
本文由半导体产业纵横(ID:ICVIEWS)编译自chipsandcheese
由于Arrow Lake是高性能桌面处理器,其系统架构更注重性能提升,而非功耗削减。

Arrow Lake是英特尔最新一代高性能桌面处理器的代号。本文将介绍Arrow Lake的系统架构,以及它与Lunar Lake的不同之处。由于Arrow Lake是高性能桌面处理器,其系统架构更注重性能提升,而非功耗削减。

为了进行比较,测评将使用装有Meteor Lake处理器的笔记本电脑的数据,及AMD提供的Zen 5芯片样品。BIOS更新后9900X已经配置在日常用机中,因此它应该能代表那些进行插槽内升级的用户的情况。
芯片配置Arrow Lake是英特尔首款采用多芯片配置的桌面处理器。这与采用单片设计的上一代Raptor Lake芯片有所不同。Arrow Lake的芯片配置与上一代Meteor Lake移动芯片非常相似。CPU核心位于计算芯片上,该芯片采用前沿工艺制造。Arrow Lake的计算芯片采用台积电(TSMC)的N3B工艺。iGPU则拥有自己的芯片,这让英特尔可以在不改变计算芯片的情况下扩展GPU。由于Arrow Lake很可能会与独立显卡配对,因此其iGPU仅包含四个Xe核心,而Meteor Lake则有八个。

来自Hot Chips 34的旧幻灯片,详细介绍了英特尔的多芯片计划。
iGPU和CPU芯片都连接到一个中央SoC芯片上,该芯片负责DRAM访问和与较慢的I/O通信。SoC芯片还包含各种提供重要功能但不需要前沿性能的模块。Arrow Lake的SoC芯片采用台积电更便宜的6纳米工艺,类似于AMD的I/O芯片。与Meteor Lake的SoC芯片相比,Arrow Lake去掉了两个Crestmont低功耗E-Core。

一个未展示的IO扩展器芯片块
与Meteor Lake类似,Arrow Lake也将芯片放置在基片上。跨芯片通信通过基片上的Foveros芯片间互连(FDI)链路进行。这使得英特尔能够实现非常高的线密度。
AMD也采用了一种中心-辐射状的芯片配置,自Zen 2以来一直如此。CPU被放置在核心复合芯片(CCD)上,这些芯片与中央I/O芯片通信。然而,AMD的芯片之间通过封装内的迹线进行通信。除了成本更低外,不使用基片或中介层使得AMD的跨芯片链路具有更远的覆盖范围。对于服务器产品而言,能够将CCD放置在离I/O芯片更远的位置是一个显著的优势,因为AMD在这些产品中会使用多个CCD来达到高核心数。
灵活性与权衡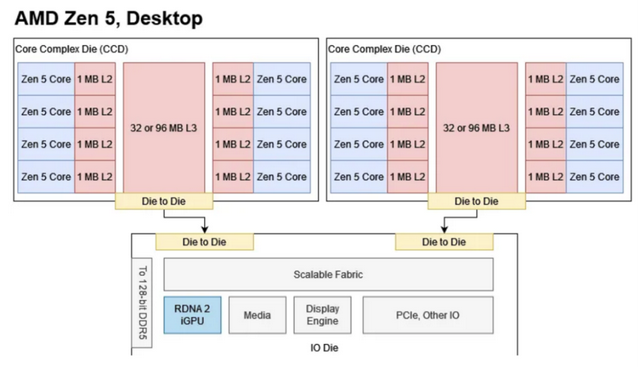
灵活性伴随着权衡,AMD的跨芯片链路并未跟上DDR5的带宽。单个CCD具有每周期32字节的读取带宽和一半的写入带宽。在AMD标准的2GHz Infinity Fabric时钟(FCLK)下,这意味着64GB/s的读取带宽和32GB/s的写入带宽。快速DDR5配置可以远远超过这个带宽,因此,如果一个对带宽要求很高的程序被限制在一个CCD上,它可能会受到这些跨芯片链路的限制。

