先前主流AI工具如OpenAI、文心一言、KIMI等均采用闭源模式,核心技术由少数企业掌控。用户需付费获取完整服务,部分产品(如ChatGPT)甚至限制中国大陆访问。这种垄断态势令人联想到文艺复兴前欧洲教会对知识传播的掌控——彼时珍贵的羊皮卷正如当时封闭的AI技术,而DeepSeek的开源突破恰似造纸术与印刷术的革新,新的科技革命已然开启,而这次革命的主角依旧在东方。
而这篇文章也将具体教会大家如何在MacBook上部署DeepSeek。
为什么要在本地部署DeepSeek?DeepSeek想必大家多多少少都用过,或者也听说过,它可以在手机或者电脑上通过APP或者网页进行访问,但是有用过DeepSeek的小伙伴应该都会知道,如果你问的问题比较复杂,或者问的比较频繁,经常会出现系统繁忙的提示,而本地部署就可以一定程度缓解这个问题。

另外对于个人用户来说,部分涉密的信息可能不太方便联网发送到DeepSeek后台终端进行处理,这样可能会引发信息泄露,而本地部署可以更好的保证信息的安全性。这些都是DeepSeek本地部署的好处。 废话不多说,我们开始!
提前说明,我个人是通过B站UP主 Mac_张提供的文章视频进行的操作,亲测可以进行本地部署,并完美运行使用,非常感谢大佬的分享,接下来我将我自己本地部署DeepSeek的流程以及一些注意点和大家分享一下。
Mac本地部署DeepSeek及个人知识库搭建教程在正式开始之前,先介绍一下本地部署DeepSeek的几个主角
我的设备:2021款M1Pro Mac 32G+1TB 系统为macOS 15.3(尽可能使用M系列芯片的MacBook,Intel机型可尝试但可能会性能受限,系统版本应为Mac OS12以上)
核心工具:Ollama(本地模型运行)、AnythingLLM(可视化交互界面)
Ollama安装与模型部署首先我们需要请出第一位主角——Ollama,它的作用类似一座桥梁,将DeepSeek数据库与你的电脑连接,从而实现最基础的本地化部署。 访问官网 https://ollama.com,点击Download。

选择macOS版本。点击下载 macOS版的Ollama。

下载之后会得到这样一个压缩包,解压后将解压出来的文件,也就是这个羊驼,拖拽至「应用程序」文件夹


完成安装后菜单栏显示羊驼图标即表示Ollama安装成功了,这时候你的状态栏上就会常驻一只可爱的小羊驼。

接下来我们就要通过Ollama在本地部署DeepSeek模型
首先要明确一下你的MacBook适合什么样的模型规模,模型规模越大说明模型越强大,可以完成的计算越丰富,换言之就越智能,但是越大的模型就需要越强的性能支撑,结合网友和我自己的实际测试,模型规模与推荐配置可以参考下表:
模型规模
参数量
模型数据量
推荐配置
1.5B
15亿
1.1G
M1、M2以上芯片 8GB RAM
7B/8B
70-80亿
4.7/4.9G
M1、M2以上芯片 16GB RAM
14B
140亿
8.9G
M1Pro、M2Pro以上芯片 24/32GB RAM
32B
320亿
20G
M2 MAX/M3Pro以上芯片32/36/48GB RAM
70B
700亿
43G
M2 MAX/M3Pro以上芯片64GB RAM
671B
6710亿
404G
不推荐本地部署
我个人是2021款MacBook Pro 8+14核心 32G+1TB存储规格。最后选择了14B的模型规模,可以完美运行。 一般建议大家布置14B、32B两个模型,毕竟模型规模如果不够,可能就会影响整体的体验。
确认好模型之后,我们需要打开Mac上的终端App,接下来我们将输入相应的模型规模代码将DeepSeek-r1部署到本地。


由于我选择的是14B的模型,所以我输入的是ollama run deepseek-r1:14b,如果是32B的模型就输入ollama run deepseek-r1:32b,在Ollama的网站上也有相应的模型的代码,可以直接复制使用。


代码输入完成之后,点击回车,系统就会开始下载deepseek-r1:14b模型。

下载过程如果觉得有点慢,尤其是接近100%的时候,可以按 Control+C取消,再按方向键上,到最后运行的指令按回车让它重连一次下载可能就会变快一些。数据是支持断点续载的,不用担心下载进度会丢失。
这里额外说一下,如果想换模型可以输入ollama rm deepseek-r1:模型规模
比如原来下载的时7B的模型规模,后来感觉不够用想升级,那么可以输入 ollama rm deepseek-r1:7b,这样7B模型就删除成功了。后续就可以再安装14B或者更好的模型。
当终端对话框中跳出succes,说明安装成功了,这时候已经可以在编程对话框中和DeepSeek进行对话了,不过这个界面确实不美观,接下来就需要第二个软件登场了。
 AnythingLLM配置与界面交互
AnythingLLM配置与界面交互终端相对简陋的界面,肯定不能满足各位股东对美的追求,所以这时候我们就需要第二个软件AnythingLLM,它的作用就是让我们可以获得堪比DeepSeek官网那样的对话体验,同时它还提供了检索增强生成能力,简称RAG,通过它以及后面我们会说到的Embedding模型,我们就可以通过喂给它相关的文件、网站等等,搭建出个人知识库。
下载安装AnythingLLM
访问官网 https://anythingllm.com,点击Download for desktop。

