9 月 19 日,英特尔正式发布了新一代的酷睿移动处理器家族,也就是此前代号为 Meteor Lake 的系列。全新的 Meteor Lake 系列处理器迎来了巨大的设计变更,以追求出色的电源效率以及满足将来的人工智能应用。
首先,Meteor Lake 系列处理器首次采用 Intel 4 制造工艺,并采用业界出众的 Foveros 3D 封装技术。

和上一代 Intel 7 工艺比起来,Intel 4 高性能逻辑库的面积缩减了 2 倍,能效提升 20%。使用 EUV 技术,在内部采用网格化的互联架构,便于英特尔优化设计。Intel 4 的整体生产的复杂度也有所降低,并提升了良率。

之所以能提升 20% 的能效,是因为 Intel 4 工艺对高性能计算应用进行了针对性的 8VT 优化。因此在同样的电压下能达到比未优化过工艺,以及现行的 Intel 7 工艺更高的频率,有效降低了同功率下的功耗。Intel 4 在内部供电方面,集成的 MIM 电容器的密度提升了 2 倍,让整个电路供电性能也获得了提升。

至于应用 Foveros 3D 封装工艺,则是为了 Meteor Lake 设计而做出的创新。
和之前的单 Die 英特尔处理器不一样,Meteor Lake 采用了逐渐成为行业主流的 Chiplet 小芯片设计。也就是整个处理器由好几个 Die 组成,每个 Die 有明确的功能。而 Foveros 3D 封装的工作,则是将这些负责不同工作的小芯片之间以高密度、高效率和高性能互相连接。
相比基于基板的连接,Foveros 封装技术有更高的叠加性和密度。该技术让 Die 和 Die 之间先互相连接,再透到基板上。这项技术原先用于高密度的 GPU 计算,Meteor Lake 处理器是该技术首次大规模应用于处理器。

采用 Chiplet 设计对于英特尔来说有很多优势。
首先英特尔可以针对不同分区的应用场景,针对性选择使用最理想(以及成本最佳化)的制造工艺,以优化性能(和成本);其次,Chiplet 设计大幅度简化了英特尔推出不同 SKU 的步骤,可以根据最终产品的定位高效率地修改规格;最后,较小的区块让每片晶圆的利用效率提高,在生产端降本增量。
所以理论上来说,不仅是英特尔生产的 Die 之间可以互相连接组成一颗处理器,英特尔也有能力将其他工厂生产的 Die 集成进自己的处理器中。利用封装技术,实现完整的处理器功能。

在 Chiplet 设计理念指导下,一颗完整的 Meteor Lake 处理器分为 4 个单元,分别是 GPU、SoC、IO、CPU。在 4 个单元中,SoC 单元是 Meteor Lake 的核心创新部位。


在上一代的处理器中,英特尔采用环形总线设计。环形总线位于整个处理器中央,核显、内存控制器、SA 等部分围绕环形总线布置。而这种设计在日常低负载使用,比如核显解码视频的时候,进行数据交换就必须激活整个环形总线,这显然会产生不必要的耗电。


因此 Meteor Lake 将含有总线的 SoC 部分放在了正中间,并且把媒体部分从核显里剥离,集成进 SoC 中。
同理,图像、显示、NPU 等部分都被集成在 SoC 里,并且都可以独立地通过 SoC 的总线连接到内存。这样让每一个区域都可以独立地访问内存,而不需要激活其他区域。每个部分在不需要被使用的时候都可以被独立关闭,这样做的好处就是大幅度降低了低负载使用时整个处理器的功耗。
做到这一步就足够了吗?不,英特尔觉得还不够。

为了将低负载工况(也就是移动处理器实际使用中最常见的工况)功耗降到最低,英特尔甚至在 SoC 中集成了 2 个低功耗的 E 核心——下面简称 LP-E 核心。
英特尔和微软进行了深度合作,并大幅度更新了针对异构 CPU 的线程调度器。新的线程调度器在低性能需求场景下,会让运算任务直接在 SoC 中的 LP-E 核心上运行,以此避免唤醒大的 CPU 单元。整个 SoC 单元的制造工艺也专门为高能效而优化,最终大幅度提升了日常低负载工况的电源效率。

因此,Meteor Lake 可以看做是一个 “3D” 混合计算架构处理器。
为了充分发掘新一代处理器的性能和能源效率,英特尔联合微软深度开发了线程调度器。处理器运行的时候,会实时对线程调度器提交当前运行状况。线程调度器会实时生成报告,供系统调度器参考,并向系统调度器提供调度建议。最后系统调度器根据线程调度器的建议,为当前运行的任务选择 3 个架构中(P、E、LP-E)最优的计算核心。
英特尔默认的调度策略会把大部分低负载后台工作直接分配到 LP-E 核心上运行。此举自然是尽可能减少计算 Tile 被激活的情况,以此追求节能。


