Transformer模型已经成为大语言模型(LLMs)的标准架构,但研究表明这些模型在准确检索关键信息方面仍面临挑战。今天介绍一篇名叫Differential Transformer的论文,论文的作者观察到一个关键问题:传统Transformer模型倾向于过分关注不相关的上下文信息,这种"注意力噪声"会影响模型的性能。
在这篇论文中,作者注意到transformer模型倾向于关注不相关的上下文。为了放大相关上下文的注意力分数,他们提出了一个新的注意力模型,称为差分注意力模型。在这个模型中,他们将查询和键值向量分成两组,并计算两个子注意力分数。
差分注意力机制差分注意力机制(Differential Attention)的核心思想是通过计算两个独立的注意力图谱之差来消除注意力噪声。这种设计借鉴了电气工程中差分放大器的原理,通过对比两个信号的差异来消除共模噪声。
让我们看看论文中的第一个方程:

方程(1)
方程(1)显示,我们首先像标准注意力计算一样计算Q、K和V张量。关键点是我们将Q和K张量分成Q1、Q2和K1、K2子张量。

论文中输入X、Q1、Q2、K1、K2和V张量的形状
根据论文,Q和K张量的形状应该是Nx2d,因为Q1、Q2、K1和K2将是Nxd。输入X的形状是Nxd_model,这是论文中的嵌入维度。这就是为什么W_Q、W_K和W_V的可学习参数的形状必须是d_modelx2d。
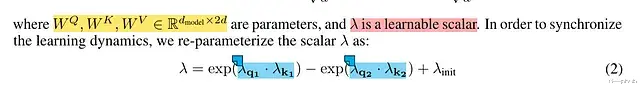
论文中用于lambda计算的方程(2)
方程(2)展示了如何计算可学习参数lambda。在这个方程中有一个初始lambda参数。lambda是一个标量参数,但lambda_q1、lambda_k1、lambda_q2和lambda_k2是向量。这一点很关键。向量lambda_q和lambda_k的运算是点积。
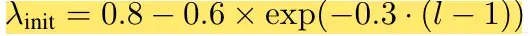
用于lambda初始化的方程(3)
实验结果与性能提升论文的实验表明,相比传统Transformer:
DIFF Transformer只需要约65%的模型参数量即可达到相同的性能,在训练token数量方面也只需要约65%就能达到相同效果

在Needle-In-A-Haystack测试中:4K上下文长度:DIFF Transformer在多目标检索任务中保持85%准确率;64K上下文长度:在深度为25%的位置检测时,比传统Transformer提升了76%的准确率

