人们总喜欢活在舒适区内,用粗暴的断言安慰自己,例如机器永远无法模仿人类的某些 特性。但我给不了这样的安慰,因为我认为并不存在无法模仿的人类特性。
——艾伦·图灵(Alan Turing)
第一节 前AIGC时代的技术奠基一、图灵测试与人工智能的诞生图灵测试:在用机器替换人类的情况下,根据替换后的角色回答错误概率有没有显著增加,可以评估这个替换的机器是否具备智能,这也就是著名 的“图灵测试”。 人工智能诞生:1956年美国达特茅斯学院举行的人工智能夏季研讨会上“人工智能”的名称和任务才被真正界定下来二、符号主义、联结主义和行为主义
人工智能诞生:1956年美国达特茅斯学院举行的人工智能夏季研讨会上“人工智能”的名称和任务才被真正界定下来二、符号主义、联结主义和行为主义 三、机器学习1. 机器学习的概念概念
三、机器学习1. 机器学习的概念概念计算机程序能从经验E中学习,以解决某一任务T,并通过性能度量P,能够测定在解决T 是机器在学习经验E后的表现提升
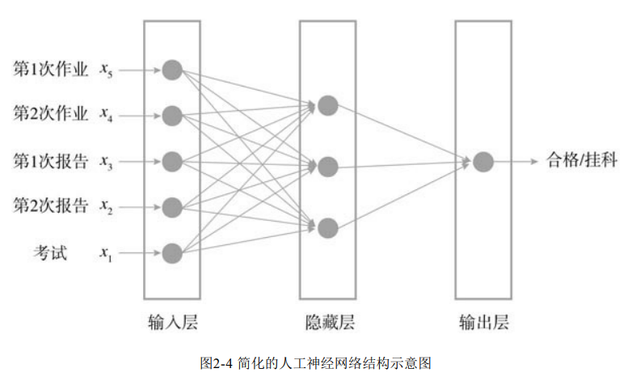
机器学习模型的训练过程数据获取:为机器提供用于学习的数据特征工程:提取出数据中的有效特征,并进行必要的转换模型训练:学习数据,并根据算法生成模型评估与应用:将训练好的模型应用在需要执行的任务上并评估其表现,如果取得了令人满意的效果就可以投入应用机器学习的分类监督学习分类是最经典的监督学习场景: 机器先学习具备什么样特征的数据属于什么样的类别,然后当获取新的 数据后,它就可以根据数据特征将数据划分到正确的类别无监督学习聚类是最经典的无监督学习场景: 机器获得数据后并不知道每种特征的数据分别属于什么类别,而是根据数据特征之间 的相似或相异等关系,自动把数据划分为几个类别。2. 感知器与神经网络感知器一个简易的感知器也就形成了(图2- 3)。学长、学姐两次作业和考试的成绩就是三个输入节点,好比接收外界刺激信息的神经 元。最终判断是否挂科的输出节点,也可以看作一个神经元,而根据分数情况算出合格与挂 科的函数叫作激励函数(Activation Function)。输入节点和输出节点之间神经信号的通信就 是由评价标准公式的计算来传递的,而传递信号的强弱就是作业和考试分数所对应系数的大 小。通过将传递信号的强弱反复调整到一个合适的值,也就完成了模型的学习,可以用于分 类等任务。
 神经网络
神经网络在人工神经网络 中,除了和感知器一样拥有包括输入节点的输入层和包括计算出输出结果的输出层外,还加 入了若干隐藏层。隐藏层中间的神经元节点可以与输入节点和输出节点一一相连,每条连接 的链条上都有各自的权重系数,最终构成了一个网络的结构。
 四、强化学习1. 强化学习的概念
四、强化学习1. 强化学习的概念强化学习并不是要对数据本身进行学习,而是在给定的数据环境下,让智能体学习如何选择一系列行动,来达成长期累计收益最大化的目标。强化学习本质上学习的是一套决策系统而非数据本身。
强化学习与监督学习、无监督学习的区别
对比维度
监督学习
无监督学习
强化学习
学习对象
有标签数据
无标签数据
决策系统
学习反馈
直接反馈
无反馈
激励系统
应用场景
预测结果
寻找隐藏的结构
选择一系列行动