测得的读取和非时序写入带宽
Arrow Lake的芯片配置以更高的带宽和更低的功耗跨芯片链路为代价换取了灵活性。英特尔在Hot Chips 34上的幻灯片显示,FDI具有约2K的主带宽,并在2GHz下运行,具有良好的功耗效率。Arrow Lake将链路速度略微提高到2.1GHz,这可能进一步提高了带宽和降低了延迟。

如果主带宽指的是数据传输的位宽,那么CPU-SoC链路可能每周期能够传输2048位(256字节)。在2GHz下达到的512 GB/s的带宽,即使在读写分开的情况下也完全过剩。实际的数据位宽有可能小于这个数值,因为一些引脚必须用于传输请求地址、命令和纠错位。

无论如何,Arrow Lake的计算模块(Compute Tile)和SoC模块之间拥有充足的带宽。像AMD芯片上那样的跨芯片带宽限制在Arrow Lake上完全不存在。Arrow Lake的读取带宽接近理论DRAM带宽。写入带宽略低,但仍然非常高,并没有像AMD那样减半。

Arrow Lake的CPU-SoC模块链路是Meteor Lake的改进版。任何一组P核(性能核)都可以完全访问DRAM带宽。AMD通过同时使用两个CCD(计算芯片)也可以实现高内存带宽,特别是在使用调优的Infinity Fabric和DRAM设置的情况下。但就带宽行为而言,Arrow Lake的设置更加单片化。
延迟CPU互连还需要最小化延迟。在这方面,Arrow Lake的芯片设置就不那么令人印象深刻了。超过100纳秒的DRAM加载到使用延迟对于桌面CPU来说是很高的。英特尔过去在DRAM延迟方面没有问题。事实上,即将淘汰的Raptor Lake一代即使在使用较慢的DDR5时也能享受更好的DRAM延迟。过去的设计表明,英特尔知道如何制造低延迟的DDR5控制器。不知道这是否要归咎于英特尔的芯片设置。

Arrow Lake的内存控制器能够在带宽需求不够高时进入低功耗模式,这使得延迟测量变得复杂。然而,如果任何P核处于活动状态,Arrow Lake似乎会立即退出该低功耗模式。只有在低负载下,E核(能效核)才会受到影响,这与Arrow Lake作为性能优先设计的目标是一致的。上面的数据是从Arrow Lake上的一个P核获得的。
高带宽负载会增加DRAM延迟,因为请求开始在内存子系统的各种队列中积压。因此,带宽密集型的代码可能会影响在其他核心上运行的延迟敏感型代码的性能。可以通过在运行延迟测试线程的同时生成带宽密集型的线程来调查这些“嘈杂邻居”效应。
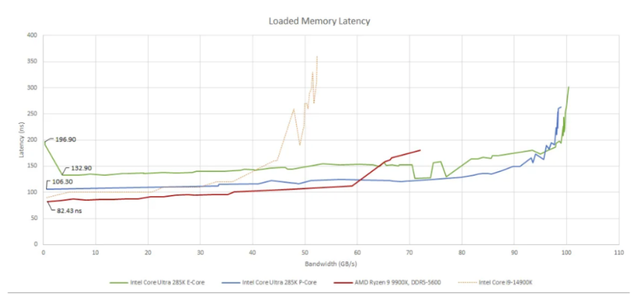
E核的DRAM延迟较高,可能是因为除非有足够的DRAM流量或P核处于活动状态,否则Arrow Lake的内存控制器会保持在低功耗模式。
Arrow Lake没有AMD那样的CCD到IOD(输入输出芯片)的瓶颈。然而,直到带宽需求超过60 GB/s时,英特尔的优势才显现出来。在此之前,AMD较低的基线延迟意味着即使内存流量很大,它也能更快地从DRAM返回数据。在之前的一篇文章中,运行在Zen 4上的游戏并没有接近60 GB/s的需求,且平均L3缓存未命中延迟保持较低。Arrow Lake的高延迟、高带宽内存子系统可能非常适合于高度并行的生产力工作负载,如图像处理。但延迟敏感且线程数少的任务可能表现不佳。
核心到核心的延迟CPU的内存子系统还必须让所有核心对内存有一个一致的视图,尽管每个核心都有自己的私有缓存。如果一个核心读取了另一个核心最近写入的地址,内存子系统可能需要进行缓存到缓存的传输,而不是从共享缓存或DRAM中加载数据。Arrow Lake将所有CPU核心放置在计算模块内,因此缓存到缓存的传输不需要跨越芯片边界。此外,英特尔还优化了E核集群,允许在同一L2复杂体内进行缓存到缓存的传输。Arrow Lake的Skymont E核在这个“核心到核心”延迟测试中取得了优异的结果。

