根据权威媒体报道,美国政府计划公布更严格的法规,以阻止向中国运送台积电、格罗方德、英特尔 和 三星电子 制造的先进处理器。新规则所说的“先进”是指采用 14 纳米或 16 纳米工艺技术或更先进技术制造的处理器,其中包含 300 亿个或更多晶体管。
ai芯片的发展新禁令针对的是14nm、16nm节点,并且芯片内部的晶体管堆叠数量在300亿支的芯片。这些芯片主要是应用于高性能计算、AI加速器等领域的产品,对于手机、平板等普通消费级电子产品没有什么影响。
而14nm晶体管的核心技术一个是Fin FET,一个是CoWoS。Fin FET是晶体管的结构设计,CoWoS是芯片的封装技术,可以大幅度提升芯片的性能和晶体管的堆叠数量。
CoWoS封装技术最早是由台积电开发的2.5D封装技术,通过将芯片封装到硅转接板(中介层)上,并使用硅转接板上的高密度布线进行互连,然后再安装在封装基板上。CoWoS技术具有高密度互连、大尺寸支持和散热解决方案等显著优势,已成为高端性能芯片封装的主流方案之一。

英伟达的H100、H200高性能ai芯片、DRIVE Orin自动驾驶芯片、阿尔法狗身上的谷歌神经网络芯片、华为的鲲鹏服务器以及昇腾910集群芯片,都是采用了台积电的CoWoS技术。
而这些主攻人工智能领域的专用CPU芯片,晶体管数量都在500万支以上,甚至英伟达的最新ai芯片的晶体管数量已经达到了800亿支。
与传统封装技术相比,CoWoS技术通过微凸块、硅通孔等先进工艺,大大提高了互联密度以及数据传输带宽,从而在有限的空间内集成更多的晶体管,满足AI芯片对高性能计算和数据处理的需求。
晶体管数量的不断堆叠,可以有效的提升ai芯片的运算速度,从而缩短训练人工智能的时间,典型的例子就是当年与李世石和柯洁对战的谷歌阿尔法狗。
阿尔法狗通过自我对弈的方式进行训练,在与李世石、与柯洁的对弈过程中,它会根据对局结果来调整和优化自己的策略网络和价值网络,使得自己的决策更加准确和高效。这种自我强化学习的过程,使得阿尔法狗的棋力不断提升,最终达到了超越人类顶尖棋手的水平。

在与李世石的对战当中,阿尔法狗1.0混合了蒙特卡洛树搜索、监督学习和增强学习三种算法。其中,监督学习通过学习3000万步人类棋谱,对六段以上职业棋手走棋规律进行模仿,是其获得突破性进展的关键算法。
在与柯洁的对战当中,阿尔法狗已经升级为2.0版本,即Master。该版本放弃了监督学习,不再依赖人类棋谱进行训练,而是完全通过自我对弈来生成数据和优化策略。同时,也放弃了蒙特卡洛树搜索,不再进行暴力计算,使得计算量大幅减少,走棋速度更快。
从分析人类的算法,到后来的自我深度学习,背后依靠的就是强大的芯片算力。
阿尔法狗采用的是谷歌的TPU芯片,这款芯片是谷歌专门为ai学习所开发的专用芯片。在与柯洁对决的过程中,阿尔法狗的TPU芯片在浮点运算上面高达每秒180万亿次,内部集成了250亿+的晶体管数量。

美国在晶体管的堆叠数量与堆叠工艺上面对中国进行出口管制,目的就是为了继续压制中国在ai芯片领域的技术发展。
ai集群的发展,需要大量的芯片作为基础,然后通过封装技术进一步提升所有晶体管的功率。
拿英伟达的GB200超级芯片举例,这块芯片是由两块B200显卡芯片与一块Arm Neoverse V2处理器组成,采用了台积电第二代的4nm工艺制造,双芯片设计使其晶体管数量达到2080亿个。这种上千亿的晶体管堆叠,可以直接将算力应用到大数据计算以及超级计算机当中。

除此之外,还有基于GB200打造的DGX GB200 NVL 72与DGX SuperPOD集群。
DGX SuperPOD集群是目前国际领域最顶级的ai算力集群,由8个DGX GB200 NVL 72组成,搭载288颗Grace CPU和576颗B200 GPU。FP4精度计算性能达到11.5 ExaFlops(每秒11.5百亿亿次)。

如果将以上配置进行晶体管数量的计算,那么整体的晶体管数量来到了1200320亿个。这已经完全超出了普通大众对于芯片产品的认知,并且这个发展速度目前还在持续增长当中。
禁令的影响ai芯片的核心是基于高带宽内存(HBM)进行算力数据的不断抓取,中国深圳的远见智存科技有限公司之前宣布实现HBM2e芯片的量产,这一成果意味着中国在HBM内存研发方面取得了重大突破,极大提升了本土AI芯片的技术水平。

在自主技术没有产出之前,国内ai芯片的发展主要还是依靠台积电的技术和制造工艺。
包括目前国内顶级的华为昇腾集群,其中大部分的昇腾910、昇腾910B都是台积电制造的产品。在受到了美国的制裁之后,华为昇腾集群的发展也受到了一定程度的减缓。
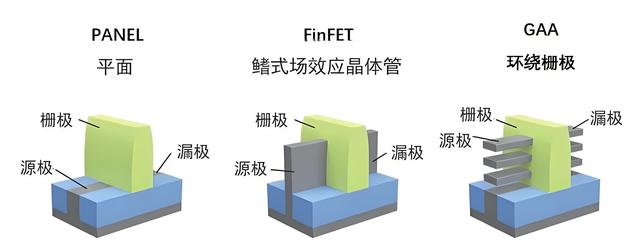
在ai发展的节奏当中,Fin FET晶体管结构是目前主流的芯片技术,三星和台积电正在攻克GAA晶体管技术,目前还没有实现量产商用。
格罗方德曾经在12nm工艺上,针对ai技术进行了相应的训练以及推理应用的优化。SOC逻辑性能相比普通的12nm工艺提升20%,逻辑面积区域缩小10%,有助于在AI处理器与存储器之间实现低延迟、低功耗数据传输。
FinFET技术的发展推动了AI芯片的小型化,使得AI芯片能够在更小的尺寸下提供更强的性能,这对于移动设备、边缘计算设备等对体积和功耗有严格要求的应用场景具有重要意义。
AI芯片在运行过程中需要消耗大量的电能,而FinFET技术能够有效降低芯片的功耗,提高能效比,使得AI芯片能够在更少的电能消耗下完成更多的计算任务。这对于数据中心等需要大规模部署AI芯片的场景具有重要意义,可以降低运营成本和能源消耗。
在制造工艺来到3nm以下之后,Fin FET晶体管结构由于堆叠的问题,内部的栅极无法对电流进行更准确的控制,所以行业内正在逐步往GAA结构上面布局。
GAA通过把栅极和漏极从鳍片变成了纳米线,将栅极对电流的控制力进一步提升。这一技术的推进,将为AI芯片带来更高的性能和更低的功耗,推动AI芯片技术的进一步发展。