
阿里妹导读
本文描述了大数据处理任务(特别是涉及大量JOIN操作的任务)中遇到的性能瓶颈问题及其优化过程。
一、背景

一句话介绍背景
二、快速止血
2.1、耗时卡点定位
先来看看这个让人头疼的慢节点,长什么样子?让我看看你是何方神圣。

告辞告辞......
从DAG图怕是很难看出问题,还是先按照latency对各个节点做降序排列,看看到底是在什么地方耗时最多。

几个join任务都是时长杀手,动辄半小时以上。
接下来点进几个耗时top的join任务,有两个发现:
1、或多或少都有数据倾斜现象。

2、多个非倾斜节点运行时间也比较长(30min~1h不等)。
到此为止,我们可以给出初步结论:任务运行耗时过长,是数据倾斜 + join任务资源不足两个原因共同导致的。
2.2、快速止血方案
1、针对join任务资源不足:
提高join任务的资源分配
set odps.sql.joiner.instances = 6000; -- 从原来的2000个instances提到6000个2、针对数据倾斜:
因为宽表代码中,主表是流量/成交/ipv等事实详单数据,join的右表都是标签类维表(主键唯一),所以可以判断倾斜一定是发生在左表上。对左表的关联key进行汇总统计。

按照用户id做汇总统计
倾斜热点主要是由空值带来的,这种情况比较好处理,直接对空值加随机值打散就好。
-- 原join关联代码select ...from ( select visitor_id, -- 用户id ... from 流量日志表 ) t1 left join t2 -- 标签维表on t1.visitor_id = t2.visitor_id -- 加随机值打散joinselect ...from ( select coalesce(cast(user_id as string), concat('rand_salt_value_', substr(cast(rand() as string), 3, 5))) as visitor_id_salt, --空值用随机值填补 ... from 流量日志表 ) t1 left join t2 -- 标签维表on t1.visitor_id_salt = t2.visitor_id -- 避免Null值热点的影响在完成这两步简单快速止血操作后,重跑任务可以发现,运行时间可以节省1h以上,已经初见成效了。但是只做到这些是远远不够的,想进一步提高产出效率,需要更深入地剖析代码,梳理可优化点。
三、代码结构梳理
3.1、主干链路梳理
想从DAG图里梳理清楚数据加工链路,已经是不现实的了,只能回到SQL代码里,看看实现了哪些逻辑,再来寻找切入点。我们忽略掉代码中关于指标加工/格式转化/字段拼接等部分,只看数据表的结构加工和数据流向,大概可以梳理出这样一条主干链路。

宽表任务主干链路
梳理清楚加工链路之后,可以看出来该任务整体上可以划分成两部分:
1、多张事实表的合并(union all),包括流量表/成交表/IPV表/互动点赞表等每日的活跃日志数据等。
2、合并后的事实表作为主表,依次关联(left join)不同维度的标签表,例如用户维表/商品维表/内容维表等。
3.2、存在问题
梳理完代码主干链路之后,可以看出来加工逻辑并不复杂,其实就是做了详单事实表和多张维度标签表的汇总拼接,产出一张字段较全的大宽表。接下来简单分析一下这个任务里存在哪些问题。
1、计算堆积
首先造成任务产出较晚的最直接的原因,就是计算堆积。该节点引用了不少外部空间视图,并且这些视图不是简单的 “select * from xxx;” 形式的的简单语句,而是包含了多张表进行join的逻辑。这就导致了,虽然视图相关的上游表早早就产出了,但视图DDL内包含的计算任务,却落到了该节点上,造成该节点计算量的堆积。
类似地,部分子查询中多表join的计算,也是同理。
2、数据倾斜
在定位耗时卡点的时候我们已经发现了空值带来的倾斜问题,并且做了加盐打散的方法来快速止血。但事实上,分析了多个日期分区的数据发现,除了空值以外,偶尔还会出现部分热点用户/热点主播/热点内容带来的数据倾斜(更要命的是,这些热点值每天都不相同)。虽然倾斜程度不如空值带来的影响严重,但仍然对计算任务造成了一定阻塞。
3、回刷成本高昂
除了上面两个比较明显的问题以外,我们翻看该节点的历史发布记录,可以发现140多个发布版本,有至少一半以上的变更内容是和埋点参数解析相关的。针对埋点解析正确性的验证,往往需要补数据回刷确认,单一节点动辄6、7个小时的回刷成本,给数据验证也带来了不小的麻烦。
四、优化方案
明确了任务中存在的问题,我们的优化目标就非常清晰了:
1、提早产出:越早越好
2、回刷方便:越快越好
3、节省资源:越少越好
4.1、视图落表&节点拆分
优化的第一步,也是最简单的一步,就是将节点中涉及到的视图进行物化落表,并让我们的慢节点任务,从调用视图变成调用实体表。这一步的操作主要是为了缓解计算堆积的问题,让一部分可以提前进行的计算,尽早进行调度,不必等到大宽表所有的上游依赖都产出之后再开始。
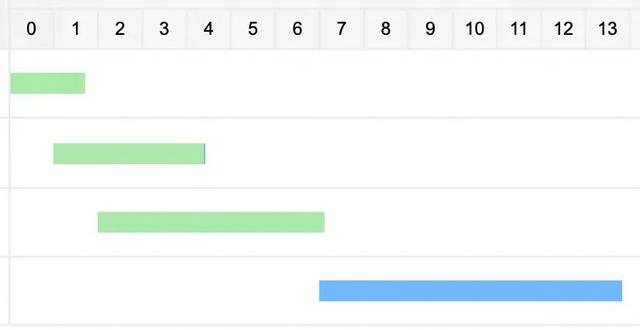
直接引用视图:视图中的计算逻辑堆积到大宽表任务中,增加了运行时间(绿色:上游任务;蓝色:大宽表慢任务)。

