
深度求索人工智能基础模型(简称“深度求索”或“DeepSeek”)是由深度求索(北京)科技有限公司开发的国产大语言模型。该模型基于深度学习技术,具备理解和生成人类语言的能力,可广泛应用于文本生成、对话交互、问答系统等领域。
DeepSeek-R1 是深度求索公司推出的具体模型版本,具备高性能的自然语言处理能力,能够处理复杂的文本生成任务,理解和生成自然流畅的文本,适用于多种应用场景,帮助用户高效完成各种任务。
为什么要本地部署?虽然云端部署成本更低,很多服务商甚至提供了一键部署选项,Deepseek 官方也提供了网页/APP 访问,但我们仍有几个理由来进行本地部署:
简单的学习部署方法与应用,输入代码/选择模型的时候,看到一些参数/名词然后搜索一下或者直接问大模型这些名词/参数是什么意思,也是理解 AIGC 的一种方式(请自行搜索什么是 AIGC)
本地 AI 不依赖网络,部署完成后可以断网使用(不会出现某些软件/APP 结果自动加马赛克的问题)
数据私密/安全性
当然从成本和性能来说,云端部署成本更低,也支持部署更大参数量的模型。受限于大部分用户的 RAM 和显卡显存大小,本地是不太可能部署诸如671B 参量的完整模型的。
参数量是什么?在大型语言模型(如深度求索的 DeepSeek-R1)中,参数是指模型内部用于表示和处理信息的变量。这些参数是模型通过训练学习到的数值,用于描述模型如何将输入转换为输出。
简单来说,参数的数量决定了模型的复杂性和能力。一般来说,参数越多,模型的表达能力越强,但同时也会消耗更多的计算资源和内存。
例如DeepSeek-R1-Distill-Qwen-7B-Q8,这里的 7B 就是参数量为 7Billon(70亿),而 DeepSeek-R1-Distill-Qwen-14B-Q8 的参数量为 14Billon(14亿)。(这里的 Qwen 指本模型基于 Qwen 大模型进行蒸馏得来)

量化的详细概念超出本文范畴,但下载/部署模型的时候,会有很多不同量化参数模型可供选择,我个人一般选择 Q8 来获得相对更高的精度。

Q 值越大模型文件大小和所需的 RAM/显存就越大,在零刻官方基于 SER9 Pro 系列机器测试 AI 性能的数据中,可以看到相同模型不同 Q 值所占用的 RAM 值。

我这里使用的是零刻 SER9 Pro,配置为 AMD AI 9 H365 + 32GB LPDDR5x + 1TB SSD,一般主流 16GB/32GB 的机器都可以正常安装和使用7B/14B 模型。

这里我直接把问题丢给了 DeepSeek R1,它的回答其实是比较准确和清晰的,我们需要简单的记住 token 生成速度(token/s)越快,生成答案的速度也就越快。

可以简单的人位蒸馏是一种压缩算法,它不是通过训练一个参数量较小的模型,而是将一个训练参数量更大的模型蒸馏为一个较小的模型。较小的模型可以使用更少的 RAM 和存储,获得更快的速度,降低部署的成本。

但蒸馏毕竟是一种类似压缩的方式,蒸馏后的相对小体积的模型能力必然是落后于更大体积的模型,以 DeepSeek-R1 官方在 AIME2024、MATH-500、GPQA、LiveCodeBench、CodeForces 等测试下的结果,可以看出随着整理模型由 32B → 14B → 7B → 1.5B,得分是依次降低的。
但好消息是DeepSeek-R1-Distill-Qwen-32B 已经超越了 OpenAI o1-mini,而体积更小的 DeepSeek-R1-Distill-Qwen-14B 和 32B 差距并不大,DeepSeek-R1-Distill-Qwen-14B 模型所需的 16GB 内存或是显存获得的成本也并不是非常高。

目前我使用的机器是零刻的 SER9 Pro,CPU 是 AMD AI9 365,GPU 部分是集成的 880M 核显,32GB 总内存。从速度上来说纯 GPU 模式会比 CPU 更快,但如果分配的显存不足,一旦从专属显存溢出到通用内存,生成速度(token/s)会受到比较明显的影响。
考虑到我这台机器并不只是运行 AI,日常也有办公、游戏、娱乐等需求,我目前使用的方案是将32GB 内存划分 16GB 给核显。模型部分则使用DeepSeek-R1-Distill-Qwen-14B(-Q8),这样既能兼顾日常使用,同时也可以有比较大的显存供 LM Studio 和 Amuse 使用。
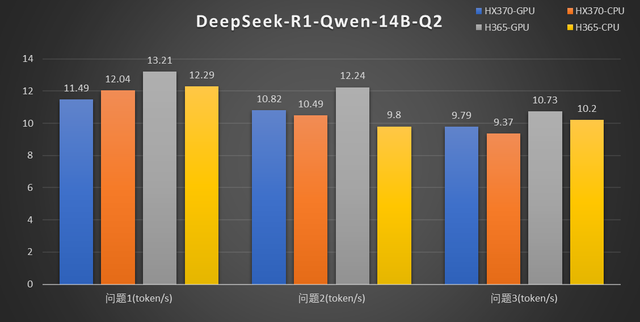
另外零刻官方基于 LM Studio,测试了 SER9 Pro 系列两款机器,纯 CPU、纯 GPU 模式下生成 token 的速度,大家可以参考一下。

