临床数据是任何疾病诊断过程中的初始阶段。
电子健康记录(EHR)代表着海量的异质数据。电子病历包含临床信息,如诊断、操作、临床记录中的信息和药物。
尿液是发现生物标记物的一种很有前途的替代体液。它是公共诊断筛查测试的理想液体,因为患者可以很容易地以完全非侵入性、廉价的方式提供大量的液体。
与血液一样,尿液除了含有转录生物标记物miRNAs外,还含有蛋白质组生物标记物。
体液中含有丰富的生物标志物,对PDAC的早期识别至关重要。
血液外切体是携带各种致病rna、dna和蛋白质的纳米大小的细胞外小泡,用于诊断胰腺癌细胞。
尿蛋白组学标志物肌酐、LYVE1、REG1B和TFF1为诊断PDAC提供了一种无创、廉价的新方法。
微流控技术和人工智能技术的最新应用使这些生物标志物的准确检测和分析成为可能。
尽管PDAC是全球第12种最常见的癌症,但其侵袭性和缺乏明显症状使其成为主要的公共卫生负担。
PDAC的早期诊断是生存的关键,在所有恶性肿瘤中,由于诊断较晚,PDAC的5年总存活率最低(11%)。
据2022年癌症统计报告,胰腺癌是世界第三大死亡原因,胰腺导管腺癌(PDAC)是最常见的外分泌癌,治疗需要临床医生、放射科医生、生物学家和计算机科学家齐心协力。
医学影像引导程序是诊断PDAC的基本技术,包括磁共振成像(MRI)、计算机断层扫描(CT)、内窥镜超声(EUS)和免疫正电子发射断层扫描(免疫-PET)。
尽管早期胰腺癌的成像很困难,但最近许多有希望的研究被报道在[6]中。放射成像的高成本使其不太可能成为普通PDAC筛查的选择。
因此,研究人员将注意力转向利用生物标记物作为PDAC早期检测的初步步骤。
基因组测序技术发展迅速,它们的不同策略,如蛋白质组学、表观基因组学和转录组学,产生了大规模的多组学数据。
癌症基因组图谱(TCGA)项目是由国家癌症研究所于2006年建立的。它提供了33种癌症类型的20,000多种肿瘤的多组学数据。
在微观上,一项研究报告了尿中miRNA用于早期检测PDAC。2020年,Debernardi等人提出。通过用REG1B取代REG1A,改进了现有的面板。
此外,他们还可以区分良性肝胆疾病和PDAC病例,由于症状重叠,这两种病例在PDAC的早期阶段具有挑战性。
他们使用PancRISK得分来验证他们的小组。液体活检中生物标志物的准确检测和量化是基于体液的诊断方法成功的基石,而基于体液的诊断方法可以使用基于微和纳米的技术。
微流体和纳米流体技术的快速技术创新使从液体活检中检测出高质量的生物标记物具有高度的特异性和敏感性。
不同的微流控芯片被设计用于不同的体液,如血液和尿液。
微流控技术可以通过分析各种肿瘤生物标志物,如循环肿瘤DNA(CtDNA)、循环肿瘤细胞(CTC)、无细胞DNA(CfDNA)、无细胞RNAs(CfRNAs)、肿瘤分泌外切体和蛋白质来改进癌症诊断。
然而,这些生物标志物的临床解释及其相互关系仍然是一个挑战。
机器学习(ML)和深度学习(DL)技术最近已成为计算机辅助诊断(CAD)的核心技术,可以处理不同形式的临床数据、医学图像、基因组学和生物标志物。
图1显示了基于人工智能的应用程序的通用示意图,该应用程序基于各种形式的输入医疗数据将胰腺患者分为三个主要组,即健康的和两个疾病的良性和PDAC病例。
ML模型可以从患者数据中以有监督或无监督的方式学习,以预测胰腺的健康状态,如先前研究所建议的。
先进的数据挖掘方法可以从医学数据集中复杂、相互关联和非线性的特征中学习,以获得更高的诊断能力。

