
当你坐在舒适的沙发上,用手机与ChatGPT侃侃而谈时,你或许未曾想过,这背后的技术链条有多么复杂。
就像我们欣赏一座精致的建筑,常常忽视了其坚实的地基。
现今,人工智能模型如GPT的热度不断攀升,但支撑这些庞大模型运行的基础设施却鲜为人知。
DeepSeek Infra的故事或许能揭开一些神秘的面纱。

想象一下,一个沉浸于广阔大海中的无人岛,它拥有独特的生态系统,运作着独有的规律。
大语言模型就像这个岛屿,自成体系,功能强大。
而DeepSeek Infra,就是支撑这个模拟的岛屿,让它在竞争激烈的科技海洋中屹立不倒。
这其中,最为基础的,便是优化运行速度的硬件方案。

DeepSeek Infra对显卡的选择极为挑剔,究竟为何对特定显卡有如此执念?
这不仅仅是为了追求性能,更是基于对效率和兼容性的深刻理解。
在DeepSeek Infra的世界里,显卡并不仅仅是数据处理的工具,而是决定成败的关键角色。
DeepSeek Infra的开源与创新DeepSeek Infra项目的一大亮点在于其开源的决策。

开源不仅是为了圈粉技术圈,也是一种培育创新的策略。
这种开放的做法让全球的开发者可以共同参与、贡献智慧,从而促成了更多意想不到的创意碰撞。
这种参与感与协作不仅提升了技术水平,也促进了技术透明化。
当技术不再是少数人的专利,而成为全世界的共享智慧时,创新就变得有了更大的意义。
DeepSeek Infra正是通过这种无边界的合作,实现了其创新的再上升。

这个开源项目如何优化模型训练?
那么,像DeepSeek Infra这样的项目在优化模型训练方面具体做了哪些努力呢?
可以用这样一个形象的比喻来说明:就好比为一场盛大宴会准备食材,如何让每道菜尽可能地保持新鲜香味,这是DL(Deep Learning)技术团队需要解决的难题。
在这个开源项目中,挑战之一是优化每一个细节,以减少计算资源浪费。
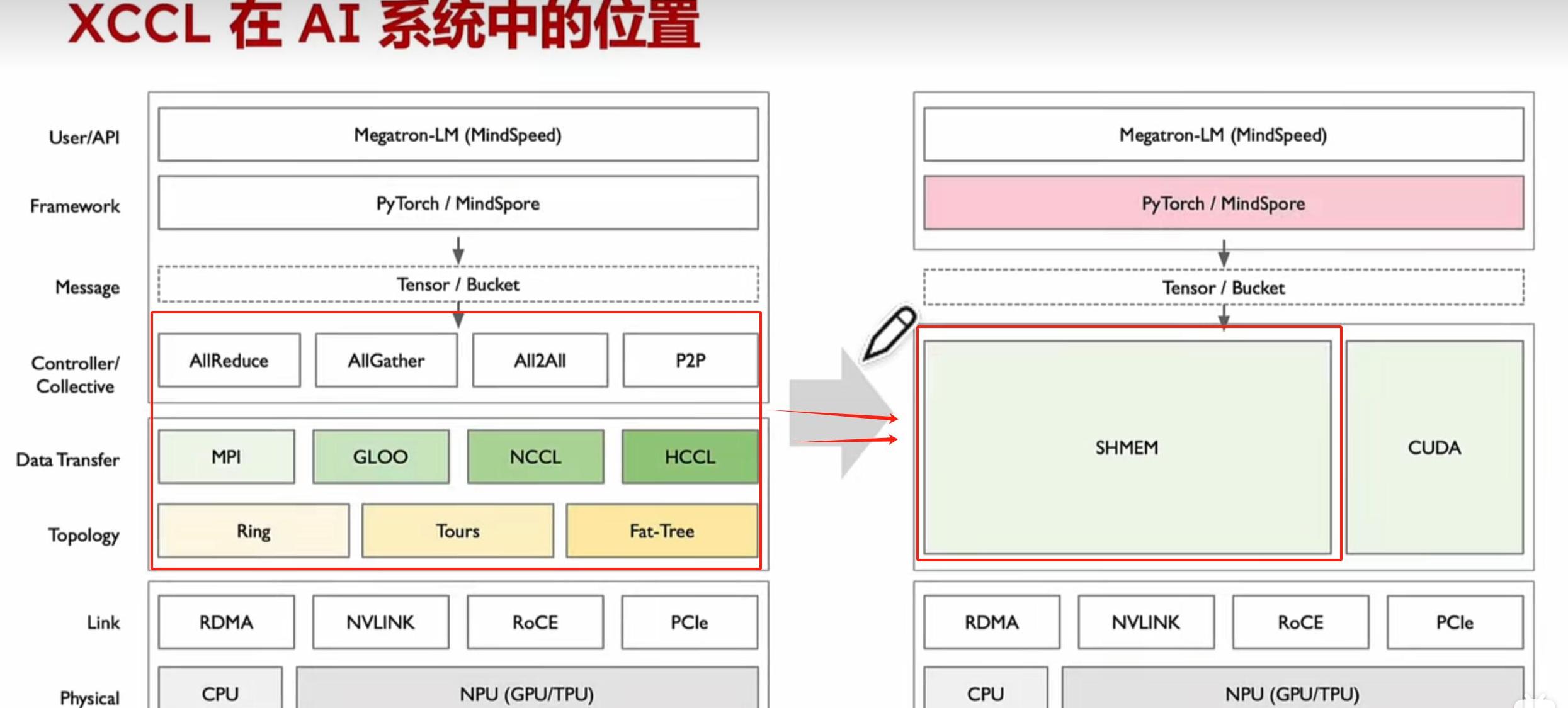
比如,利用KV缓存的分块技术让数据处理更有效率。
这种对缓存和存储的精确管理,正如在物流行业中,对运输线路的精细安排一般,减少了不必要的停顿和浪费。
分块与共享内存的深度利用分析对于计算资源的利用,DeepSeek并未止步于表面之上。
他们深入到科技的底层,努力榨取每一分硬件潜力。

与其说是对技术的追逐,不如讲是对资源精打细算的热爱。
通过共享内存和分块技术,DeepSeek实现了更快、更高效的计算。
这不仅是一组冰冷算法的优化,而是赋予了科技更多的温情和生命力。
在这个环节中,他们通过高度利用高性能硬件中的共享内存,就像无缝衔接的乐章,使得每一个计算单元都能够在他适合的委员会中大显身手。
结尾:
一项伟大的技术,不仅在于它能解决当下的问题,更在于它能为未来打开新的可能。
在深度学习成为技术焦点的今天,DeepSeek Infra选择以开放和创新的心态迎接挑战,这是它最大的胜利。
这些悠远的进步仿佛是在告诉我们,科技的真正意义,不是去攀比冷冰冰的算力和效率,而是在不经意间改变了生活的方方面面。
所以,下次当你与人工智能愉快交谈时,不妨多想一想这些幕后的科技奇迹,或许它们正悄悄影响着你我未来的生活方式。
