
作者 | 陈家阳
编辑 | 漠影
智东西4月18日消息,通义万相首尾帧生视频模型Wan2.1-FLF2V-14B昨日宣布开源,用户仅需上传两张照片作为首帧和尾帧,就能得到一段5秒720p的高清视频。
该模型还可以开启灵感模式,通过AI智能扩写对视频创意进行描述,提升画面丰富度与表现力,从而满足用户更可控、更个性化的视频生成需求。
用户当前可以登陆通义万相官网免费体验新发布的首尾帧生视频模型,也能到 Github、Hugging Face或魔搭社区(Modelscope)下载该模型进行二次开发,解锁更多创意可能。
此外,凭借14B的参数量,该模型成为全球首个百亿参数规模的开源首尾帧生视频模型。
一、细节处理、情感表达、各种运镜,都不在话下通义万相在官方公众号推文中放出了几个新鲜的演示案例,展示出新模型出色的工作能力。

▲提示词:“黑暗的环境,一群人站成一列,背对镜头,站在一束光前,镜头上移,俯拍出光源全貌。”

该模型可以真实地还原物理规律,在光源出现时,地面上的人影会随着光束移动而发生变化。
在复杂的动态场景中,通义万相首尾帧生视频模型也能做到对内容细节进行高精度处理。比如女孩的衣服会随着跑步时的肢体动作而出现褶皱、深褐色的头发在光线影响下不时变换颜色等,让视频看上去更加逼真。

▲提示词:“写实风格,一个身穿粉色运动服的女生在城市街道中跑步,镜头先特写女生的脸部,然后记录下女生转过街角向前跑去的背影。”

当生成首尾帧衔接画面时,通义万相首尾帧生视频模型能够根据不同运镜方式对视频场景进行丰富和完善。

▲提示词:“漫画风格,黑暗中,一个男人正在看向一束光,镜头逐渐拉远,展现出四周都是楼梯的环境全貌。”

通义万相首尾帧生视频模型也可以满足用户对视频情感表达的诉求。

▲提示词:“卡通风格,一个打着红色雨伞的蓝色卡通人物站在雨中。它的眼神充满忧郁。”

此外,通义万相首尾帧生视频模型可以自主优化提术语指令,帮助创作者快速生成创意视频,降低使用门槛,使更多用户能够轻松生成高质量的视频内容。
二、通义万相2.1首尾帧生视频模型是如何训练的Wan2.1系列模型均采用DiT(Diffusion in Transformer)架构,将扩散模型的生成能力与Transfomer模型的特征提取和长序列处理能力相结合,并通过VAE视频压缩让视频生成过程兼顾清晰度和工作效率。
Wan2.1还借助Full Attension机制,使得生成视频在时间和空间上都具有很高的一致性,不会出现时间上动作跳跃、不连贯,或者空间上物体异位、形态变化不合理等情况。
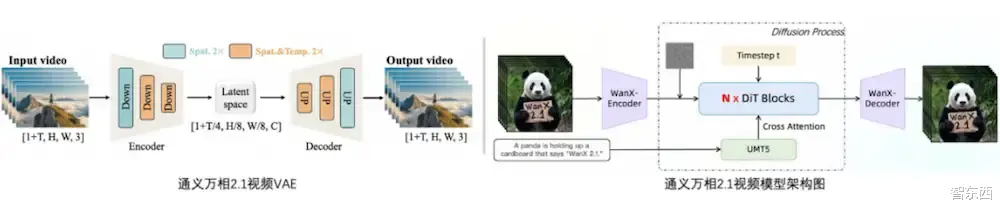
▲通义万相模型结构图
在Wan2.1系列模型的基础架构上,通义万相首尾帧生视频模型新增了条件控制分支,以用户上传的首、尾帧照片作为控制条件,实现了视频从首帧到尾帧丝滑准确的过渡效果。
此外,该模型还提取了首帧和尾帧的CLIP语义特征,并将处理结果反馈到DiT的生成过程中,保证模型生成首尾帧衔接画面时的稳定性。

▲通义万相首尾帧生视频模型架构图
在训练和推理阶段,通义万相首尾帧生视频模型采用了线性噪声轨迹的流匹配(Flow Matching)方法,用于处理噪声和优化视频生成过程,使高精度的视频切片训练成为可能。
为在有限内存下支持高清视频推理,通义万相首尾帧生视频模型使用了模型切分策略和序列并行策略。通过多种优化在保证推理效果无损的同时,大幅缩短了推理时间。
通义万相首尾帧生视频模型的训练过程总共经历了三个阶段,从480p分辨率下的混合任务训练,到针对首尾帧生成能力的专项优化,最后在720p分辨率下完成高精度训练。
结语:首尾帧生视频模型为使用者提供更多创作自由度相较于文生视频和单图生视频,首尾帧生视频具有更强的可控性,用户可以自主决定开头和结尾画面,并通过提示词指令对生成内容进行描述。
但这无疑提高了训练首尾帧生视频模型的难度,既要实现画面从首帧到尾帧的流畅衔接,又要满足视频本身的质感和自然表现。
通义万相首尾帧生视频模型不仅可以实现对图像细节的高精度处理,还能生成和谐自然的动作视频,展现出了强大的技术优势和创新性,开源后将为图生视频领域带来更多价值。
