引言
在字节跳动,每天有数百万的大数据作业在其全球的数十个数据中心运行。由于作业计算和存储资源的不匹配,存在将跨机房带宽用尽的风险,这会影响其他业务的运作,还会造成不同机房的资源负载不均衡。而且跨机房带宽存在成本高、延迟高、稳定性差等问题,会大幅增加作业的运行时长。为兼顾作业完成时间(Job Completion Time, JCT),并均衡不同机房之间资源的负载,字节跳动基础架构计算团队、存储团队、应用研究中心,和系统部网络团队协作,共同研发了多机房计算、存储、网络一体化资源管理系统 ResLake。ResLake 具备资源的全局视角,通过作业调度、数据调度、网络管控等手段,能够显著优化计算和存储的布局,有效降低业务运营成本。ResLake 上线后,作业平均 JCT(最小化用户作业完成时间) 时间降低了 20%,机房间资源利用率均衡性提升了 53%,跨机房流量降低了 50%,存储成本降低了 46%。
论文链接:https://www.vldb.org/pvldb/vol17/p3934-kashaf.pdf背景介绍
大数据作业与数据表之间存在错综复杂的关系(如下图所示),图(a)表明将近 50% 的作业存在跨机房读数据,34% 的从超过1个远程机房读取。图(b)表明将近 50% 的作业从多个表中读取数据,分布存在长尾效应。考虑到数据高可用和单机房容量限制,这些数据通常以多副本形式存储在多个物理机房中,机房之间通过广域网(WAN)连接。

对于这种多机房架构,现有的解决方案主要集中在最小化跨机房带宽,以此节约跨机房带宽的成本。究其原因是在公有云环境中 WAN 成本高且带宽有限,极易成为瓶颈。这种资源管理方式存在一定的局限性,它忽略了不同资源之间的联动性,造成机房之间资源负载不均。由下图可见,不同机房之间资源利用率相差达到将近 25%。

现有的研究表明,计算、存储和网络几乎有相同的概率成为数据密集型作业的性能瓶颈。因此,我们将计算、存储、网络视为三种不同类型的资源,资源管理系统需要统一考虑不同机房多种资源的排布,并进行全局优化。基于以上原因,我们将多机房资源管理系统的设计目标归结为以下两点:
在作业负载不变和满足 SLO 的前提下,最小化用户作业完成时间(JCT);在资源总量不变的前提下,最优化资源利用率。架构设计
多机房架构下,资源管理系统需要具备全局视角,感知不同机房计算、存储和网络资源的异质性,并为作业和数据的全局排布做出最优决策。为此我们设计了中心化的资源管理系统 ResLake,采用分层架构,具体架构如下图:
 控制层:负责与计算层、存储层、网络层进行交互,控制层综合计算、存储、网络资源状态信息,实时对作业布局进行最优调度决策,并指导和反馈其它层进行作业迁移、数据迁移/复制、网络 Quota 调整等,提升跨机房资源的整体利用率。计算层:负责全域计算资源管理 (GRM) 。GRM 主要负责管理不同机房、不同集群的计算资源,并将最新的计算资源状态汇报给控制层,以便做出最优的作业调度决策。存储层:负责全域存储资源管理。根据控制层的决策,存储层可以对数据进行离线调度,例如变更数据副本分布、增加带 TTL 周期的缓存副本、对多副本数据进行压缩,以优化数据排布和节省存储成本。同时,存储层将存储元数据上报给控制层,用于作业数据亲和性调度决策。网络层:负责全域网络监控、网络 Quota 管控、QoS 保障等,并执行控制层下发的网络 Quota 分配和调整指令。同时,网络层将最新的网络状态、剩余带宽 Quota 等信息上报给控制层,以优化作业调度。
控制层:负责与计算层、存储层、网络层进行交互,控制层综合计算、存储、网络资源状态信息,实时对作业布局进行最优调度决策,并指导和反馈其它层进行作业迁移、数据迁移/复制、网络 Quota 调整等,提升跨机房资源的整体利用率。计算层:负责全域计算资源管理 (GRM) 。GRM 主要负责管理不同机房、不同集群的计算资源,并将最新的计算资源状态汇报给控制层,以便做出最优的作业调度决策。存储层:负责全域存储资源管理。根据控制层的决策,存储层可以对数据进行离线调度,例如变更数据副本分布、增加带 TTL 周期的缓存副本、对多副本数据进行压缩,以优化数据排布和节省存储成本。同时,存储层将存储元数据上报给控制层,用于作业数据亲和性调度决策。网络层:负责全域网络监控、网络 Quota 管控、QoS 保障等,并执行控制层下发的网络 Quota 分配和调整指令。同时,网络层将最新的网络状态、剩余带宽 Quota 等信息上报给控制层,以优化作业调度。系统输入:当用户向 ResLake 提交作业时,需要指定作业的计算资源 Quota,如 CPU/Memory 等。网络带宽资源作为系统级资源池由 ResLake 统一分配。考虑到大数据作业通常需要读取大量离线数据,而单机房容量有限,跨机房读几乎不可避免,这类作业不仅消耗大量的跨机房带宽,并且跨机房读取延时高,导致作业 JCT 时间进一步增长。为了解决这个问题,ResLake 要求作业提交时指定读取的路径,路径可以是数据库表分区、文件路径或消息队列的偏移和长度。ResLake 通过数据特征分析,从而无需用户显式指定作业输入数据路径。
系统输出:经过 ResLake 决策的作业机房和集群。
ResLake 按照调度决策的实时性,分为在线调度和离线优化两种。实时调度侧重于进行轻量化的作业调度,而离线调度侧重于对数据分布进行优化。具体差别如下:
在线调度作业动态调度:ResLake 提供给用户的是一组虚拟队列,虚拟队列可以跟多个物理资源池关联。ResLake 根据作业读取的路径、数据的副本分布、作业资源需求、作业运行时长、物理资源负载、机房剩余带宽等指标,动态决策作业运行的最优物理资源池;数据懒加载:ResLake 允许为每个机房设置缓存。对于临时查询作业,ResLake 在作业跨机房读取数据时,缓存一份临时副本到本地缓存。从而,将后续的跨机房读取转化成本地读;数据访问特征分析:对于周期性作业,ResLake 通过对作业运行的历史数据进行分析,对作业读取路径等进行预测。对于临时 SQL 查询,ResLake 能提前从 SQL 中解析出输入路径,并根据数据量预估作业运行时长。网络 Quota 动态分配:ResLake 为每个作业分配初始网络 Quota,并对 Quota 进行动态调整,回收作业未使用的 Quota,并分配给其它 Quota 不足的作业。离线优化副本缓存:ResLake 通过分析作业历史访问特征,挖掘多机房访问的热点数据,在周期性作业启动前,将数据缓存到对应机房。为避免不必要的存储成本,我们只会同步读写比极高的数据,并且设置数据的过期时间(TTL)。副本策略优化:ResLake 分析周期性作业的历史数据访问特征,生成数据访问模式,对计算和存储机房错配的副本进行调整。温存推荐:ResLake 通过分析数据的访问行为,推荐业务将不常访问的数据放入温存,从而降低业务的存储成本。调度模型