然而,Lion Cove P核的表现就不那么好了。P核之间的最坏程度的延迟可能接近AMD芯片设计中跨CCD的延迟。考虑到AMD需要跨越两个芯片边界来进行跨CCD的缓存到缓存的传输,这一结果很有趣。

这些Zen 5的结果是在改进了核心到核心延迟的BIOS更新之后获得的。
Arrow Lake的高核心到核心延迟部分可能源于其长长的环形总线。每个P核都有一个环形总线站点,每个四核E核集群也有一个。再加上跨芯片传输的另一个环形站点,Arrow Lake的环形总线可能有13个站点。但延迟在Arrow Lake的P核之间最为严重,因此环形总线的长度只是问题的一部分。
Lion Cove的缓存设计可能也起到了很大作用。缓存一致性协议确保只有一个核心可以将特定地址缓存为修改状态。因此,在这个测试中,请求的核心将在其所有私有缓存级别中未命中。当拥有修改数据的核心收到探测时,它必须检查其自己的所有私有缓存级别,既要读出修改后的数据,又要确保该地址从其自己的缓存中无效。Lion Cove从两级核心私有数据缓存增加到三级,增加了过程中的一个步骤。

回顾一下 Lunar Lake 的情况,可以为这一理论提供支持。Lion Cove 在那里也观察到了较高的核心间延迟,尽管 Lunar Lake 的环形总线仅为四个核心提供服务。Lunar Lake 还显示出较高的跨集群延迟,尽管这些传输并没有跨越芯片边界。内存子系统在逻辑层面处理缓存一致性操作的方式,可能比物理芯片边界产生更大的影响。而 Lunar Lake 可能就是一个很好的例子。
Arrow Lake的缓存:更大,并不总是更快作为高性能部件,Arrow Lake为其P核和E核提供了更多的缓存容量。过去几十年来,DRAM延迟并没有跟上CPU核心性能的提升,因此缓存对于提高CPU性能至关重要。有了更多的缓存容量,Arrow Lake的核心希望能够花更多的时间进行计算,而不是停滞等待DRAM中的数据。
L3容量从Lunar Lake的12MB增加到Arrow Lake的36MB。自Sandy Bridge以来,英特尔一直使用由连接到每个环形停止点的切片组成的L3缓存,而Arrow Lake有12个带有核心的环形停止点。这意味着每个切片的容量仍然像Lunar Lake一样保持为3MB。关联度也保持不变,为12路。

然而,更长的环形总线和更高的L3容量导致了更高的延迟。在Arrow Lake上,从P核到L3的加载到使用延迟超过了80个周期,相比之下,Lunar Lake上的延迟约为52个周期。这种周期计数的惩罚非常高,以至于尽管Arrow Lake的时钟频率更高,但其实际的L3延迟仍然高于Lunar Lake。

AMD的Zen 5像之前的Zen系列一样享有非常低的L3延迟。AMD的每个CCX都有32MB的L3缓存,使其容量与Arrow Lake的L3相当。然而,AMD为每个CCX使用单独的L3缓存。这使得L3设计更容易,因为每个L3实例服务的核心数量更少。但对于低线程工作负载来说,这是对SRAM容量的低效利用,因为单个线程只能分配到32MB的L3缓存,尽管9900X芯片上有64MB的L3缓存。

