在工业制造的精密齿轮中,质量检测如同校准齿距的关键环节,直接决定了整个生产系统的运转效能。传统质检模式长期受制于人工经验的局限性、规则化检测的僵化性,以及复杂工业场景的动态性,难以满足智能制造时代对效率与精度的双重诉求。DLIA工业检测系统通过深度学习算法与非监督学习框架的深度融合,构建了“无标注数据自主探索”的能力。

工业质检场景中,缺陷类型的多样性与不可预知性往往超出人类经验的覆盖范围。传统监督学习依赖大量标注数据,但在实际生产中,缺陷样本的稀缺性、标注成本的高昂性,以及新缺陷模式出现的随机性,成为制约模型泛化能力的瓶颈。非监督学习通过挖掘数据内在结构与分布规律,无需预先定义缺陷类别即可识别异常,这一特性使其天然适配工业环境的复杂性。
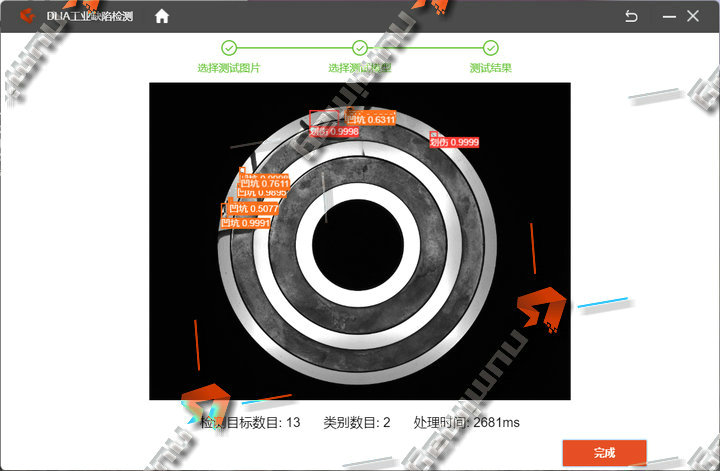
DLIA工业检测系统依托非监督学习构建的动态特征空间,能够自动捕捉产线数据中的潜在异常信号。例如,在金属表面检测中,系统通过分析正常样本的光泽度、纹理一致性等特征,建立多维度的“正常基准”,任何偏离此基准的像素簇均被识别为潜在缺陷。这种基于数据分布差异的检测方式,不仅避免了对缺陷类型的先验假设,还能发现人类难以察觉的微观异常,显著扩展了质检的认知维度。

随着全球经济竞争的加剧、科技的迅猛发展以及消费者需求的日益多样化,相较于全球机器视觉行业而言,中国的机器视觉相关产业起步较晚,但发展速度很快。自2011年到2019年,我国机器视觉市场从10亿元跃升到百亿级,每年都维持着两位数的增速。目前,中国已成为仅次于美国和日本的世界第三大机器视觉市场。未来,随着多模态学习、边缘计算等技术的深度融合,DLIA系统或将进一步突破现有质检边界,推动制造业向零缺陷、自适应、可持续的目标持续迈进。