我们将作业调度抽象为 5 个 Meta 任务:
等待调度阶段:任务进入调度队列并等待调度的时间,通常是 ms 级,不实际消耗资源。全局调度阶段:全局调度阶段,根据作业依赖的数据副本分布、预估计算时长、物理资源池负载、物理资源池计算性能、跨机房带宽等指标,为作业找到跨机房读取数据时间最短、且物理资源等待时间最短的机房和集群,调度决策充分考虑了最优化作业 JCT 和资源池负载均衡。调度决策本身耗时也是 ms 级。数据准备阶段:ResLake 为作业寻找满足数据亲和性(计算与大部分数据在同一机房)的机房或者计算资源充足且跨机房带宽充足的机房,ResLake 保证此阶段大部分数据同步到决策机房。主要使用网络带宽,在满足计算数据亲和性时,该阶段耗时可以忽略。集群调度:ResLake 将作业分发到具体集群后,由 YARN/Godel 进行集群内资源调度。该阶段耗时包括等待资源时间和作业运行时间,主要分配计算资源。数据输出:将计算结果输出到存储,供下游计算使用。根据 ResLake 的设计目标,我们将调度抽象为 2 个优化目标:
最小化 JCT 时间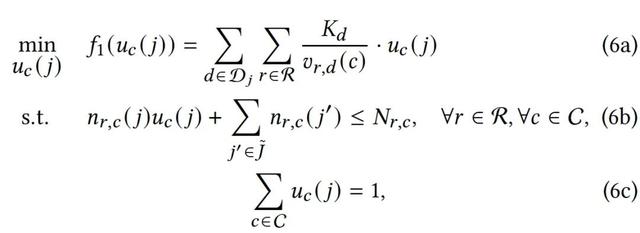
其中, 为作业在机房 的数据量, 为集群 内资源 的处理速度,仅当作业分配到集群 时 。在调度决策时,ResLake 针对各个阶段预估近似处理时间(APT),预估方式为数据量/资源处理速度。因此,JCT 最小化目标,主要根据数据准备阶段和集群调度阶段的 APT 进行优化。
资源负载均衡
其中, 为集群内资源利用。在进行调度决策时,还需要尽可能考虑全局资源的均衡性,比如当作业有多个可选择物理资源池时,选择集群负载更低的资源池,不但能兼顾集群间负载均衡,避免单个资源成为瓶颈,而且低负载集群往往处理速度更快。
结合以上两个优化目标,ResLake 针对作业调度问题归结为求解以下优化问题,其中, 和 为权重,取值在0~1之间,可以根据业务差异调整。