下面我们根据论文的公式来做一个简单的实现,首先方程(3)展示了我们如何计算lambda_initial变量。现在让我们把方程转换成Python代码:
def lambda_init_fn(depth): return 0.8 - 0.6 * math.exp(-0.3 * depth)
然后再写一个简单的Python函数,使用方程(3)。
class DifferentialAttention(nn.Module): def __init__(self, dim_model: int, head_nums: int, depth: int): super().__init__() self.head_dim = dim_model // head_nums self.Q = nn.Linear(dim_model, 2 * self.head_dim, bias=False) self.K = nn.Linear(dim_model, 2 * self.head_dim, bias=False) self.V = nn.Linear(dim_model, 2 * self.head_dim, bias=False) self.scale = self.head_dim ** -0.5 self.depth = depth self.lambda_q1 = nn.Parameter(torch.zeros(self.head_dim, dtype=torch.float32).normal_(mean=0,std=0.1)) self.lambda_q2 = nn.Parameter(torch.zeros(self.head_dim, dtype=torch.float32).normal_(mean=0,std=0.1)) self.lambda_k1 = nn.Parameter(torch.zeros(self.head_dim, dtype=torch.float32).normal_(mean=0,std=0.1)) self.lambda_k2 = nn.Parameter(torch.zeros(self.head_dim, dtype=torch.float32).normal_(mean=0,std=0.1)) self.rotary_emb = RotaryEmbedding(self.head_dim * 2)
在DifferentialAttention类中,我们实现了一个多头差分注意力机制。有dim_model(嵌入维度)、head_nums和depth参数。为Q1、Q2、K1和K2声明了四个lambda可学习参数,并使用均值为0、标准差为0.1的随机正态分布初始化它们。
def forward(self, x): lambda_init = lambda_init_fn(self.depth) Q = self.Q(x) K = self.K(x) seq_len = x.shape[1] cos, sin = self.rotary_emb(seq_len, device=x.device) Q, K = apply_rotary_pos_emb(Q, K, cos, sin) Q1, Q2 = Q.chunk(2, dim=-1) K1, K2 = K.chunk(2, dim=-1) V = self.V(x) A1 = Q1 @ K1.transpose(-2, -1) * self.scale A2 = Q2 @ K2.transpose(-2, -1) * self.scale lambda_1 = torch.exp(torch.sum(self.lambda_q1 * self.lambda_k1, dim=-1).float()).type_as(Q1) lambda_2 = torch.exp(torch.sum(self.lambda_q2 * self.lambda_k2, dim=-1).float()).type_as(Q2) lambda_ = lambda_1 - lambda_2 + lambda_init return (F.softmax(A1, dim=-1) - lambda_ * F.softmax(A2, dim=-1)) @ V
forward方法很直观。我分别实现了方程(1)和方程(2)。forward方法直接实现了论文中的伪代码。
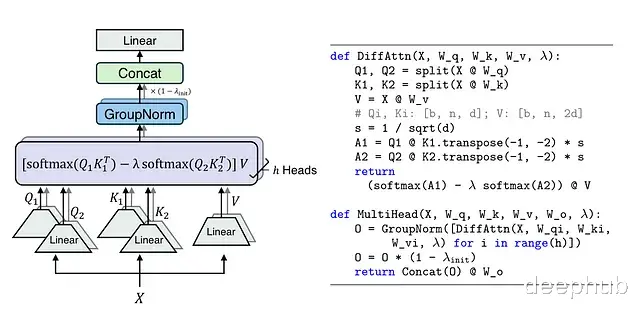
多头差分注意力架构和伪代码
class MultiHeadDifferentialAttention(nn.Module): def __init__(self, dim_model: int, head_nums: int, depth: int): super().__init__() self.heads = nn.ModuleList([DifferentialAttention(dim_model, head_nums, depth) for _ in range(head_nums)]) self.group_norm = RMSNorm(dim_model) self.output = nn.Linear(2 * dim_model, dim_model, bias=False) self.lambda_init = lambda_init_fn(depth) def forward(self, x): o = torch.cat([self.group_norm(h(x)) for h in self.heads], dim=-1) o = o * (1 - self.lambda_init) return self.output(o)
MultiHeadDifferentialAttention类是根据论文中的伪代码编写的。这里使用了RMSNorm而不是GroupNorm。