2. 强化学习的构成元素智能体(Agent):人工智能操作的对象,它是这个游戏的主要玩家。环境(Environment):马里奥的游戏世界,马里奥在游戏里做出的任何选择都会得到游戏环境的反馈。状态(State):游戏环境内所有元素所处的状态,可能包括马里奥的位置、敌人的位 置、障碍物的位置、金币数、马里奥的变身状态等,玩家的每次选择可能都会观测到状态的改变。行动(Action):马里奥可以做出的选择,可选的行动可能会随着状态的变化而变化,比 如在平地的位置上可以选择左右移动或跳起,遇到右侧有障碍物时就无法选择向右的行动,获得火 焰花道具变身后就可以选择发射火焰弹的行动等。奖励(Reward):马里奥在选择特定的行动后获得即时的反馈,通常与目标相关联。如果 反馈是负向的,也可以被描述为惩罚。马里奥的游戏目标是到达终点通关,因而每次通过都可以获 得奖励分数,而每次失败都会被扣除奖励分数。如果目标是获得尽量多的金币,奖励也可以与金币 数量挂钩,这样训练出的马里奥AI不会去尝试通过终点,而是拼命在关卡里搜集金币。目标(Goal):在合理设置奖励后,目标应该可以被表示为最大化奖励之和,例如马里奥 的通关次数最多。3. 强化学习的训练过程观测环境,获取环境的状态并确定可以做出的行动:马里奥目前在一个悬崖边上,系统读取了所有元素的状态,马里奥可以左右移动或者跳起。根据策略准则,选择行动:策略里面显示,这种状态下左右移动和跳起的价值差不多,在差不多的情况下,马里奥应该向右走。执行行动:马里奥在人工智能的指挥下向右走。·获得奖励或惩罚:马里奥掉下了悬崖,游戏失败,被扣除一定的奖励。学习过去的经验,更新策略:在这个悬崖边向右走的价值较低,获得奖励的概率更低,人工智能知道后应该倾向于操作马里奥跳起或左走。重复上述过程直到找到一个满意的最优策略。五、深度学习1. 深度学习的概念深度学习适用于学习深藏在元素之间的深层复杂关系,采用的模型主要是复杂化了的神经网络,也被称为深度神经网络。
 2. 深度神经网络与一般神经网络的区别深度神经网络具有更多的神经元深度神经网络层次更多、连接方式更复杂深度神经网络需要更庞大的计算能力加以支持深度神经网络能够自动提取特征第二节 早期AIGC的尝试:GAN
2. 深度神经网络与一般神经网络的区别深度神经网络具有更多的神经元深度神经网络层次更多、连接方式更复杂深度神经网络需要更庞大的计算能力加以支持深度神经网络能够自动提取特征第二节 早期AIGC的尝试:GANGAN(生成对抗网络)诞生于2014年,综合了深度学习和强化学习的思想,通过一个生成器和一个判别器的相互对抗,来实现图像或文字等元素的生成过程
一、生成器我们可以向生成器(Generator)输入包含一串随机数的向量,生成器会根据这一串随机 数生成并输出图像或句子 。
二、判别器用于评价生成器生成的图像或句子到底看起来有多么真实
三、生成对抗过程步骤一:固定生成器,更新判别器步骤二:固定判别器,更新生成器四、GAN的AIGC应用虽然GAN的一些变体也可以用于句子这种文本类信息的生成,但因为对于离散型数据 的处理能力较差,AIGC应用最广泛的场景还是在图像之中,或是与图像相关的跨模态生成中。
第三节 AI绘画的推动者:Diffusion模型Diffusion模型是一类应用于细粒度图像生成的模型,尤其是在跨模态图像的生成任务 中,已逐渐替代GAN成为主流。在2022年美国科罗拉多州博览会艺术比赛中击败所有人类 画家、斩获数字艺术类冠军的AI创作画作《太空歌剧院》的底层技术模型就涉及Diffusion模 型。
一、Diffusion模型的基本原理传统的GAN虽然已经能较好地完成与图像相关的生成任务,但依然存在以下诸多问 题
需要同时训练生成器和判别器这两个深度神经网络,训练难度较大。生成器的核心目标是骗过判别器,因而可能会选择走捷径,学到一些并不希望被学到的特 征,模型并不稳定,有可能会生成奇怪的结果。生成器生成的结果通常具备较差的多样性,因为具有多样性的结果不利于骗过判别器Diffusion的基本原理就是让神经网络学习这个噪声扩散的过程之后逆向扩散,把随机生成的噪声图像逐渐转化为清晰的生成图像。