系统实现
控制层和计算层

控制层维护计算、存储和网络资源的全局状态视图,并作出作业调度和全局资源平衡的最优决策。如上图所示,控制层通过 SDK 接受提交的大数据作业。首先,作业将通过计算层实现的虚拟队列权限管理模块(VAM)进行权限校验。接下来,虚拟队列 Quota 管理模块(VQM)根据作业的资源量分配作业请求的资源量。ResLake 实现了统一编排框架 (UOF),用于作业和队列管理,并于底层的计算、存储和网络层交互,进行调度决策,并将作业分发到对应计算集群。
虚拟队列编排:VQM 负责按需编排虚拟队列。对于存在大量跨机房的作业,并且虚拟队列在对应机房没有物理资源池时,虚拟队列管理模块能够为作业在目标分配临时队列,并在作业完成后回收对应资源。
作业动态调度:作业编排模块根据维护的计算、存储和网络资源的最新视图,并根据分析的作业元数据,如作业依赖数据、作业资源需求等,求解调度模型,决策最优的作业运行机房和集群,并将作业分发到对应集群。
存储层
提供元数据查询能力:控制层通过离线预测或者 SQL 解析得到作业依赖的数据路径后,通过存储层进一步分析数据所在机房、每个机房副本数、单个副本大小等信息,并利用这些信息进行数据准备阶段的耗时预估。
具备数据缓存加速能力:为了降低跨机房数据的带宽和延迟,ResLake 离线分析作业所需数据及其访问行为,控制层根据分析结果,在网络低谷期通知存储层发起数据复制/迁移,将数据提前缓存在本地数据中心。
执行副本重分布:存储层数据洞察服务从存储元数据节点、数据节点等存储组件收集存储指标,进而获取当前数据放置策略、存储空间占用、跨 DC 流量等指标,评估数据迁移的预期资源消耗。并通过数据管理服务实现存储副本迁移能力,实现原理是扫描所有文件块的副本分布,判断是否满足目标分布策略(如跨机房流量最少),利用元数据节点副本修复流程补充目标数据中心对应副本,并利用副本删除机制删除不符合副本放置策略的冗余块,最终实现目录级数据中心副本重分布。
对数据聚类分析:基于历史访问特征,可以对离线数据进行更为精细的编排和调整,有序地进行迁移,达到减少跨机房流量的目的。根据计算任务与数据的依赖关系,我们以计算任务与数据路径为顶点,查询任务与数据路径之间的流量为边,构建一个有向无环图(DAG)。上述问题可以概括为将此 DAG 划分为若干个子图,使得跨子图的边权重之和最小。每个子图中的数据路径放在相同机房中,因此跨子图的边就是跨机房的流量。我们使用混合整数线性规划(MILP)来解决数据聚类问题。通过数据聚类,我们能够将关联性强的表放到相同机房中,以减少跨机房数据访问。
网络层
执行初始配额分配:网络层的网络 Quota 管理模块(NQM)在作业提交时执行初始配额分配,并动态管理网络 Quota。对于周期性作业,我们将初始 Quota 分配为作业在最后 n(n>=3)次运行中的平均带宽使用量。对于临时作业,ResLake 为作业分配一个默认 Quota 值。
动态管理网络 Quota:根据当前带宽水位为每个集群设置 Quota 回收带宽策略参数。Quota 管理策略根据剩余 Quota 和计算集群优先级进行差异化调整。当剩余 Quota 水位较高时,将优先为高优集群分配 Quota,并回收低优集群的 Quota。
效果验证
ResLake 上线后,作业平均 JCT 时间下降了 20%。 ResLake 将 CPU 利用率均衡性提升了 80%,内存利用率均衡性提升了 53%。
ResLake 将 CPU 利用率均衡性提升了 80%,内存利用率均衡性提升了 53%。 ResLake 将跨机房流量减少了 50%。
ResLake 将跨机房流量减少了 50%。 ResLake 通过推荐数据进入温存,节省了 46% 的存储成本。
ResLake 通过推荐数据进入温存,节省了 46% 的存储成本。总结
针对多机房架构,通过设计多机房统一资源管理系统 ResLake,减少作业完成的同时实现不同机房之间的资源均衡。ResLake 具备计算、存储和网络的全局视角,能够全局优化资源的最优排布问题。在 ResLake 的实现上,控制层与底层计算、存储和网络层协调,以确保各种在线和离线机制的有效性。并如上文所介绍的,在字节跳动的生产实践中验证了自 ResLake 部署以来,大数据作业平均作业完成时间明显降低、资源均衡性得到显著提升,并且跨机房流量和存储成本大幅下降。
