前面文章中,关于Python解释器在模块导入行为背后所执行的操作,已经做了深入的介绍。本文打算在此基础上,结合实际代码案例,进行进一步的补充说明。同时,比较看似只是微小的导入方式的改变,可能会导致的难以理解的异常问题。
本文的主要内容有:
1、关于命名空间
2、模块导入对命名空间的影响
关于命名空间有关于命名空间的介绍,前面已经很详细了,对此仍然不太熟悉的,可以翻看一下上一篇文章。这里,主要想就在Python中如何查看、操作命名空间做进一步的说明。
命名空间的作用,主要是用于进行代码中“名字”与对象之间绑定关系的存储。
所谓执行模型,更像是代码在命名空间上执行,从而实现对Python中对象模型的访问及修改。
所以,代码执行过程中,对名称的解析、对象的定位,都是基于命名空间来实现的。
在Python中我们可以通过几个内置函数查看命名空间的相关内容,前面已经简单提及,这里再回顾一下:
1、globals():查看当前全局命名空间的字典
2、locals():查看当前局部命名空间的字典
3、dir():返回当前代码所在范围的所有名字列表
可以先看下这几个内置函数的文档说明:

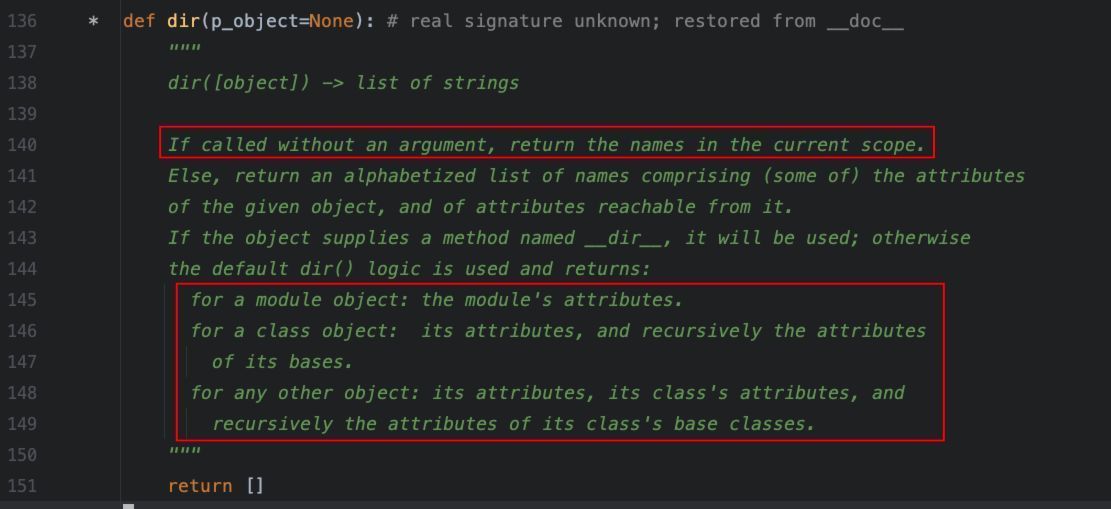

接下来,我们通过实际代码来看下,这几个内置函数的使用。
首先看代码执行前后全局命名空间的变化,直接看代码:

执行结果如下:

从执行结果可以看到,我们在代码中定义的变量和函数,都会把名称和对应的对象存储到全局命名空间的字典中。
需要说明的是,当我们在顶级代码块中,使用locals()函数时,返回的命名空间与globals()返回的是一样的,也就是都是该模块的全局命名空间。
感兴趣的,可以自行把代码中的globals()切换为locals()。
当locals()函数在函数体内进行调用时,则能看到真实的函数内部的局部命名空间中的名称及对象的绑定关系:

执行结果:

从执行结果中可以看出,虽然add()函数的局部命名空间中只有n1和n2两个名称,但是执行到return a + n1 + n2时,并不会报错,且成功返回了我们期望的10 + 5 + 10 = 25的结果。
所以,当函数调用时,会创建局部命名空间。函数体中的代码会在局部命名空间上执行,如果在名称解析的过程中,如果遇到局部命名空间中不存在的名称,则会去更高层级的命名空间去查找,查找顺序遵循LEGB规则。
如果我们稍微调整一下add()函数体的代码,尝试修改全局变量a的取值:

执行结果:

从代码中可以看出,我在顶级代码块中定义了一个全局变量a,在函数add中尝试修改全局变量a,其实并没有成功。
因为add函数体中,a = 1000这行代码,默认是在局部命名空间中执行,所以会在局部命名空间中创建一个新的名称对象绑定关系。所以,对比前面一个程序的运行结果,局部命名空间中多了一个a局部变量的名称对象绑定。
虽然全局命名空间中也有同名的变量a,但是在函数的区局作用域中,会优先查找局部命名空间来进行名称解析。
现在陷入了一个尴尬的点,我们想要修改全局变量,却导致了在局部命名空间中新增了一个局部变量。
其实有两种做法可以实现在局部作用域(也就是函数体中),对全局变量的修改。
先来看比较粗暴的做法,既然我们的意图是修改全局变量,而全局变量的名称对象绑定是存储在全局命名空间中,那么我们直接尝试修改全局命名空间中的字典,是否就实现了对全局变量的修改呢?
可以通过如下代码来验证:

我们将add()函数体中,a = 1000的代码,变换为:globals()['a'] = 1000。
看下执行结果:

从执行结果看出,这种做法,确实直接修改了全局命名空间中a变量,而且没有在局部命名空间中,引入新的局部变量,从而实现了我们的目的。
我们也可以不通过定义变量,直接通过这种操作全局命名空间字典的方式,引入新的变量,感兴趣的同学,可以自行尝试。
之所以说,这种做法比较粗鲁,一方面是因为有点繁琐,另外一方面也不太安全,稍有不慎,会影响后续代码中的命名解析。
其实,Python中有更简单的做法,就是通过global关键字,来声明变量为全局变量,代码如下:

执行结果,跟粗鲁的做法是完全相同的,这里就不再贴出来了。
此外,dir()函数,不传参时,能直接获取当前作用域中可见的名称列表,这里就不再演示了。
模块导入对命名空间的影响接下来看一下,模块导入会对命名空间产生怎样的影响。
首先,我们定义一个m1.py的模块,代码如下:

然后,我们在入口文件中导入该模块,代码如下:

执行结果如下:

可以看到,通过import m1的方式导入模块,在全局命名空间中只增加了一个m1的模块名与模块对象的绑定关系。虽然我们在模块m1和入口文件中,有同名的全局变量a和add()函数,但是模块中的是通过m1.的前缀访问的。所以,可以各自访问,并不会有冲突或者覆盖的情况。
但是,如果导入方式调整为 from m1 import a, add
代码如下:

执行结果:

从执行结果中,可以看出,通过from m1 import a, add的方式进行导入时,全局命名空间中原有的名称a和add的绑定关系发生了变化。也就是入口文件中定义的变量a和函数add()已经被覆盖。
同时会发现,不同于通过m1.a = 1000进行模块m1中全局变量的修改,这里m1中的变量a直接被加入到了入口文件的全局命名空间,所以,a = 1000,并没有影响函数add()的计算结果,因为没有真正修改add()函数中引用的m1.a变量的取值。这点,是需要格外注意的。
总结本文首先介绍了命名空间相关的补充内容,然后演示了模块导入对命名空间的影响。需要注意的有这几点:
1、当在顶级代码块或者全局作用域中,globals()和locals()获取的命名空间字典都是相同的,都是该模块的全局命名空间。
2、在函数体内或者局部作用域中,globals()是全局命名空间,locals()则是真正的局部命名空间,只有函数的形参及函数体内定义的变量。
3、要在局部作用域中修改全局变量,可以通过globals()['变量名'] 的方式进行修改,也可以通过global关键字的方式进行修改,推进使用后一种方法。
4、import 模块名的方式,只会在全局命名空间中添加模块名与模块对象的名称绑定关系,所以,不会导致命名冲突或者相互覆盖的情况。
5、from 模块名 import xxx的导入方式,会导致模块中具体的变量名、函数名等添加到全局命名空间中,如果已经存在相同的名称,则会覆盖。最终的结果是,最后一次导入的真正生效,之前的都会被覆盖掉。此外,当模块中的函数需要访问模块中的全局变量时,此种导入方式,会导致无法修改模块全局变量的情况,需要特别注意!
感谢您的拨冗阅读,如果对您学习Python有所帮助,欢迎点赞、关注。

