最近这段时间,有一个新名词在AI圈里迅速走红,那就是——超节点。
在各大展会论坛上,超节点频繁亮相。行业大佬们也纷纷摇旗呐喊,认为它将是智算发展的重要趋势,迎来一波发展热潮。
那么,到底什么是超节点呢?我们为什么会需要超节点呢?
今天这篇文章,小枣君就给大家做一个深入解读。
█ 什么是超节点?
超节点,英文名叫SuperPod,是英伟达公司最先提出的概念。

大家都知道,GPU是重要的算力硬件,为AIGC大模型的训推提供了有力的支撑。
随着大模型参数规模的不断增长,对GPU集群的规模需求,也在不断增长。从千卡级到万卡级,再到十万卡级,将来甚至可能更大。
那么,我们该如何构建规模越来越大的GPU集群呢?
答案很简单,就是Scale Up和Scale Out。
Scale Up,是向上扩展,也叫纵向扩展,增加单节点的资源数量。Scale Out,是向外扩展,也叫横向扩展,增加节点的数量。
每台服务器里,多塞几块GPU,这就是Scale Up。这时,一台服务器就是一个节点。
通过网络,将多台电脑(节点)连接起来,这就是Scale Out。

先说说Scale Up。
对于单台服务器来说,受限于空间、功耗和散热,能塞入的GPU数量是有限的,一般也就8卡、12卡。
塞入这么多块GPU,还要考虑服务器的内部通信能力是否能够支持。如果GPU互连存在瓶颈,那么就达不到Scale Up的预期效果。
以前,计算机内部主要基于PCIe协议,数据传输速率慢,时延高,根本无法满足要求。
2014年,英伟达为了解决这个问题,专门推出了自家私有的NVLINK总线协议。NVLINK允许GPU之间以点对点方式进行通信,速度远高于PCIe,时延也低得多。

图片来自:英伟达官网
NVLINK原本只用于机器内部通信。2022年,英伟达将NVSwitch芯片独立出来,变成了NVLink交换机,用于连接服务器之间的GPU设备。这意味着,节点已经不再仅限于1台服务器了,而是可以由多台服务器和网络设备共同组成。
这些设备处于同一个HBD(High Bandwidth Domain,超带宽域)。英伟达将这种以超大带宽互联16卡以上GPU-GPU的Scale Up系统,称为超节点。
历经多年的发展,NVLINK已经迭代到第五代。每块GPU拥有18个NVLink连接,Blackwell GPU的总带宽可达到1800GB/秒,远远超过PCIe Gen6的总线带宽。

2024年3月,英伟达发布了NVL72,可以将36个Grace CPU和72个Blackwell GPU集成到一个液冷机柜中,实现总计720 PFLOPs的AI训练性能,或1440 PFLOPs的推理性能。

英伟达GB200 NVL72机柜(来自英伟达GTC大会直播)
█ 超节点,有哪些优点?
说到这里,大家可能会提出疑问——为什么一定要搞超节点呢?如果Scale Up这条路线不好走,我们就走Scale Out路线,增加节点数,不也能做出大规模GPU集群吗?
答案很简单。之所以要搞超节点这种加强版的Scale Up,是因为在性能、成本、组网、运维等方面,能带来巨大优势。
Scale Out,考验的是节点之间的通信能力。目前,主要采用的通信网络技术,是Infiniband(IB)和RoCEv2。
这两个技术都是基于RDMA(远程直接内存访问)协议,拥有比传统以太网更高的速率、更低的时延,负载均衡能力也更强。
IB是英伟达的私有技术,起步早,性能强,价格贵。RoCEv2是开放标准,是传统以太网融合RDMA的产物,价格便宜。两者之间的差距,在不断缩小。
在带宽方面,IB和RoCEv2仅能提供Tbps级别的带宽。而Scale Up,能够实现数百个GPU间10Tbps带宽级别的互联。
在时延方面,IB和RoCEv2的时延时延高达10微秒。而Scale Up对网络时延的要求极为严苛,需要达到百纳秒(100纳秒=0.1微秒)级别。
在AI训练过程中,包括多种并行计算方式,例如TP(张量并行)、 EP(专家并行)、PP(流水线并行)和DP(数据并行)。
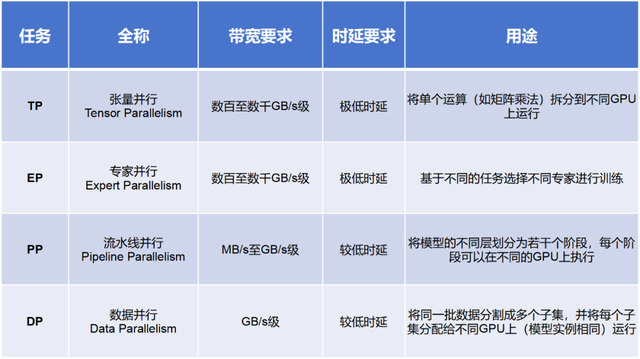
通常来说,PP和DP的通信量较小,一般交给Scale Out搞定。而TP和EP的通信量大,需要交给Scale Up(超节点内部)搞定。
超节点,作为Scale Up的当前最优解,通过内部高速总线互连,能够有效支撑并行计算任务,加速GPU之间的参数交换和数据同步,缩短大模型的训练周期。
超节点一般也都会支持内存语义能力,GPU之间可以直接读取对方的内存,这也是Scale Out不具备的。
站在组网和运维的角度来看,超节点也有明显优势。
超节点的HBD(超带宽域)越大,Scale Up的GPU越多,Scale Out的组网就越简单,大幅降低组网复杂度。

