你有没有发现,现在的“智能”产品越来越多,但真正能让人觉得“靠谱”的好像没几个?
动不动就“一本正经”地胡说八道,简直让人哭笑不得。
就拿最近火热的多模态大模型来说,个个号称“全知全能”,但一测下来,emmm…有点意思。
大模型集体翻车?
想象一下,你问一个号称“视觉专家”的大模型:“这照片里是啥?”它自信满满地回答:“一只蓝色的猫!”结果照片里明明是一只灰色的兔子…这尴尬不尴尬?

最近,淘天集团未来生活实验室搞了个大事情,他们发布了一个名为ChineseSimpleVQA的中文视觉问答基准测试,专门用来考察这些大模型的“眼力”和“脑力”。
结果嘛,就像一场大型翻车现场,各种“自信式错误”层出不穷。
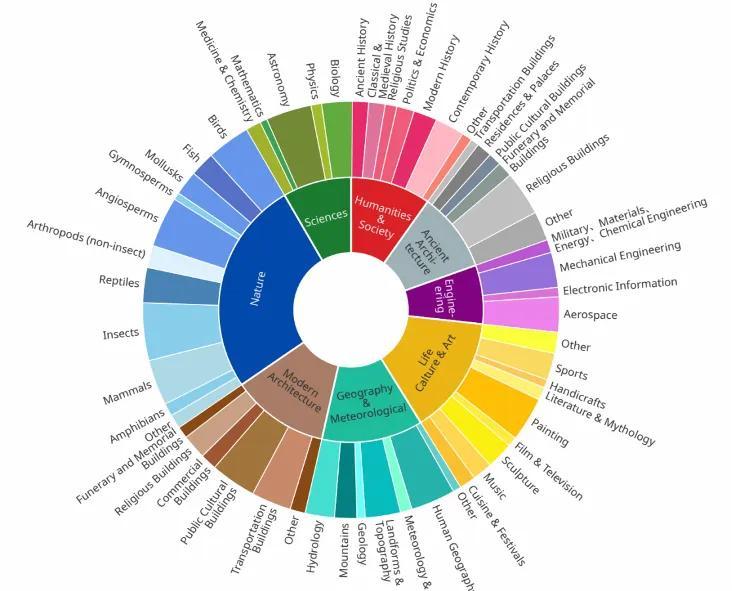
这个测试可不简单,包含了2200个高质量问题,涵盖了人文、科学、工程等各个领域,可以说是对大模型进行了一次全方位的“摸底考试”。
结果显示,大部分模型都存在“过于自信”的问题,明明答错了,还觉得自己是对的,这可真是让人捏一把汗。
谁在裸泳?
那么,在这场“考试”中,谁在裸泳呢?
结果显示,OpenAI的o1-preview表现最佳,这多少让人有点意外。

它在图像主体识别和知识扩展方面都表现出色,其次是Gemini-2.0-pro-flash和Gemini-1.5-pro。
而在注重中文能力的模型中,Qwen-VL系列表现最为突出。
不过,即使是表现最好的o1-preview,也远未达到完美。
研究团队发现,大多数模型在知识扩展方面都存在困难,也就是说,它们能识别出图片中的物体,但很难理解这些物体背后的深层含义。
举个例子,它们可能知道照片里是一座桥,但却不知道这座桥的历史背景和文化意义。
o1凭什么第一?
那么,o1凭什么能在这场“考试”中脱颖而出呢?

难道它有什么独门秘籍?
其实,这背后并没有什么神秘的魔法。
研究团队发现,模型规模越大,表现通常越好。
例如,Qwen2-VL系列从2B增至72B后,最终问题的准确率就有了显著提升。
这意味着,想要提升大模型的性能,最直接的方法就是增加模型的参数量,让它拥有更强大的计算能力和存储能力。
当然,这并不是唯一的因素。
模型的训练数据、算法设计等也会影响其最终表现。
但不可否认的是,规模越大,潜力越大。