论文中使用多头差分注意力机制的语言模型的方程
最后使用实现的MultiHeadDifferentialAttention机制构建一个transformer解码器。
class DifferentialTransformer(nn.Module): def __init__(self, dim: int, depth: int, heads: int = 8, head_dim: int = 64, vocab_size: int = 10000): super().__init__() self.vocab_size = vocab_size self.layers = nn.ModuleList([ MultiHeadDifferentialAttention(dim, heads, depth_idx) for depth_idx in range(depth) ]) self.ln1 = RMSNorm(dim) self.ln2 = RMSNorm(dim) self.ffn = FeedForward(dim, (dim // 3) * 8) self.output = nn.Linear(dim, self.vocab_size) def forward(self, x): for attn in self.layers: y = attn(self.ln1(x)) + x x = self.ffn(self.ln2(y)) + y return self.output(x)
性能优化论文还提供了两种FlashAttention实现方式:
1、支持不同维度的实现:
def FlashDiffAttn_1(X, W_q, W_k, W_v, λ): Q1, Q2 = split(X @ W_q) K1, K2 = split(X @ W_k) V = X @ W_v A1 = flash_attn(Q1, K1, V) A2 = flash_attn(Q2, K2, V) return A1 - λ A2
固定维度的实现:
def FlashDiffAttn_2(X, W_q, W_k, W_v, λ): Q1, Q2 = split(X @ W_q) K1, K2 = split(X @ W_k) V1, V2 = split(X @ W_v) A11 = flash_attn(Q1, K1, V1) A12 = flash_attn(Q1, K1, V2) A1 = Concat(A11, A12) A21 = flash_attn(Q2, K2, V1) A22 = flash_attn(Q2, K2, V2) A2 = Concat(A21, A22) return A1 - λ A2
Differential Transformer论文提出的两种FlashAttention实现方案各有特色。第一种实现(FlashDiffAttn_1)采用直接计算策略,允许Q、K、V具有不同的维度,这种灵活性使其更适合需要动态调整维度的场景,但可能在某些硬件上的优化效果不如第二种方案。第二种实现(FlashDiffAttn_2)通过将计算分解为多个相同维度的子运算,虽然计算步骤增多,但每个步骤都能充分利用硬件优化,特别是在支持张量核心的现代GPU上表现更好。
这两种实现的选择主要取决于具体应用场景:如果模型架构需要频繁调整维度或者需要更灵活的注意力机制,建议使用第一种实现;如果追求极致的计算效率且维度相对固定,第二种实现可能是更好的选择。从工程实践角度看,第二种实现与现有的FlashAttention优化库的兼容性更好,更容易在现有基础设施上部署和优化。
局限性和未来研究方向Differential Transformer虽然在多个方面展现出优秀的性能,但仍然存在一些值得关注的局限性。首要的挑战来自其计算效率方面。由于模型需要同时计算两个独立的注意力图谱,这不可避免地增加了计算开销。在实际测试中,相比传统Transformer,DIFF Transformer在3B规模模型上的计算吞吐量降低了约9%,这种性能损失虽然可以通过更少的参数量来部分抵消,但在大规模部署场景中仍然需要认真考虑。
内存使用是另一个重要的局限性。模型需要存储两组独立的查询和键值向量,这导致了更高的内存占用。尽管这种设计对于提升模型性能是必要的,但在资源受限的环境下可能会造成部署困难。特别是在处理超长序列时,内存压力会进一步加大。
训练稳定性也是一个需要特别关注的问题。模型中λ参数的初始化策略对训练过程的稳定性有显著影响。研究发现,不同的λinit取值会导致训练收敛速度和最终性能的差异。虽然论文提出了一个基于层深度的初始化策略,但这种方案并非在所有场景下都能取得最优效果,有时需要根据具体任务进行调整。
基于这些局限性,论文提出未来的研究可以沿着几个重要方向展开。首先在计算效率优化方面,可以探索更高效的注意力核心实现。这包括研究如何更好地利用现代硬件特性,例如开发专门的CUDA核心来加速差分注意力的计算。同时考虑到模型产生的稀疏注意力模式,可以设计特定的稀疏计算优化策略,这不仅能提升计算效率,还能减少内存占用。
λ参数的动态调整机制是另一个值得深入研究的方向。当前的参数计算方案虽然有效,但仍有优化空间。可以考虑设计更灵活的自适应机制,使λ参数能够根据输入内容和任务特点动态调整,从而在不同场景下都能获得最佳性能。这可能需要引入额外的上下文感知机制,或者设计新的参数更新策略。
在内存优化方面,量化技术提供了一个有前景的研究方向。考虑到DIFF Transformer在处理激活值异常方面的优势,可以探索专门的量化策略。比如,研究如何在保持模型性能的同时,对注意力权重和中间状态进行更激进的量化,从而减少内存占用。这对于模型在边缘设备上的部署具有重要意义。
长文本建模能力的进一步提升也是一个重要研究方向。虽然当前模型在64K长度的实验中表现出色,但随着应用需求的增长,可能需要处理更长的序列。这要求研究如何在更长序列上保持模型的效率和性能,可能需要开发新的注意力机制变体或优化策略。
总结DIFF Transformer通过创新的差分注意力机制成功提升了模型性能,特别是在长文本理解、关键信息检索和模型鲁棒性等方面。虽然存在一些计算效率和内存使用的权衡,但考虑到显著的性能提升和更少的参数需求,这是一个非常有价值的改进。这项工作为大语言模型的架构设计提供了新的思路,也为后续研究指明了几个重要的优化方向。
论文地址:
https://avoid.overfit.cn/post/f2e9e7856db24002beb7fc7d2dc33c9