Scale Up & Scale Out组网示意图
超节点是一个高度集成的小型集群,内部总线已经连好。这也降低了网络部署的难度,缩短了部署周期。后期的运维,也会方便很多。
当然,超节点也不能无限大,也要考虑本身的成本因素。具体的规模,需要根据需求场景进行测算。
概括来说,超节点的优势,就是增加局部的带宽,减少增加全局带宽的成本,以此获得更大的收益。
█ 超节点,有哪些可选的方案?
正因为超节点拥有显著的优势,所以,在英伟达提出这一概念后,立刻受到了业界的关注。也有很多厂商,加入到超节点的研究之中。
当前,业界主流的超节点方案,主要包括如下几种:
一、私有协议方案。
代表厂商,当然就是英伟达。
除了英伟达之外,国内大厂华为,前段时间高调发布的AI核弹级技术——CloudMatrix 384超节点,也属于私有协议。
CloudMatrix 384以384张昇腾算力卡组成一个超节点,在目前已商用的超节点中单体规模最大,可提供高达300 PFLOPs的密集BF16算力,接近达到英伟达GB200 NVL72系统的两倍。

华为CloudMatrix 384超节点(来自华为云生态大会)
二、开放组织方案。
有私有协议,当然就会有开放标准。互联网时代,开放解耦是大势所趋。
私有协议往往意味着高昂的成本。对于AI这个热门方向来说,发展开放标准,有利于降低行业门槛,帮助实现技术平权。
目前来看,超节点的开放标准还不止一个,但基本上都是以以太网技术(ETH)为基础。因为以太网技术最成熟、最开放,也拥有最多的参与企业。

从技术的角度来看,以太网具有最大交换芯片容量(单芯片51.2T已商用)、最高速Serdes技术(目前达到112Gbps),交换芯片时延也很低(200ns),完全可以满足Scale Up的性能要求。
在超节点开放标准中,其中比较有代表性的,是由开放数据中心委员会(ODCC)主导、中国信通院与腾讯牵头设计的ETH-X开放超节点项目。

这个项目一共有30余家产学研机构共同参与。其中,既包括运营商(中国移动)、云厂商(腾讯等),也包括设备商(锐捷、中兴等)、算卡提供商(燧原科技、壁仞科技等)商,以及高速互连技术方案提供商(立讯技术等)。
我们来简单了解一下ETH-X开放超节点的技术细节。
ETH-X基于以太网技术构建大带宽、弹性可扩展的HBD,具备高算力密度、高互联带宽、高功率密度和高能效等特点。
值得注意的是,ETH-X不仅包括了Scale Up,也包括了Scale Out。典型的组网拓扑,如下图所示:

ETH-X网络架构图(来自ODCC)
根据腾讯在2024开放数据中心大会提供的数据,基于ETH-X超节点,在训练场景下,LLama-70B稠密型模型在64K集群下的性能/成本进行对比,采用256卡的Scale Up,比8卡的Scale Up低了38%的训练成本。
在推理场景下,LLama-70B在FP4精度128卡实例推理性能/成本对比中,256卡的Scale Up比8卡的Scale Up增加了40.48%的推理收益。
这个效果还是非常不错的。
目前,ETH-X超节点技术规范1.0已经发布。不久前(4月8日),ETH-X开放超节点项目在华勤技术东莞智能制造基地,举行了首台原型机的下线点亮仪式。

图片来自ODCC
我们再来看看ETH-X开放超节点的实物架构。
AI Rack整机柜是ETH-X超节点的具体实现方式。整机柜内Serdes速率目前最高支持112Gbps,未来支持到224Gbps。
机柜包括计算节点、交换节点和关键组件。

AI Rack整机柜布局(来自ODCC)
整机柜内部可以实现多GPU间NOC(Network-on-Chip)级通信拓扑,通过统一内存编址与内存语义接口,支持跨GPU直接访问(Direct Access)与零拷贝传输(Direct Copy)。
根据实际测试的数据,跨卡数据访问时延能够降低12.7倍,动态重构8~512卡超节点的弹性组合单元。
在关键组件中,Cable Tray特别值得关注。

Cable Tray(图片来自:立讯技术公众号)
ETH-X超节点AI Rack采用机柜铜连接方案。而Cable Tray,就是实现各个子系统硬件互通的高速铜缆方案,也是提供高速互连能力的重要连接器硬件。
英伟达的最新NVLINK方案,也用的Cable Cartridge方案。在短距传输场景,相对于光纤,机柜内采用铜连接,可以实现高可靠性和低成本(减少了光模块的使用),也有利于布线。目前看来,在Scale Up内部使用铜缆直连技术,已经是一个主流趋势。
█ 最后的话
好啦,以上就是关于超节点的全部介绍。大家都看懂了没?
随着AI浪潮的继续发展,业界对超节点的需求会变得越来越强烈。更多的厂商,将会加入到相关的开放标准中。这将有力推动相关技术和标准的成熟,带来更加繁荣和多元的生态。
超节点,未来可期!