视图落表:视图中的计算逻辑提前算好,缓解大宽表节点的计算压力
类似地,我们也可以对部分子查询中的逻辑进行封装落表,拆分成多个节点的方式来把计算压力分散,提早进行调度。这样不仅减轻了大宽表节点的计算压力,也让logview中的DAG图更加清晰明了,方便针对性地进行优化和调参。
4.2、前置裁剪
第二步就是解决数据倾斜的问题。对于非空值的数据倾斜,比较通用的做法有两种:mapjoin和skewjoin。
先说skewjoin,我们这种热点变动的场景(每日流量不一定有热点,热点数量和热点值也不确定),没办法准确指定热点key值,贸然使用skewjoin的话,每日动态获取重复行数top的热值计算,会产生额外资源和时间消耗,收益性价比并不高。
接下来考虑mapjoin。如果join的右表比较小,可以放到内存中,那么使用mapjoin无疑是最优的,这样可以避免大表数据的全量shuffle(在我们这个场景里,左表有几十亿行,TB量级的数据,shuffle成本还是比较高昂的),大幅提升join效率。但是很不幸,我们这里join的右表都不是省油的灯,数据量远超mapjoin能容纳的内存上限(维表行数在几亿~百亿之间不等),直接mapjoin是行不通的。
直接mapjoin走不通并不代表无计可施,通过count distinct 左表的关联key数量,我们发现虽然作为右表的标签维表数据量非常庞大,但最后关联上左表的部分只有非常小的占比(1%~5%)。

