其实,很多人认为Java是一种“落后”的编程语言,性能不高,效率低下。
一天,Gunnar Morling在他经常去的一个编程论坛上,看到了这样的评论。
他不禁心生一计,这个想法让他自己都激动不已:不如来一次Java编程挑战,看看能不能消除这些偏见。

挑战背景:为何举办十亿行数据编程挑战?
Gunnar Morling是Decodable公司的软件工程师,同时也是Java Champion。

他不仅热爱开源,还常常在各种技术大会上发表演讲。
在日常工作之外,他还热衷于探索编程的新领域。
每六个月Java就会有新版本发布,带来新的API和功能,想要及时跟上确实不容易。
为了学习新东西,并为社区提供一个实际的练手平台,他策划了这场“十亿行数据编程挑战”。
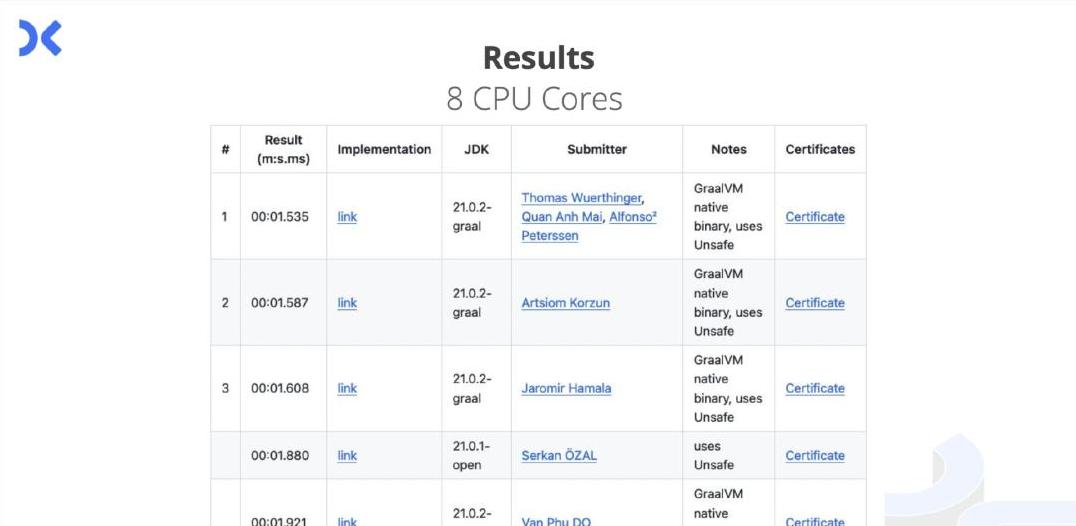
任务听上去简单,但绝对有趣:处理一个包含10亿行温度测量值的文件,并汇总出每个站点的最小值、最大值和平均值。
这个文件大小足足有13GB,如何在最短时间内完成这一任务呢?

规则也很简单,限制在Java语言里,没有外部依赖,大家只能用纯粹的Java代码完成。
技术细节:处理十三GB文件用时不到两秒的秘诀Gunnar首次尝试是利用Java Streams API,结果处理这个文件花了大概五分钟。
虽然不算糟糕,但显然有更大的优化空间。
接着,他通过并行调用,使时间缩短到71秒,但还是不够好。
于是,他开始使用新的Java外部内存API,内存映射把文件处理分成多个块,在多核CPU上并行处理。

八核处理快速提升了性能,但Gunnar不满足。
他继续优化,最终实现了在1.5秒内处理完所有数据。
秘诀之一是避免使用正则表达式,而是逐字符处理,达到比初始实现快一个数量级的效果,还利用了Java向量API和具体的CPU特性来加速处理。

并行化策略:如何充分利用多核CPU加速处理?
并行化是提升性能的重要手段,尤其是面对如此庞大的数据集。
Gunnar用的机器有32个核心,为了避免单线程CPU的瓶颈,他将文件分割成多个块,交由不同的线程处理。
通过合理分配块大小,使线程均匀工作,避免空闲核浪费资源。
他还注意到了CPU缓存和内存访问题,找到合适的块大小以提升I/O效率。