因此在英特尔展示的调度策略中,Meteor Lake 的 E 核心是否启用,似乎很大程度取决于 P 核心的使用状况。
只要前台存在高需求任务,那么调度器就会激活 CPU Tile,然后根据任务优先级在 CPU Tile 中分配 P 和 E 核心。高优先级任务完成之后 P 核心闲下来了,调度器就会倾向于关闭 CPU Tile,把原先运行于 CPU Tile 上 E 核心的低负载任务迁移到 SoC Tile 中集成的 LP-E 核心里运行。
同理,当 LP-E 核心工作时,如果突然出现高需求任务需要调用 P 核心,那么调度器会激活 CPU Tile。此时既然 CPU Tile 已经激活,那么里面的 E 核心属于“不用白不用”,因此调度器会将 LP-E 核心的任务迁移到 E 核心,直到高需求任务结束 P 核闲下来。
E 核:那我走?

接下来是 AI 方面的优化。
Meteor Lake 是英特尔首次将人工智能加速引擎,也就是 NPU 集成到 PC 处理器中。
移动处理器的 AI 计算是个非常复杂的过程,单纯使用 CPU、GPU 或 NPU 都不能达到最佳效果,因此英特尔给出的答案是异构混合计算。GPU 负责融合 AI 的媒体/3D/渲染计算,CPU 负责轻量级、低延迟的快速相应 AI 计算,而 NPU 则以专用架构,提高持续 AI 运算负载的能效。
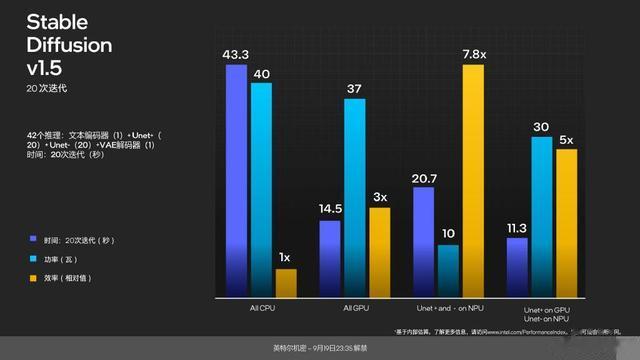
这种混合架构计算的优势显而易见,在英特尔展示的 AI 用例中,NPU 的能源效率是 CPU 的7.8 倍,是 GPU 的 2.6 倍。英特尔搭建的 NPU 也完全符合微软 Windows 操作系统的驱动以及接口,因此在任务管理器中用户甚至可以直接看到 NPU 的工作状况。

最后是 GPU 能力的提升。
Meteor Lake 的 GPU 这次加入了来自 Arc 独显上的功能特性——当然 Meteor Lake 的图形能力,是由 GPU 和 SoC 内的媒体引擎、显示引擎共同组成的,而这种分布式设计的初衷,当然是为了高能效。

集成于 SoC 内的媒体引擎支持最高 8K 60fps 10bit HDR 视频解码和 8K 10bit HDR 视频编码,支持的格式也包括 VP9、AVC、HEVC、AV1 等主流媒体格式。在一部分视频编码中,还可以直接套用 AI 处理,让硬件直接输出经过 AI 处理器的视频信号给应用程序。

集成于 SoC 内的显示引擎支持 HDMI 2.1、Display Port 2.1、eDP 1.4 显示连接标准,支持最高 8K 60fps HDR 显示输出,或是最高 4 个 4K 60fps HDR 显示输出,或最高 1440p 360fps 高刷新率显示输出。

至于 GPU Tile 本身,则集成有 2 个 Render Slice,加在一起 8 个 Xe 核心以及——8 个独立的光追加速单元。没错,在 AMD Ryzen 7000 系列移动处理器之后,英特尔 Meteor Lake 移动处理器也加入了硬件光追能力。和 12 代英特尔酷睿处理器的 Xe 核显比起来,Meteor Lake 的 GPU 有 2 倍的每瓦性能。

当然,在核显上加光追以及性能提升并不是真的为了让你在轻薄本上玩 2077。这些新加入的光追核心可以加速渲染,和纯 CPU 计算比起来,使用光追加速器可以将渲染性能提升 2 倍以上。
以上就是本日英特尔公布的,和 Meteor Lake 处理器相关的技术信息。在本次解禁的内容中,并不包含详细的架构和性能提升,这部分内容英特尔后续会择机公布。

不过可以确定的是,目前已经有各大厂商准备推出超过 30 款基于 Meteor Lake 处理器的移动 PC 产品。作为英特尔的新一代移动处理器,我们期待 Meteor Lake 在实装之后给移动计算带来全新的体验和能效。
