客户更加注重数据隐私性,公有云服务渗透程度不高。目前国内开发向量数据库产品的厂商可分为独立数据库厂商和互联网厂商。
……

(1)支持GPU、FPGA、TPU等异构计算
向量数据库与传统数据库一大区别在于依靠各种相似度度量方法来找到与给定查询最相近的向量,涉及如点积、欧式距离、余弦相似度等大量的相似度计算,这些计算可能会消耗大量的计算资源和时间。
目前主流向量数据库大多采用CPU进行计算,但随着 LLM 的兴起,尤其在一些对性能、延迟有着极高要求的场景,只通过 CPU 索引来支撑的难度越来越高,在处理高维向量和大规模数据时,采用GPU方案有望进一步提高计算效率。
(2)发展支持存算分离的云原生架构
向量需要有大量的资源去构建索引,这个过程会面临比较大的资源开销,但是构建完成后这部分资源会闲置,同时,在不同量级数据的查询时也会需要资源弹性缩放,但在存算一体架构中,计算和存储通常是紧密耦合的,意味着必须以相同的速度扩展存算节点,导致在只需要拓展计算或存储资源的情况下,资源使用率不高。因此,从降本提效的角度看,支持存算分离的云原生架构,可以实现计算层的快速扩容和缩容,用弹性资源去满足这种短时间的需求。
