昨天, 马斯克终于甩出了他的王炸 —— Grok 3,号称 “ 地球上最聪明的 AI ”!
这同样也是人类史上首个在 20 万块 GPU 上训出的模型的诞生。
要知道, 马斯克之前可是疯狂预热,各种吹爆 Grok 3,从推特到发布会,他几乎把 “ 地表最强 AI ” 的标签贴满了每一个角落。

他甚至放话,Grok 3 不仅能轻松应对复杂的推理任务,还能在编程、数学、科学 等领域吊打现有的一切 AI 模型。

这波操作,直接把期待值拉满, 大家纷纷坐等见证 “ AI 天花板 ” 的诞生。
发布会上, xAI 团队直接甩出了 Grok-3 全家桶:
Grok-3( Beta )、 Grok-3 mini击败 o3-mini / DeepSeek-R1 的推理模型 Grok-3 Reasoning( Beta )、 Grok-3 mini Reasoning联网深度搜索 DeepSearch
更炸的是, Grok 3 的背后是全球最大的 AI 计算平台 —— 20 万卡集群 “ Colossus ”。
作为世界上最大的人工智能超级计算机, Colossus 采用英伟达全栈参考设计, 配备 20 万个英伟达 Hopper GPU 。

只能说,马斯克这次是真·硬核玩家。
 Grok 3到底有多聪明?
Grok 3到底有多聪明?和 Grok 2 相比, Grok 3 的训练规模直接翻了 10 倍, 烧掉了 2 亿 GPU 小时!
但这背后到底能带来多强的智能?咱们从它的实际表现和数据中找答案。
和 Grok 2 相比, Grok 3 的训练规模直接翻了 10 倍, 烧掉了 2 亿 GPU 小时!听起来很夸张对吧?但这背后到底能带来多强的智能?咱们从它的实际表现和数据中找答案。
Grok 3 一出场就巅峰, 成为首个在竞技场( lmarena.ai )突破 1400 分的模型,并在所有类别中排名第一。
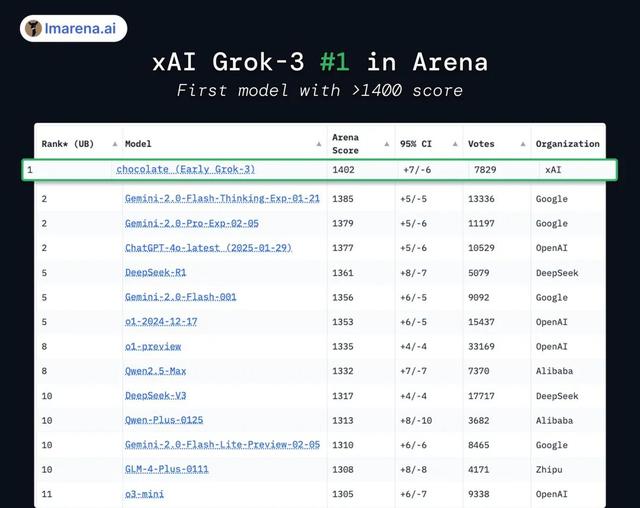
更早之前, Grok 3 还化名 “ 巧克力 ” 在 LMSYS 排行榜上打榜, 直接拿到了 1402 分, 成为唯一一个得分超过 1400 的模型。
Grok 3 提供了 DeepSearch 模式、 思考( Think )模式 和 Big Brain 模式。
其中, “思考” 模式支持当下流行的思维链推理能力,这与 OpenAI 的 o1 系列、 o3 mini 以及 DeepSeek R1 等模型的功能类似。
这次,xAI 也推出了 Grok 3 Reasoning Beta 和 Grok 3 mini Reasoning 两款推理模型参战。
从测试结果看, Grok 3 的纸面实力依然 “ 吊打 ” 对手。

但有一个关键细节:测试中加入了 Test-Time Compute , 也就是给模型更多时间思考。
结果显示,浅色部分(加时赛成绩)明显优于未加时的情况。换句话说, Grok 3 的推理模型思考时间越长,表现越好。
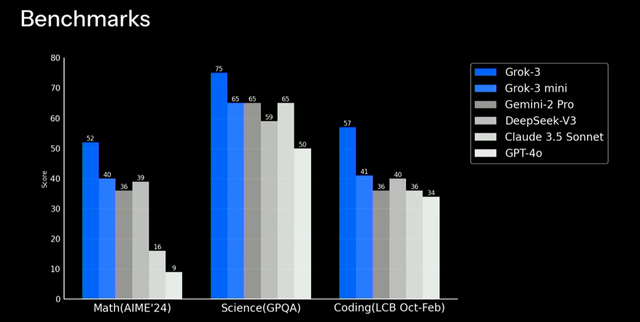
在发布会上, xAI 团队展示了 Grok 3 在 2025 年 AIME 数学竞赛 上的表现,两款新模型分别拿下 93 分 和 90 分, 刷新了 SOTA 。

此外, xAI 团队还给 Grok 3 布置了两个任务:
一个是生成 “从地球发射、着陆火星,然后再次返回地球的 3D 动图” 的代码。
直播中, xAI 团队先用 Grok-3 mini 进行测试, 随后切换到了满血版 Grok-3 。
经过 114 秒的等待, Grok-3 给出了答案。