选择MacOs系统,如果是M系芯片选择第一个如果是intel芯片选择第二个。

下载完成后就会得到相应的dmg文件。

双击打开将Anything LLM拖拽至Applications即可完成安装。

完成了两个软件以及DeepSeek数据模型安装之后,基本上就已经完成一大半了,接下来我们需要将DeepSeek与LLM进行配置。双击打开Anything LLM后,第一步选择模型,找到Ollama 选择绑定已下载的DeepSeek模型。 点击右侧箭头。

跳过登录直接进入工作区创建。

命名一个工作区,这里我就以账号的名称进行命名。

接着我们就会进入到Anything LLM的界面,为了方便使用,我们先点击左下角的扳手进入设置页面。

点击Customization在Display Language项目中将English改为Chinese。
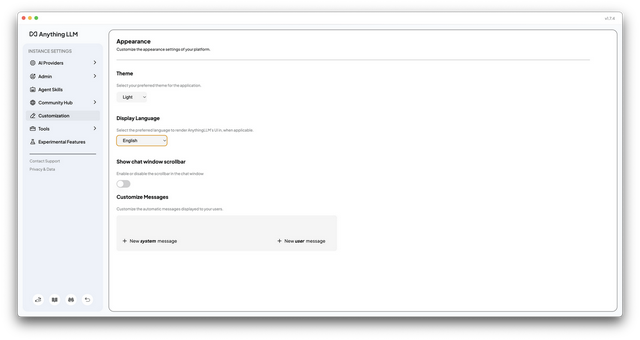
这样我们的界面就会是中文界面了,这会大大方便各位股东的使用体验。

这时候我们的本地Ai工具就已经基本部署完毕了,在不连接网络的情况下也可以进行问题的解答。
 个人知识库搭建
个人知识库搭建当然每个人都想拥有一个属于自己的AI知识库,让AI通过我们投喂的文档来进行回答,比如我想让AI对于相机的相关问题做一个解答,那我就可以新建一个“相机解答”工作区。
然后我们就要引入第三个角色——Embedding模型。它负责将你上传的文件拆分成块,转化成AI能理解和调用的形式,这类模型其实也非常多,按照大佬Mac_张的推荐,我也采用了BGE-M3模型。
下载BGE-M3模型: 再次打开终端App,在其中输入:ollama pull bge-m3后回车,系统会下载BGE-M3模型


看到success后就表示BGE-M3模型下载成功了。

下载完成后进入AnythingLLM再次点击左下角的扳手进入设置,
点击Embedder首选项,选择 Ollama在点击选择 bge-m3 最后一定要点击保存更改。这时候底部就会出现相应的提示,表示保存成功。

接下来进入第二步创建知识库工作区,我将新的工作区命名相机解答,随后点击上传。

无论是上传PDF/文档/网页都可以,上传完成之后点击右下角的Save and Embed。
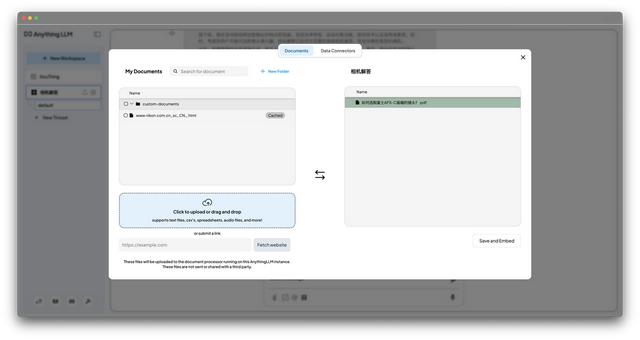
这样他就可以基于你提供的文档来进行相应的回答了,投喂的越多,回答就越精准,适合对文献进行归纳总结,或基于文档进行写作分析。

当然如果回答超出了提供文档的范围,AI可能就会开始放飞自我,如果想要严格控制AI的回答,可以点击工作区的齿轮图标,点击聊天设置,先将聊天模式改为查询,让大模型仅能从你提供的文档中尽可能寻找答案。接着我们要调整一下聊天提示,这相当于你给大模型立的一个人设。

设置完成后在窗口左侧找到对话历史记录,点击这个Clear Chats再点击OK,清空一下AI的记忆。这样他的回答会更加的准确。
 总结与进阶方向
总结与进阶方向以上就是Mac本地部署DeepSeek及个人知识库搭建的教程啦,感谢你看到这里,再次感谢大佬MAC_张的分享,通过本教程。
相信你已经实现:
✅ DeepSeek模型本地部署✅ 可视化交互界面搭建✅ 私有文档知识库集成当然还有些进阶探索也欢迎尝试:
外接硬盘运行:减少本地存储压力。多模型切换:尝试Meta-Llama、Qwen等开源模型。自动化工作流:结合Shortcuts或Automator实现一键启动。除了以上提到的工具外,也可以尝试以下工具:
聊天工具:Chatbox、LM Studio知识库平台:Dify、Ragflow、Cherry Studio