与Lunar Lake相比,Arrow Lake的L3带宽有所提高,这可能是由于核心和环形总线时钟频率的提高。然而,与AMD相比,带宽仍然较低,这种情况已经持续了几代。在英特尔的产品线中,单个P核的L3带宽并没有超过九年前Skylake所达到的水平。Skylake核心的Core i5-6600K可以以59.5GB/s的速度从L3读取数据。
L3带宽对于多线程负载更为重要,因为一个L3实例服务于多个核心,带宽需求随着活动核心数量的增加而增加。通常通过让每个测试线程从单独的数组中读取数据来测试多线程带宽,这可以防止内存子系统将请求合并到同一个地址。然而,这样做会让CPU在每个L2实例中缓存不同的数据,因此,在测试数据量显著超过总L2容量之前,无法获得良好的L3性能估计。Core Ultra 9 285K拥有40MB的L2和36MB的L3。如果每个线程都使用私有数组,那么没有任何测试数据量能够完全适应L3,而超过一半的访问将由L2提供服务。

为了检查请求是否被合并,测评监控了Zen 5的L3性能事件,并验证了L3命中带宽与软件观察结果紧密匹配。但无法在Arrow Lake上执行相同的操作,因为英特尔尚未发布性能监控事件。但Zen 5的行为是一个好兆头,表明请求是在L3之后合并的,而不是在L3之前。
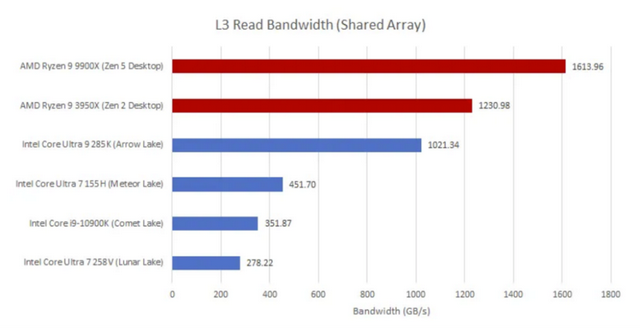
英特尔的L3性能已经落后于AMD几代,但Arrow Lake是一个显著的改进。与延迟不同,延迟会随着环形总线的延长而恶化,而L3带宽会随着L3切片的增加而提高。不同的L3切片可以独立处理请求,这在许多核心向L3发出请求时非常重要。与拥有8个环形停止点的Meteor Lake相比,Arrow Lake有12个环形停止点,并且时钟频率也更高。这使得L3带宽提高到略高于1TB/s,是Meteor Lake所能达到的两倍多。
然而,英特尔仍然未能在绝对意义上赶上AMD。即使像Ryzen 9 3950X这样的旧款16核AMD产品也享有更高的L3带宽。当前一代的Ryzen 9 9900X则领先两者一大截。结合AMD更低的L3延迟,Arrow Lake的L3看起来并不那么出色。但是,需要从整个缓存层次结构的角度来看待英特尔的L3性能。Arrow Lake的P核将其L2容量增加到3MB,而E核集群则保留了与Lunar Lake相同的4MB大容量L2。相比之下,AMD使用的是较小的1MB L2缓存,因为L2未命中的代价较低。

Arrow Lake也应该与Lunar Lake相比较来看。Lunar Lake上的Skymont核位于远离环形总线的低功耗岛上,即使请求是由Lunar Lake的8MB内存侧缓存服务的,也会看到较高的L2未命中延迟。Arrow Lake不需要E核来在低强度任务期间降低功耗,而是专注于使用它们来提高多线程性能。为此,Skymont集群像先前几代的标准E核一样,重新回到了环形总线上。拥有一个L3,即使是一个较慢的L3,也比什么都没有要好得多。