图1. 利用不同形式的医学数据应用人工智能技术辅助胰腺癌患者诊断的示意图
相关性分析AI如何使用不同的诊断方法支持PDAC的早期诊断。台湾学者的研究建立在台湾健康保险数据库(NHIRD)上。
他们使用了四种模型,包括Logistic回归(LR)、深度神经网络DNN、集成学习和投票集成来开发他们的预测模型。该模型的精度为73%~75%,曲线下面积为0.71~0.76。
有学者提出了一种用于多参数MRI中胰腺大体肿瘤体积(GTV)自动分割的CNN模型。
他们采用了一个基于正方形窗口的CNN架构,该架构带有三个卷积层块,用于胰腺GTV的自动分割。
他们在测试集上获得的性能指标的平均值和标准差为,骰子相似系数(DSC)=0.73±0.09,平均表面距离(MSD)=1.82±0.84 mm。
Chen等人验证了一种新的基于深度学习(DL)的工具,可以在CT扫描上检测胰腺癌,对小于2厘米的肿瘤具有合理的灵敏度。
他们的DL工具区分CT恶性和对照研究的敏感性为89.7%,特异性为92.8%,AUC为0.95%。
此外,EUS成像方式需要实时决策支持来区分胰腺癌(PC)和非胰腺癌(NPC)病变。
建议YOLOv5m将产生诱人的结果,并允许使用EUS图像进行实时检测。该模型的敏感性为95%,特异性为75%,AUC为0.85%。
数据收集方法包括四种典型的尿液生物标志物,即肌酐、LYVE1、REG1B和TFF1。
肌酐是一种表明肾脏功能的蛋白质。YVLE1是淋巴管内皮细胞透明质酸受体1的首字母缩写。
它是一种可能在恶性肿瘤中发挥作用的蛋白质。
第三个生物标志物REG1B也是一种蛋白质,可能与胰腺再生细胞有关。
最后,三叶因子1(TFF1)是一个蛋白质,它可能是一种潜在的预后生物标志物。
该数据集共包含590个尿样。分为三组,即健康组183例,良性组208例,PDAC组199例。
一维卷积神经网络:CNN是提取特征和完成医学分类任务的有效工具。在
这项研究中,通过分析尿液生物标志物的一维数据来识别胰腺疾病。
一维CNN的总体结构包括卷积运算、二次采样、丢弃正则化和SoftMax层,如图2所示。
一般的1D CNN架构的每一层可以描述如下。
卷积和子采样层通过卷积、核和整流线性单元(REU)执行不同的滤波操作来提供输入1D样本的特征检测。
最大池化层执行池化过程以从预定义过滤器覆盖的整体特征地图中选择最显著的特征。平坦层的作用是将多维特征映射数组重塑为单个一维数组,如图2所示。
为了防止神经网络过度拟合,应用了辍学作为一种规则化技术来自修改CNN的结构。然后,利用SoftMax函数对全连通网络层的输出进行处理,得到预测类的最终输出。

图2. 预测n类的一维卷积神经网络的主层
长短期记忆层:由于LSTM网络可以忽略神经网络中对于长序列数据集的无用信息,例如本研究中的尿液生物标志物,因此解决了RNN的梯度消失或长期相关性的主要问题。
LSTM层主要有三个连续的门,即忘记门、输入和输出门,如图3所示。
LSTM块的第三个门是输出门Ot,它确定对长期影响的考虑,并使用Sigmoid和Tanh函数更新当前单元状态Ct和隐藏状态Ht的输出。

图3. LSTM块的基本结构
胰腺癌自动分类
图4. 一维CNN-LSTM用于诊断胰腺癌的智能尿液生物标志物分类
首先,从患者身上提取尿样。其次,利用尿液微流控装置提取上述四种生物标志物,即肌酐、LYVE1、REG1B和TFF1。
然后,这四个尿生物标志物被输入到我们开发的一维CNN-LSTM分类器中,以预测三种类型中的一种,即健康胰腺、良性疾病和PDAC疾病。
如图所示一维CNN-LSTM模型的详细结构层如图5所示。
它包括一个输入数据层、两个一维卷积层、一个最大汇聚层、一个LSTM、一个全连接致密层和最终SoftMax输出层。
一维CNN-LSTM被认为是一个完全可训练参数为83,8111的轻量级深度神经网络。

