文:懂车帝原创 常思玥
[懂车帝原创 行业] 3月18日,理想汽车自动驾驶技术研发负责人贾鹏在NVIDIA GTC 2025发表主题演讲,同时发布了理想的下一代自动驾驶架构MindVLA,该架构由理想全栈自研。

根据理想汽车的表述,从应用层面来看,该架构能够将汽车赋能为听得懂、看得见、找得到的专职司机,理想汽车认为,对于汽车行业而言,像iPhone 4重新定义了手机,MindVLA也将重新定义自动驾驶。
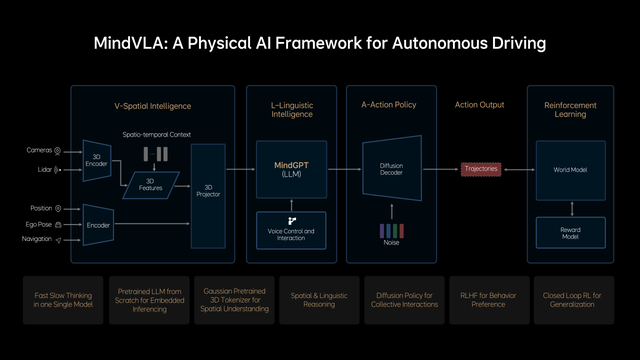
据介绍,MindVLA不是简单地将端到端模型和VLM模型结合在一起,所有模块都是全新设计。3D空间编码器通过语言模型,和逻辑推理结合在一起后,给出合理的驾驶决策,并输出一组Action Token(动作词元),Action Token指的是对周围环境和自车驾驶行为的编码,并通过Diffusion(扩散模型)进一步优化出最佳的驾驶轨迹,整个推理过程都要发生在车端,并且要做到实时运行。

MindVLA基于自研的重建+生成云端统一世界模型,深度融合重建模型的三维场景还原能力与生成模型的新视角补全,以及未见视角预测能力,构建接近真实世界的仿真环境。
据介绍,过去一年,理想自动驾驶团队完成了世界模型大量的工程优化,显著提升了场景重建与生成的质量和效率,其中一项工作是将3D GS的训练速度提升至7倍以上。
据介绍,“听得懂”是用户可以通过语音指令改变车辆的路线和行为,例如用户在陌生园区寻找超市,只需要通过理想同学对车辆说:“带我去找超市”,车辆将在没有导航信息的情况下,自主漫游找到目的地。

“看得见”是指MindVLA具备强大的通识能力,不仅能够认识星巴克、肯德基等不同的商店招牌,当用户在陌生地点找不到车辆时,可以拍一张附近环境的照片发送给车辆,拥有MindVLA赋能的车辆能够搜寻照片中的位置,并自动找到用户。
“找得到”意味着车辆可以自主地在地库、园区和公共道路上漫游,其中典型应用场景是用户在商场地库找不到车位时,可以跟车辆说:“去找个车位停好”,车辆就会自主寻找车位,即便遇到死胡同,车辆也会自如地倒车,重新寻找合适的车位停下,整个过程不依赖地图或导航信息,完全依赖MindVLA的空间理解和逻辑推理能力。