另一个是用 pygame 制作一款结合了俄罗斯方块和宝石方块的游戏,要求代码可以很长,但效果要炫酷。
这个任务 xAI 团队开启了 Big Brain 模式,让模型用更多的计算资源去做更多的思考。
Grok 3 不负众望把这两款游戏成功结合,并介绍了合体版游戏的特点。
运行起来,既有俄罗斯方块的消除机制,又根据宝石迷阵的特点调整成了三个方块消除一次,效果可以说相当炫酷。

除了 Grok 3 本体, Grok 3 mini 版本通过牺牲一定程度的准确性, 换取了更快的速度。在多个闭源与开源模型中,它的表现几乎与最顶尖的 AI 系统持平。
此外, xAI 推出了 DeepSearch , 这其实是一个智能搜索引擎, 基于 Grok 3 的技术, 能够扫描互联网和 X(原 Twitter )平台, 提供信息摘要来回答用户查询。
它的功能可以视为对 OpenAI 的 Deep Research 和谷歌类似功能的直接对标。

可以从上图看到,在左侧,主要展示出了搜索和推理的过程,而在右侧,则展示出了深度思考过程及模型正在搜索的网址和网页。
在 Grok-3 正式发布之前,AI 圈的大神 Andrej Karpathy 就拿到了抢先体验资格。
他玩了两个小时 Grok-3 后,直接发了一篇长文,详细分享了自己的体验。Karpathy 的评价很直接:
Grok-3 的思考能力已经达到了 SOTA(State of the Art,当前最优水平),推理能力和 OpenAI 的 o1-pro 差不多,还略好于 DeepSeek R1 和 Gemini 的推理模型。


算力消耗是 DeepSeek V3 的 263 倍
在发布会上, 马斯克用近乎炫耀的口吻透露, Grok 3 的训练动用了 20 万张 H100 GPU(直播中他表示 “ 超过 10 万张 ” ), 总训练小时数高达两亿小时。
这一庞大的算力投入无疑对 GPU 行业是一大利好,但也引发了对 AI 模型训练路径的广泛讨论。

尽管 Grok 3 在多个基准测试中超越了 DeepSeek R1 和 GPT-4.0,但其性能提升仅为 1-2%,这让不少用户在实际测试中感到“ 无明显差别 ”。
可见, 虽然 Grok 3 在分数上领先,但这一优势并未让所有人信服。
毕竟, xAI 在 Grok 2 时代就曾因在榜单中 “ 刷分 ” 而备受诟病, 尤其是在榜单对回答长度和风格进行降权处理后, Grok 2 的分数大幅下降, 被业内人士批评为 “ 高分低能 ”。
不仅是榜单 “ 刷分 ”, 为了让自己遥遥领先, xAI 还使用了一些小小的作图技巧:榜单的纵轴仅列出了 1400-1300 分段的排名,让原本 1% 的测试结果差距,在这个 PPT 展示中都变得异常明显。

无论是榜单 “ 刷分 ”, 还是配图设计上的 “ 小技巧 ”, 都反映出 xAI 和马斯克本人对模型能力 “ 遥遥领先 ” 的执念。
但为了这 1-2% 的差距, 马斯克所付出的代价堪称高昂。
有网友对比了使用 2000 张 H800 GPU 训练两个月的 DeepSeek V3, 计算出 Grok 3 的实际训练算力消耗是 V3 的 263 倍。
而 DeepSeek V3 在大模型竞技场榜单上的得分与 Grok 3 的 1402 分相比, 差距甚至还不到 100 分。
尽管 Grok 3 在算力投入上堪称 “ 烧钱 ”, 但其性能提升的幅度却远不及成本的增长。
这不禁让很多网友质疑:烧钱烧出大模型, 真的是未来的唯一出路吗?

Grok 3 的未来:抢先一步,但能走多远?
AI 竞争的白热化让马斯克显得有些仓促地推出了 Grok 3。
或许是为了在谷歌、 Anthropic、 OpenAI 等竞争对手更新下一代模型之前抢占先手, 至少让大家看到 Grok 3 即将追平现状。
然而, Grok 3 究竟有没有突破、能不能再突破,还需要时间的检验。
马斯克和 xAI 团队显然没有止步于此。
他在社交媒体上多次表示, 当前用户体验到的版本 “ 还仅仅只是测试版 ”, 并透露 “ 完整版将在未来几个月推出 ”。
这一表态让用户对后续升级充满期待,也展现了团队对技术迭代的信心。
马斯克本人更是化身 Grok 3 的 “ 产品经理 ”, 鼓励用户直接在评论区反馈问题,并表示团队会根据反馈不断优化产品。

然而, Grok 3 的未来发展仍面临挑战。
首先是算力消耗的问题。尽管 xAI 团队在硬件和算法上投入巨大,但如何在性能和成本之间找到平衡,将是未来 AI 技术发展的重要课题。
其次, Grok 3 在实际应用中的表现仍需进一步验证。虽然它在测试中表现优异,但在真实场景中的稳定性和可靠性还有待观察。
值得一提的是, 马斯克不仅是技术狂人,更是战略高手。
一方面,他加紧推动 Grok 3 的迭代和优化;另一方面,他还放出 “ 收购 OpenAI ” 的消息, 给竞争对手制造压力。
在 AI 这条路上,你很难预测马斯克下一步会做什么。
参考资料:
新智元
量子位
差评
极客公园
编辑:不吃麦芽糖