大模型也爱吹牛?
除了知识扩展方面的不足,研究团队还发现,幻觉问题仍然是多模态大模型领域的一个重要挑战。
简单来说,就是模型会“无中生有”,自信满满地提供错误信息。
这种现象在其他模型中尤为明显,这也提醒我们,在使用大模型时,一定要保持警惕,不能完全相信它们的话。
那么,为什么大模型会如此“自信”呢?
这可能与它们的训练方式有关。
在训练过程中,模型会不断地学习和模仿,但它们并不真正理解知识的含义。
当遇到不确定的情况时,它们可能会倾向于猜测,而不是承认自己不知道。
这种猜测往往会导致错误的答案,但模型却意识不到。
那么,我们该如何解决这个问题呢?
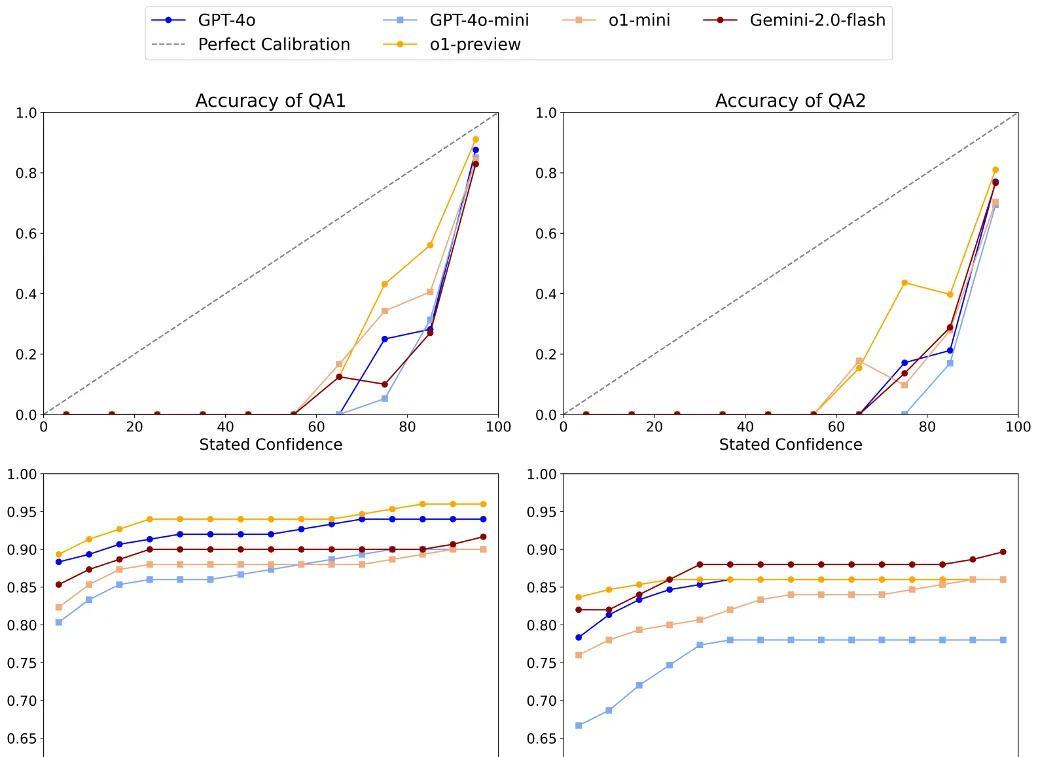
一个可能的解决方案是,让模型在回答问题的同时给出其置信度,让用户知道它的回答有多靠谱。
研究团队也尝试了这种方法,结果显示,o1-preview在这方面表现最佳,但总体而言,大部分模型的表现都远低于理想对齐线。
换句话说,即使回答错误,模型也倾向于过于自信。
这表明,我们还需要在模型校准方面做更多的工作,让它们能够更准确地评估自己的能力。
这场关于多模态大模型事实正确性的评估,就像一面镜子,照出了当前人工智能领域的种种问题和挑战。

虽然大模型在某些方面取得了显著进展,但它们仍然存在很多不足,尤其是在知识扩展、幻觉问题和模型校准方面。
不过,我们也不应该因此而对人工智能失去信心。
毕竟,任何一项技术的发展都需要经历一个不断试错和完善的过程。
只要我们能够正视问题,积极探索解决方案,相信在不久的将来,我们一定能够创造出更加智能、可靠的人工智能系统。
这场“考试”也给我们带来了一些新的思考。
我们究竟应该如何评估一个人工智能系统是否“靠谱”?
仅仅看它的准确率够不够高吗?
还是应该关注它的知识深度、推理能力和伦理道德?

或许,我们应该像对待一个孩子一样,既要鼓励他们学习新知识,又要引导他们形成正确的价值观。
只有这样,我们才能培养出真正有用的、负责任的人工智能系统。
未来的世界,注定是人与人工智能共存的世界。
我们应该学会如何与它们和谐相处,充分发挥它们的优势,同时也要警惕它们的潜在风险。
只有这样,我们才能共同创造一个更加美好的未来。
也许有一天,大模型不再是“自信过头”的学渣,而是真正能够帮助我们解决问题的智能伙伴。
到那时,我们就可以放心地对它们说:“这次,你终于靠谱了!”