二、CLIP模型与AI绘画Diffusion模型应用最广泛的领域就是AI 绘画,AI绘画的成功还归功于CLIP(Contrastive Language-Image Pre-Training,文本-图像预训练)模型。CLIP模型是OpenAI在2021年初发布的用于匹配图像和文本的预训练神经网络模型。
三、知名AI绘画工具名称
发布时间
研发企业
特点
Stable Diffusion
2022年8月上线
Stability AI
生成当代艺术图像具 有较强的理解力,善于刻画图像的细节,但为了还原这些细节,它在图像描述上需要进行非 常复杂细致的说明,比较适合生成涉及较多创意细节的复杂图像,在创作普通图像时可能会 略显乏力
DALL*E2
2022年4月更新
OpenAI
更适合用于企业所需的图像生成场景,视觉效果也更接近于真实的照片
Midjourney
2022年7月公测
Midjourney
Midjourney则使用Discord 机器人来 收发对服务器的请求,所有的环节基本上都发生在Discord上,并以其独特的艺术风格而闻 名,生成的图像比较具有油画感
第四节 大模型的重要基建:Transformer一、Seq2Seq模型Seq2Seq(Sequence-toSequence,序列到序列)模型最早在2014年提出, 主要是为了解决机器翻译的问题。
Seq2Seq模型的结构包括一个编码器和一个解码器,编码器会先对输入的序列进行处 理,然后将处理后的结果发送给解码器,转化成我们想要的向量输出
二、注意力机制人工智能领域的注意力机制一开始主要用于图像标注领域,后续被引入到自然语言处理 领域,主要是为了解决机器翻译的问题。
对于认知有重要意义的内容赋予高权重,对于认知意义不大的内容赋予低权重。
人工智能的自注意力(Self-Attention):将第一个字与后面所有的文字进行组合后与认知库去搜寻最为紧密的组合,并按紧密程度赋予较高的权重后进行编码计算。编码完毕后,按照权重对内容进行重新组装。
多头注意力(Multi-Head Attention)机制:主要通过多种变换进行加权计算,然后将计算结果综合起来,增强自注意力机制的效果。
三、Transformer的基本结构Transformer与Seq2Seq模型类似,也采用了编码器-解码器结构,通常会包含多个编码器 和多个解码器。在编码器内有两个模块:一个多头注意力机制模块和一个前馈神经网络模 块,这里的前馈神经网络是一种最简单的人工神经网络形式。
 四、GPT系列模型与ChatGPT
四、GPT系列模型与ChatGPTGPT(Generative Pre-trained Transformer,生成型预训练变换器)是由OpenAI研发的大 型文本生成类深度学习模型,可以用于对话AI、机器翻译、摘要生成、代码生成等复杂的自 然语言处理任务。GPT系列模型使用了不断堆叠Transformer的思想,通过不断提升训练语料 的规模与质量,以及不断增加网络参数来实现GPT的升级迭代。
模型
发布时间
参数量
预训练数据量
GPT-1
2018-06
1.17 亿
约5GB
GPT-2
2019-02
15亿
40GB
GPT-3
2020-05
1750亿
45TB
GPT-4
2023-03
1.8万亿
13万亿Token

ChatGPT完整训练过程:
步骤一:收集示范数据并训练一个监督学习的策略步骤二:收集对比数据并训练一个奖励模型步骤三:使用强化学习算法优化针对奖励模型的策略 五、BERT模型
五、BERT模型BERT(Bidirectional Encoder Representations from Transformers,变换器的双向编码器表示)模型由谷歌在2018年提出,其基本思想是既然编码器能够将语义很好地抽离出来,那直接将编码器独立出来也许可以很好地对语言做出表示。