全量标签表B中只有一小部分B'实际关联到了左表A
因此,我们优化的方向就是尽量避免无用部分(B-B')参与计算。这种情况我们可以采取两次mapjoin的方式,先对数据行进行前置裁剪后,再完成join关联。
-- 关联前进行裁剪with TMP as -- 获取当日活跃的关联key ( select user_id from A group by user_id )select /*+ mapjoin(B1) */ -- 裁剪后的维表,数据量能降低2个数量级,这时使用mapjoin变为可行 ...from Aleft join ( select /*+ mapjoin(TMP) */ -- 活跃key数据量相对较小,可以使用mapjoin裁剪 ... from B inner join TMP -- 根据活跃key进行裁剪,缩小行数 on B.user_id = TMP.user_id ) B1on A.user_id = B1.user_id;裁剪后的右表数据量大大减少,部分维表此时已经可以满足mapjoin的使用条件了。这时候使用mapjoin关联回主表,自然能解决数据倾斜的问题,同时运行效率大幅提升。
相比直接的Join来说,虽然这种方案增加了计算当日活跃key的步骤(group by),但是通过两次mapjoin规避掉了右表数据中 B-B' 部分的全量排序过程,节省了Disk IO耗时,从而大大提高了join效率。
4.3、中表关联
虽然通过前置裁剪大幅缩减了join右表的数据量,但是并不是所有的右表通过裁剪之后都能放到mapjoin里,像用户标签/内容标签/粉丝标签这些维表,缩减后仍然有几千万行(几十G)的数据量,使用普通join直接关联,耗时仍然较高。
关于较大表之间的join优化,我们可以考虑采用分桶的方案,按照关联key对数据分桶后再来join。但是在这个场景里,需要关联的右表较多,并且关联key都不相同,分桶聚簇键不好设置,分桶join带来的性能提升收益并不明显。
万幸,我们发现ODPS的Distributed Mapjoin可以完美解决我们的困境。我们左表(几十亿行数据,TB量级)远大于需要关联的右表(几千万行数据,百GB左右),符合Distributed Mapjoin使用场景。所以我们对于裁剪后无法使用mapjoin的维表,改为使用distmapjoin来关联。
使用distmapjoin时,有两个参数需要配置:shard_count和replica_count,官方文档中已经有比较明确的推荐参数计算方式了:
Shard
即分片。小表数据分片到各个计算节点处理。shard_count过大会导致client端读取的时候访问过多的server,性能和稳定性受影响;shard_count过小,会导致单个worker内存使用过多报错。
在当前版本中,shard_count值建议手动指定。shard_count值可以根据小表数据量来大致估算。预估一个shard处理的数据量范围是[200M, 500M]。shard_count值最好取质数,简单也可以取奇数。
未来我们会支持shard count的自动计算和调整。
Replica
副本数。为了减少访问压力以及避免单个worker失效导致整个任务失败,同一个shard的数据,可以有多个副本。默认为1,当client端并发过多,或者环境不稳定导致server端频繁重启,可以适当提高replica_count为2或者3。
shard和replica共同决定service端的并发度:并发度 = shard_count * replica_count。
而从我们的节点多次测试对比下来,replica_count设置为2,shard_count设置为:小于 [ 中表mapper输出数据大小 / 200M ] 的最大质数,能够取得兼顾性能与稳定性的较优效果。
4.4、最终优化方案
经过了上面三步优化,我们基本解决了数据关联耗时较长的问题,产出时效有了比较明显的提升,同时也规避掉了部分冗余无用的计算,节约了计算资源。但是做到这样就够了么?回想我们当初想解决的三个问题:计算堆积、数据倾斜、回刷成本高昂。
对没错,针对回刷成本高昂的问题,我们不妨顺手也解决掉,把宽表节点拆分成两部分:关联维表进行标签补全的部分(中间临时表)、埋点解析&字段格式处理的部分(叶子结点)。这样拆分之后,在数据结构没有较大调整的情况下,未来新增埋点参数解析类的需求,只需要变更回刷相对简单的叶子结点即可,无需回刷join关联的部分,从而减少了回刷成本。

优化后的整体数据加工链路
五、效果对比
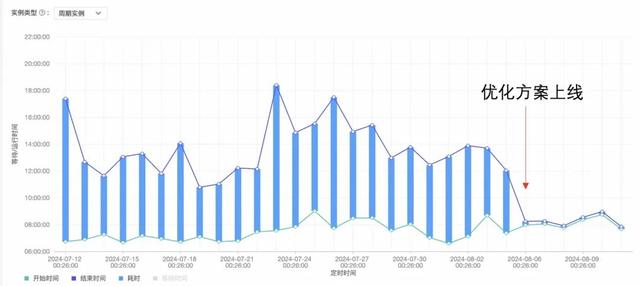
优化方案上线后,宽表产出时间从下午一点左右,提早到了早上八点半左右,节省4h+。
六、总结
复杂odps任务,就像在书包里沉睡了一周的耳机线,想优化就需要耐心找到耗时较长的卡点并一一解决。但更重要的是,从设计开发之初就应该尽量避免在单任务中写耦合度较高的代码,尽量保持单个任务的简单明了,这样不仅能保证代码的运行效率,也能提升代码可读性,降低运维成本。