需要说明的是 token/s 计算是存在一定误差的,这里对比了同样 GPU 模式下零刻 SER9 Pro HX370 和 H365 的成绩,相对规格稍低的 SER9 Pro AI 9 H365 生成速度比 HX370 更高,这部分差距应该就是测试误差造成的。不过反过来也说明 SER9 Pro AI 9 H365 的性能和规格稍高的 SER9 Pro HX370 基本是属于同一水准。

另外由于 AI 9 系列 CPU 性能很强,在DeepSeek-R1-Distill-Qwen-14B-Q2 测试里,无论是 AI 9 HX370 还是 H365,CPU 生成速度都是略快于 GPU 的。如果你使用 Q2 之类的模型,或者是 7B-Q8,那么纯 CPU 模式效果会更好。
Ollama 和 LM Studio 都是比较方便的部署工具,不过对于初学者个人更推荐 Ollama,虽然使用 Ollama 要输入命令行。但是以实际体验来说,Ollama 的网络访问更通畅,无需换源或是对网络有额外的要求(这部分不是能说的)。软件安装也非常简单,直接官网下载后,一路下一步确认即可完成安装。

模型部分可以直接在顶部搜索栏搜索,也可以在下方主页点击模型名称进行跳转。

Windows 系统下有两个工具自带工具可以使用 Ollama,分别是传统的 CMD 和更新一些的 PowerShell,方法如下:
Win 键,输入 CMD,打开 CMD/命令提示符
Win 键,输入 PowerShell,打开 Windows PowerShell


以 CMD 为例,打开 Ollama 后输入 "ollama" 后回车,应该可以看到如下图这样多行的提示。

安装/运行模型的命令可以直接在 Ollama 的官网复制,在网页上先选择模型参数量,再点击右侧的复制按钮。回到 CMD 内,CTRL+V 快捷键粘贴命令,回车后即可开始下载/运行对应模型。

例如,我这里安装 DeepSeek-R1:14b,直接输入如下命令运行即可:
ollama run deepseek-r1:14b (注意单词间的空格)
第一次运行后下方会显示下载(pulling xxxx),下载完成后会自动运行该模型,已经下载过的模型则会直接运行了。(也就是对于 ollama 而言 run 即可用于下载也可以用于运行)

如果想要查看本机已经安装的模型,直接输入 ollama list 然后回车即可。

如何计算 token 生成速度?方法是加一个命令 --verbose,比如运行命令是:
ollama run deepseek-r1:14b
如果要计算生成速度,那么就修改为:
ollama run deepseek-r1:14b --verbose (注意是两个-)
在生成答案结束后,会紫铜统计总用时、生成速度(eval rate)等信息

当然使用命令行只是为了安装大模型,实际调用时更建议使用单独的 UI 类工具,比如常用的 Chatbox。作为一款免费的工具,Chatbox 可以支持 Ollama 在内很多 API 的调用,无论是本地部署还是云端部署,Chatbox 都是一款值得考虑的助手类工具。

Chatbox 的安装方式也没有太多可说的,官网下载然后一路下一步即可,再配置 Chatbox 之前,建议先打开浏览器,输入:
127.0.0.1:11434 (主要这里:是英文符号)并回车访问
如果看到 Ollama is running 的字样,说明 Ollama 已经在后台成功运行。

这时打开 Chatbox,选择——使用自己的 API Key 或本地模型

因为我们是本地通过 Ollama 部署,所以这里选择——Ollama API

Chatbox 默认就会填入 Ollama 的 API 域名,如果你是使用局域网设备部署,则需要替换 127.0.0.1 为对应主机的 IP 地址。页面内还需要选择模型,这里点击下方模型选择对应 Ollama 内的模型文件名(例如这里我是调用上面安装的 deepseek-r1:14b)即可。
然后在界面内,输入问题等待生成回答即可,一般没有意外这里就可以正常使用了。

Chatbox 本身也支持其他很多 API,包括但不限于本地 LM Studio,云端各种主流云服务,这部分内容大家可以自行挖掘,本文就不再赘述了。
