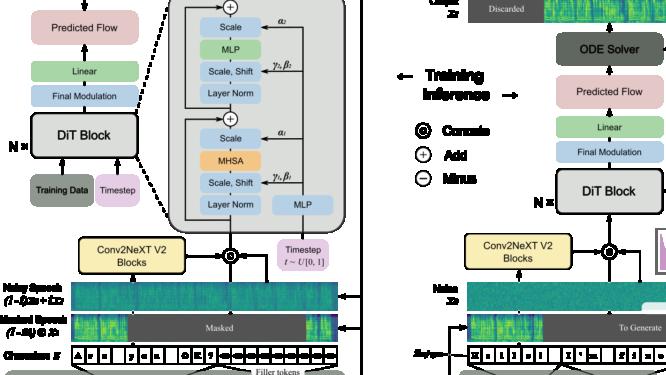
最近,来自上海交通大学、剑桥大学和吉利汽车研究院的研究团队推出了一种全新的文本到语音系统,F5-TTS。它不像传统的系统
FacePoke是一款创新AI工具,允许用户通过直观的拖放界面操纵面部特征和表情。基于强大的LivePortrait框架
BlinkShot 是一个基于Together AI的实时AI图像生成器,它利用Flux技术在用户输入提示时毫秒级生成图
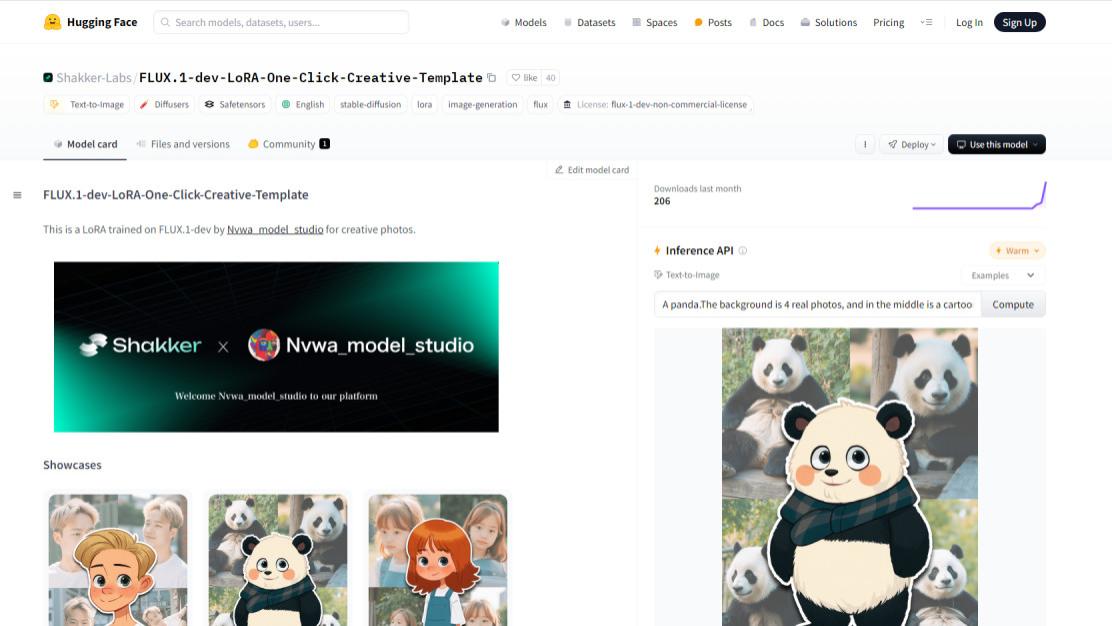
最近我在网上冲浪时看到了一个好玩的LoRA,它可以将真人照片和卡通图像进行组合,从而生成一张极具创新的风格插图。预计很快
Immersity是一款图像转3D视差效果的工具,可以将图像转换为动态视频。该工具可以将一张静态图转换为具备立体感的内容
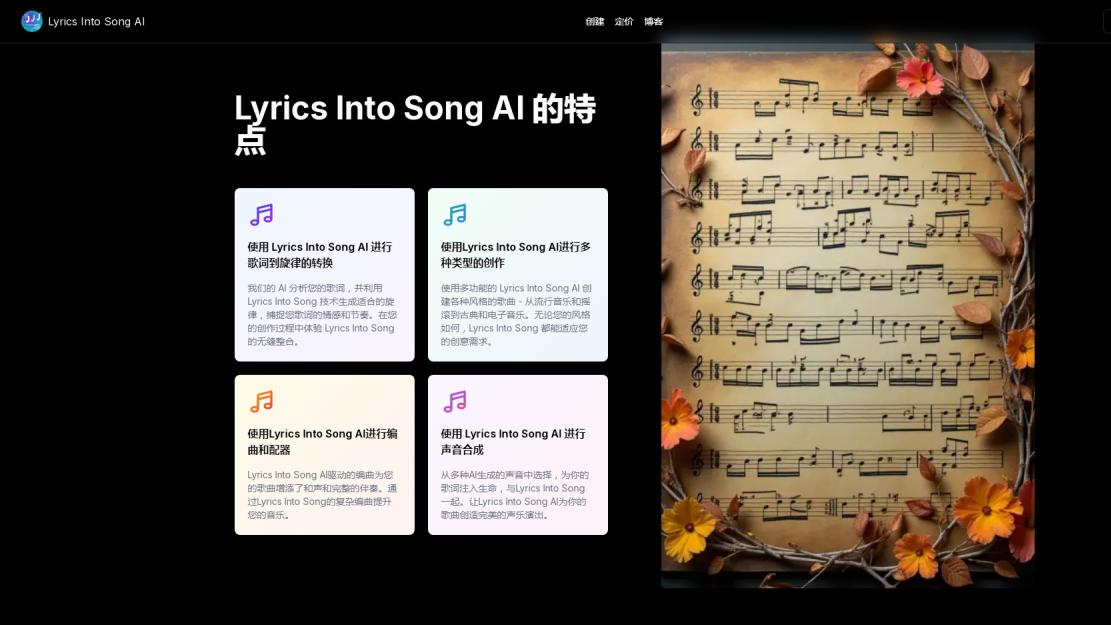
Lyrics Into Song AI 是一种由人工智能驱动的技术,它能够将书面歌词包括旋律、和声和伴奏,转化为完整的歌
近日,Hailuo AI推出了其图片生成视频功能,这项新功能的核心亮点在于其文本与图片联合输入能力。只需同时提供文字描述
half_illustration是一个基于Flux Dev 1模型的文本到图像生成模型,能够结合摄影和插画艺术元素,创
seed-vc 是一个基于 SEED-TTS 架构的开源的声音转换模型,能够实现零样本的声音转换,即无需任何训练,它能够