分块处理过程中,每当一个工作线程完成,它会自动接手下一个待处理的块,确保所有资源得到充分利用。
最终,在32核机器上,Gunnar把处理时间缩短到300毫秒,这是个令人惊叹的成就。
优化技巧:从基础到高深的性能提升方法
除了并行化,Gunnar还使用了一些更深层次的优化技巧,例如SIMD(单指令多数据)。
利用Java向量API,他可以一次处理多个值,大大提升了效率。
这个API能够利用底层CPU指令集进行向量化操作,使得逐字节比较变得非常快速。

大部分编程者可能并不会去用这些冷门技术优化日常工作中的程序,但了解其中的原理,显然对提升编程技巧有帮助。
另外,Gunnar意识到,针对特定数据集的优化也非常有效。
很多人针对他提供的示例数据,做出了非常具体的哈希函数优化,虽然这有些违背他的初衷,但也不可否认其有效性。

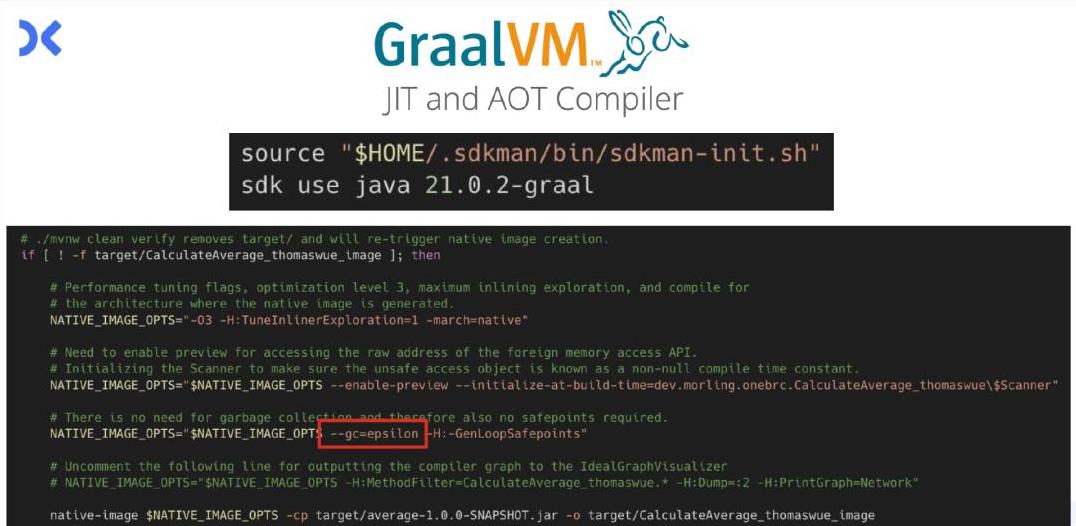
他还尝试了GraalVM作为JIT和AOT编译器,发现这种组合可以显著提升启动速度和整体性能。
启示:这场挑战带给我们的思考这场挑战不仅是一次技术上的探讨,更是在实践中打破了一些关于Java的偏见。

Gunnar通过不断的实验,证明了Java在处理大数据集方面同样具有优异的性能。
回头来看,这场挑战不仅带来了很多新知识,也让人们意识到,往往被认为“不可能”的事,如果去尝试,依然有很多潜力可挖掘。
就像Gunnar所说的,编程是不断学习和实践的过程,通过这次挑战,他和社区成员们不仅提升了技能,还在思考和解决问题的过程中,拓宽了视野。

这也许正是“十亿行数据编程挑战”真正的意义所在——技术不仅是工具,更是我们探索和认知世界的一种方式。
这次挑战不仅让我们见识到技术的强大,也让我们深刻意识到,面对困难和挑战,不妨多一分耐心与创新,往往能获得意想不到的惊喜。
希望这场关于Java的极限挑战,能激发更多人的探索热情,在编程的道路上不断前行,发现更多的可能性。

Java慢吗?
或许我们现在有了更好的答案。
