丽丽和她的同事们正坐在公司会议室里,讨论着最新的研究成果。
一份报告显示,现在的人工智能能在许多任务上表现出色,但要真正达到通用人工智能的水平,仍然任重而道远。
大家热烈地争论着,是说AGI离我们近在咫尺,还是遥不可及?

丽丽深吸一口气,回忆起团队刚完成的一项复杂实验,这让她有了更多思考。
探讨 Agent 极限的实验几个月前,丽丽团队决定做一个看似简单但极具挑战性的实验。

屏幕上出现了一串混乱的字符,任务是从中抽取一个语法正确的英文句子。
她们对任务做了些调整,对字符进行着色处理,以帮助观察员更快识别出正确的句子。
实验的目标是测试现有最先进的人工智能系统,如GPT-4,能否完成这一任务。

令人惊讶的是,即使是GPT-4这种高级模型,也会犯细微却关键的错误,比如遗漏字母或者单词拆分不准确。
当时,丽丽怀疑,是不是所有的AI都有这些局限?
为了评估实验结果,她们参考了HuggingFace和Meta设计的评估基准,包括三个难度级别的测试。

人类能在这个基准上取得接近完美的成绩,但即使是最先进的系统,也难以接近这一水平。
她们的团队却能在测试集上获得不错的分数,这让她们备受鼓舞。
Agent 和 LLM 的底层细节解析
在搞清楚Agent和大语言模型(LLM)的底层原理后,丽丽明白了为什么现有的模型会犯错误。
说到LLM的结构,其实并不复杂。
例如,Transformer架构通过Encoder和Decoder部分实现了信息的编码和解码。

而其中最关键的是Attention机制,它在不同的Token之间找到相关性,从而提高精确度。
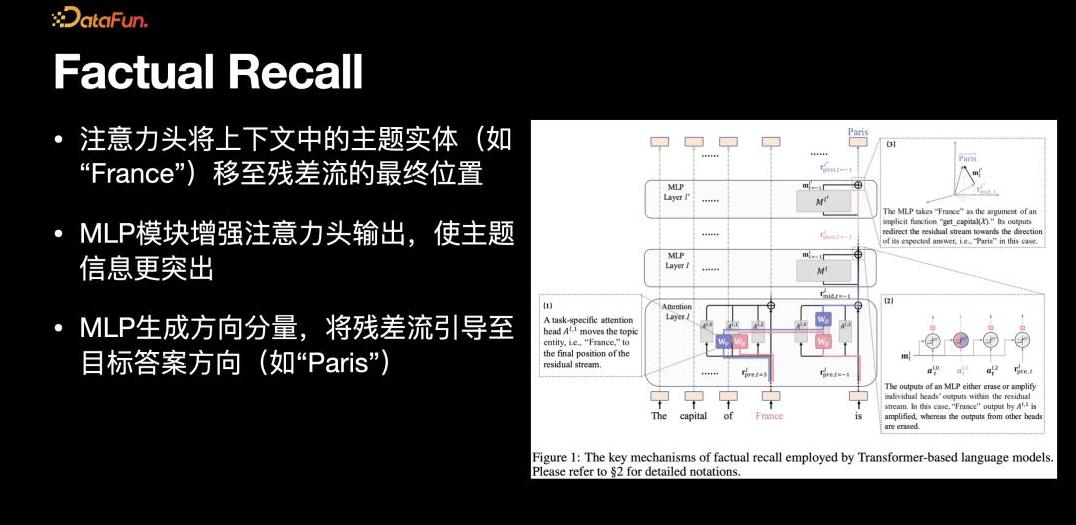
特别有趣的是,一位实习生的研究展示了模型在存储特定知识时的位置,通过这种解释性分析,她们能更好地理解模型是如何存储和应用知识的。
比如“法国的首都是什么”这样的问题,如何在模型内被逐层处理,最终生成答案。

这种深入到细节的探索,不仅让她们看到模型的强大之处,也发现了其局限性。
模型在推理过程中依赖的上下文学习能力,通过注意力机制实现,但这种能力也有极限。
从 Agent 到 AGI 的挑战
当团队尝试从一个测量基准出发,探索从Agent到AGI的实际距离时,发现挑战巨大。
现有最优秀的Agent方案的得分仅达到三四十分,而人类的得分接近九十分。
这六十分的差距表明,模型和人类的聪明程度显然不同。

比如,AlphaGo在围棋上击败了人类顶尖选手,但这并不意味着它在其他任务上也同样出色。
OpenAI关于AGI的定义和评估标准,给了她们一些启发。
丽丽团队的工作是突破现有模型在特定领域的能力,向真正的AGI迈进。

她们理解,当前的模型倾向于运用已有大量知识进行回答,尽管它们在记忆上的表现显著,但面对全新的问题,仍然缺乏足够的即时推理能力。
这样的局限性使得Agent在解决实际问题时,表现不如人意。
Q&A
在一次分享会上,有人问,如果一个Agent能通过调用外部工具或多个模型组合,会发展到什么程度?
丽丽解释说,设计高效、低成本且效果好的系统是研究的方向。
她们的工作流程复杂,但效果显著,需要在效率与成本之间找到平衡。

另一位听众提出,使用大量生成数据或模拟数据训练模型是否有效。
丽丽表示,小模型的训练可以通过合成数据带来针对性改进,但大模型则需要更严格的质量把控,以避免噪音数据的负面影响。
结尾
丽丽回到家中,反复思考着白天的讨论。
她知道,要达到AGI并不仅仅是技术上的突破,更是对人类智能本质的深刻理解。
每一个新发现都像是朝着遥远目标迈出的坚定一步,或许下一次的突破,就能使她们更接近这个梦想。

无论这条路有多远,探究人类智能的边界,是一场充满希望和挑战的旅程。
人人都在追问:从Agent到AGI,我们还要走多久?
也许答案并不重要,重要的是这一路上的每一个探索瞬间。