图5. 用于胰腺癌分类的一维CNN-LSTM模型
癌症模型测试使用交叉验证估计,生成混淆矩阵来评估所开发的一维CNN-LSTM和其他在本研究中测试的模型的PDAC分类性能。
如图6所示,通过比较胰腺实际情况和任何测试分类器的预测结果,混淆矩阵有四个预期结果。这些结果是真阳性(TP)、真阴性(TN)、假阳性(FP)和假阴性(FN)。
此外,还使用了准确率、召回率或敏感度、精确度、F1-Score和AUC等五个评价指标来验证所有测试的分类器的性能。
在这里,我们实现了其他模型,即RF、多层感知器(MLP)神经网络和没有LSTM的一维CNN模型,以与我们开发的一维CNN-LSTM模型的性能进行比较。
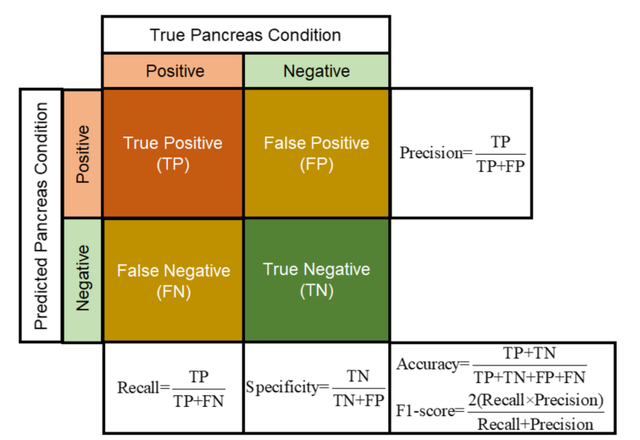
图6.混淆矩阵和评价指标用于分析本研究中测试的分类器的性能
为了开始所有测试模型的训练阶段,尿样数据集被随机分割80%-20%,使得测试阶段使用这些尿样的20%,即,590个样本中的118个,用于完成健康胰腺、良性和PDAC病例的多类分类过程。
图7显示了尿液生物标记物的多分类混淆矩阵,分为健康胰腺、良性和PDAC病例。
这些结果是通过我们的一维CNN-LSTM和三个基于人工智能的模型实现的,这三个模型是MLP神经网络、RF和一维CNN。
所开发的一维CNN-LSTM模型在没有误分类的情况下获得了最高的准确率,但对于健康的胰腺和良性的病例,只有两个尿样被误分类。
在没有LSTM层的情况下,1D CNN模型的分类性能降低,使得对于健康胰腺(3个样本)和良性病例(5个样本)的误分类样本的数量增加,但是对于PDAC没有检测到误分类样本。
MLP神经网络和RF不能准确地处理尿液生物标志物的分类任务,在这些实验中获得了最差的准确率分数。

图7.使用所有测试的分类器对健康胰腺、良性胰腺和PDAC病例进行分类的混淆矩阵
改进的一维CNN-LSTM和一维CNN的准确率仍然最高,分别为97%和93%。可用于PDAC病例的准确诊断。
相比之下,MLP网络和RF分类器的准确率最低,约为75%。但RF模型在识别胰腺状况方面表现出比MLP网络模型更好的性能。
使用相同的尿液生物标志物分析,表3说明了我们开发的1D CNN-LSTM与其他基于人工智能的模型在以前的自动化胰腺癌诊断研究中的比较性能评估。
机器学习模型,如Logistic回归(LR)无法获得RF分类器性能类似的高准确度分数(76%)。
此外,支持向量机(SVM)和神经网络(NN)等其他模型在识别AUC=0.94[40]的PDAC病例方面显示出改进。
在中,应用所采用的CNN模型识别胰腺癌病情的准确率达到95%。
然而,我们开发的一维CNN-LSTM表现出了比以前的分类器更好的分类性能,获得了最优值的分类评价指标和最高的准确率为97%。
人工神经网络在疾病预测中的应用传统的机器学习模型,如LR、RF和支持向量机,如先前在中介绍的那样,表现出不足以准确识别胰腺癌病情的性能。
因此,有监督的一维CNN-LSTM分类器被开发出来,对一维尿液生物标志物进行自动多类分类,正确识别胰腺患者的健康状况。
如上所述,LSTM块的有利架构显示了其忽略神经网络中用于长序列数据集的无用信息的能力,例如尿液生物标记物。
因此,我们开发的模型中的LSTM层。
在将一维CNN的分类性能从93%显著提高到97%方面起到了主要作用。
此外,它的分类性能优于先前的CNN模型(95%的准确率)。此外,所开发的1D CNN-LSTM模型的结构简单有效,能够实现有针对性的诊断过程。
公共医学数据集的缺乏是有监督学习模型训练中普遍存在的问题,因为训练样本的数量主要影响其分类性能。
因此,CNN和机器学习分类器对胰腺癌的准确率分数相对限制在97%。因此,开发深度学习模型,如生成性对抗网络(GAN),为在半监督或非监督学习框架中处理小型医学数据集提供了一个很好的解决方案。
此外,还可以应用元启发式优化技术,例如基于教学的优化(TLBO)来自动更新1D CNN-LSTM模型的设计。
尽管如此,我们开发的分类器仍然能够实现基于尿液生物标记物的胰腺癌疾病的成功和自动化诊断。
参考文献【1】胰腺导管腺癌:分子病理学和预测性生物标志物
【2】我们能筛查胰腺癌吗?使用应用于初级保健数据的机器学习技术识别具有后续诊断高风险的患者亚群
【3】癌症基因组图谱泛癌分析项目
【4】智能医用物联网支持的急性血癌自动显微图像诊断