总的来说,Arrow Lake大致延续了先前几代使用的缓存策略。之前的Raptor Lake和Alder Lake也有不尽如人意的L3性能,但通过比AMD对手更大的L2缓存来弥补。英特尔还拥有更大的核心,可以在指令停滞的情况下进一步向前推测,使它们在面对长加载延迟时能够保持良好的吞吐量。AMD在这方面也没有太大不同。Zen 4将L2容量翻倍至1MB,显著减少了平均L3流量。最近的Arm服务器芯片也使用大容量(1或2MB)的L2缓存来减轻L3延迟的影响。因此,其他CPU制造商也在利用工艺节点改进的优势,将更多数据保存在离核心更近的地方。Arrow Lake比其他架构更依赖于L2容量,因为它需要在L3相对较慢的情况下提供高单核性能。
时钟速度时钟速度仍然是提高CPU性能的重要杠杆,与提高每时钟性能的架构变化相辅相成。Arrow Lake的Lion Cove和Skymont核心的时钟速度都比Lunar Lake上的要高,这对于更高功耗、更高性能的设计来说是预料之中的。Core Ultra 9 285K的两个Lion Cove核心可以达到5.7GHz。其余核心可以达到5.5GHz。所有Skymont E核的运行频率最高可达4.6GHz。
Skymont的时钟速度特别值得关注,因为它在绝对意义上相当高,即使它还没有达到当前一代桌面P核的时钟速度。仅仅几年前,AMD的Zen 2最高可达4.7GHz,但并非所有核心都能达到这一频率。英特尔的E核在某些方面已经赶上了上一代的P核,时钟速度就是这样一个方面。

与Arrow Lake相比,AMD的Ryzen 9 9900X在一个CCD内的时钟频率非常均匀。第一个CCD上的所有核心都可以运行在5.6 GHz,而第二个CCD上的所有核心则运行在5.35 GHz。如果你选择了正确的核心,Arrow Lake的时钟频率可以更高,达到5.7 GHz,但这一代AMD和英特尔的高性能核心运行在非常相似的时钟频率上。尽管AMD的更多核心能够达到最高时钟频率,但操作系统必须根据预期的性能等级对核心进行分类,以优化低线程工作负载。
最后总结过去几年,英特尔一直在忙于对其产品线进行从上至下的调整。英特尔早期辉煌时代所标志的大型单片芯片已被更具灵活性的芯片组件设计所取代。正如Meteor Lake将芯片组件引入英特尔的笔记本电脑产品一样,Arrow Lake也在台式机上做了同样的改变。这两款英特尔客户端芯片都采用了与AMD类似的中心-辐射型芯片组件拓扑结构。而且两家公司都可以为每个芯片选择最合适的节点。然而,除此之外,AMD和英特尔的芯片组件策略则有所不同。

英特尔仍然专注于构建具有单片芯片感觉的设计。这种设计具有诸如更统一的带宽特性或保持缓存间传输在同一芯片内等优势。但变革往往伴随着挑战。Arrow Lake在DRAM(动态随机存取存储器)延迟方面有所倒退,如果应用程序的工作集溢出缓存,那么DRAM延迟就是一个重要的指标。变革还会消耗工程时间,而在一件事上投入工程时间就意味着在其他方面的机会成本。英特尔可能没有足够的工程时间来改进其他方面,如L3(三级缓存)的性能或容量。
希望随着英特尔在不同市场细分领域部署小芯片的经验日益丰富,他们将开始收获小芯片重用和工艺节点灵活性带来的好处。在Meteor Lake和Arrow Lake之后,初始的小芯片设计工作难关已被攻克,或许英特尔会发现他们有充足的工程资源来解决L3缓存和DRAM延迟问题。如果他们能做到这一点,英特尔庞大的乱序执行引擎将能大放异彩。
*声明:本文系原作者创作。文章内容系其个人观点,我方转载仅为分享与讨论,不代表我方赞成或认同,如有异议,请联系后台。

好有技术含量的文章
说了这么多还是为垃圾性能的intel吹水,这代英特尔除了功耗其他都完败,没有什么疑问,当然amd乘机涨价3d缓存处理器,美国制芯片里面隐藏了什么鬼玩意也是有他们自己知道,我的意见是全部不要买,等他们毁灭