
说起来,人工智能模型一直是大家茶余饭后讨论的热门话题。
上周,业界又迎来一个大新闻——GPT-4.5 发布了。
想到以前的旗舰产品 ChatGPT,让许多人感到惊艳,但这次,有位工程师在使用后,却带着疑惑和不满提交了一篇详尽的评测报告。
他的结论竟然是——“垃圾”。
听到这话的时候,我不禁心生疑惑,怎么一个新发布的高端模型就成了“垃圾”呢?
为了弄明白到底发生了什么,我决定好好钻研一下这篇颇具争议的报告。

首先我们来看价格。
这位工程师一开篇就提到,GPT-4.5 的定价让人难以置信:每月 Pro 用户需要支付 200 美金,而 API 的使用价格更是高达每百万 token 输入 75 美金,输出 150 美金。
这个价位真的是相当惊人。
当时我看到这些数字,心里打了个冷颤。
要知道,竞争对手 Claude 3.7 Sonnet 的价格低得多,仅是 GPT-4.5 的一个零头,而 DeepSeek R1 在输入和输出上的花费,也远远低于 GPT-4.5。

这么高昂的价格,真让人怀疑 OpenAI 是不是在卖黄金。
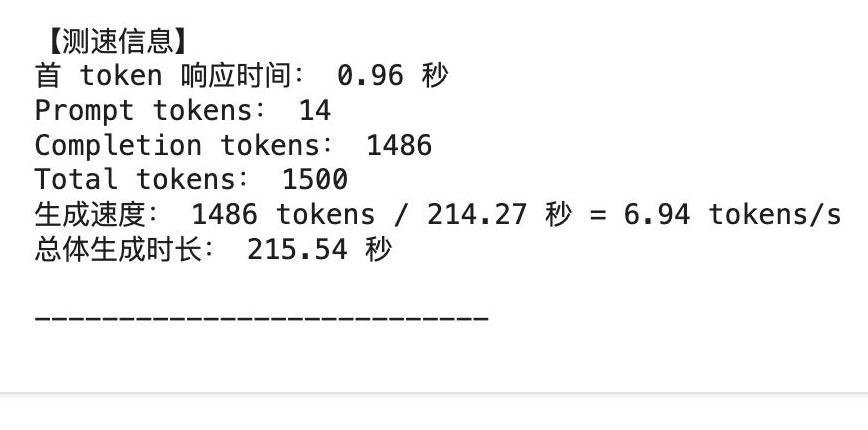
速度测试结果展示接下来,我们再说说速度。
工程师做了一个小实验:让 GPT-4.5 生成一篇 1486 tokens 长的短文,结果竟然花了足足 214.27 秒,也就是说,每秒只能生成不到 7 tokens。
要知道,在这个快节奏时代,谁还愿意等待这么久!
与其竞争对手相比,GPT-4.5 简直就是慢得无法容忍。

试想一下,如果你要在实际工作中使用这么一个模型,而它的速度慢得让人抓狂,估计谁都会感到沮丧吧。
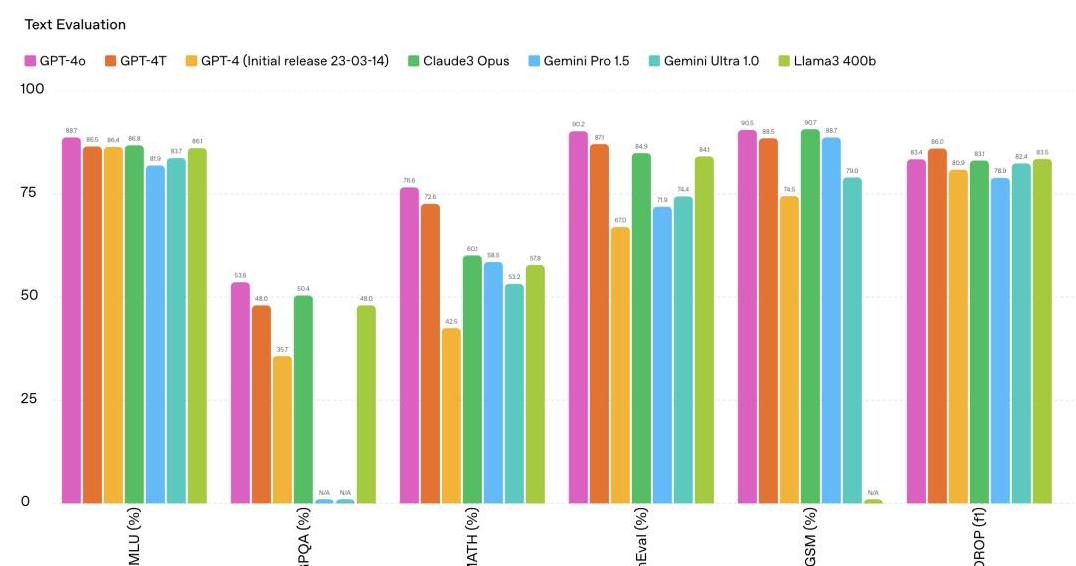
性能不及预期不仅如此,工程师还发现,GPT-4.5 在实际使用中的表现也令人失望。
回想一下 GPT-3 和 GPT-4 那些令人惊叹的生成内容,GPT-4.5 的生成质量并没有显著提升,反而显得更加迟钝和生硬。
这让人感到很失望。
要知道,AI 模型的核心竞争力就在于其生成内容的自然性和流畅性。

但这次 GPT-4.5 虽然在生成文风上努力模仿,但实际效果却不尽如人意。
例如,让它模仿秦代风格撰写一篇文章,出来的结果让人感觉中规中矩,甚至有些机械化。
相比之下,DeepSeek R1 在同样的任务中表现得更加自然流畅。
实际应用中的问题那么,实测下来 GPT-4.5 的表现到底如何呢?
工程师讲的一个实例非常切合实际。

在一个具体的业务应用中,他们尝试用 GPT-4.5 来进行文本生成工作。
本以为这是一个提高效率的好机会,结果却发现生成速度慢得惊人,而且内容质量也远不如预期。
例如,让 GPT-4.5 根据一个提问生成回答,既耗时又费力,结果还不如他们手工编辑的内容精准。
当时听到这,我心想,如果是我花这么多钱用一个速度慢、表现差的工具,肯定也会大发脾气。
这篇评测报告不仅仅详细描述了产品的不足之处,还用具体的数据和实例来佐证他的观点。
不可否认,工程师用心良苦,但遗憾的是,GPT-4.5 并未达到大家的期望。
而这也反映出一个更深层次的问题——科技产品的开发,不能单单靠营销和宣传,更需要扎扎实实的技术突破。
结论和反思综合以上几个方面的评测,我们不得不问:GPT-4.5 是不是确实“名不副实”?
从定价到实际表现,这款产品显然还有很大改进空间。
我们不能否认 OpenAI 在人工智能领域的贡献,但这次发行显然给我们提了个醒——追求高技术水平和用户体验的同时,也要注意产品的实际性能和用户反馈。
总结来说,我们期待着科技能够带来更多便捷和惊喜,但同时也希望这些高科技公司能够实实在在地解决问题,而不是只追求商业利益和市场份额。
希望未来的 GPT-5 能够吸取前面的教训,我们拭目以待。
通过这篇评测,或许对整个行业都是一个警示。
无论是用户、开发者还是企业,都应该更理性地看待新技术——不能一味追求高价高端,“接地气”的性能和体验才是王道。
如果回到根本,人们不需要天花乱坠的宣传,实在的好产品自然能获得市场的认可。
让我们一起期待,下一次,不再是失望,而是实至名归的惊喜。