JoyHallo是京东最新推出的开源数字人模型,它通过收集来自京东健康国际有限公司员工的29小时普通话视频,创建了jdh
ReplaceAnything是由阿里巴巴智能计算研究院推出的一款开源AI图像内容替换框架,它利用先进的人工智能技术,能
Drew Thomasson 最近发布了一个创新的开源项目—— ebook2audiobookXTTS。该工具利用 Ca
Pika1.5是由Pika Labs推出的AI视频生成工具的最新版本。通过强大的特效库,用户只需上传图片或输入文本,即可
最近快手可灵AI又迎来了大升级,正式开放了 API 服务,还新增了创意圈功能,可供用户发布自己的优秀作品。其中最引人注目
LOOPY是由字节跳动和浙江大学的科研团队联合开发的一款基于音频驱动的视频扩散模型。仅需一帧图像和音频输入,就能让虚拟形
Diffusers Image Outpaint 是一个基于扩散模型的图像外延技术,它能够根据已有的图像内容,生成图像的
近日,阿里国际AI团队宣布发布多模态大模型Ovis。据介绍,Ovis能够在数学推理问答、物体识别、文本提取和复杂任务决策
近日,AI视频大模型Vidu推出了“主体参照”功能,该功能能够实现对任意主体的一致性生成,让视频生成更加稳定可控。“主体
在现代社会,证件照的需求无处不在。HivisionIDPhoto 是一个轻量级的 AI 工具,专注于为用户提供智能、便捷
Kolors Virtual Try-On是一个由快手可图团队开发的ai试衣技术,通过可图AI试衣,用户上传自已的照片,
签名:专注AI领域,每天分享新鲜好玩的AI工具,全网同名