一、前言:哪个发烧友能抵挡本地部署大模型的诱惑
今年年初,横空出世的DeepSeek AI大模型火爆出圈,一夜过后人人都在谈论DeepSeek大模型,而已经进入第二年的AI PC方面,自然也不会落后。
相对于直接付费使用成熟的AI应用,DeepSeek完全开源的特性也让更多发烧友乐于在本地部署,充分利用越发强大的硬件AI性能。
但是对于主流的笔记本平台,在本地运行DeepSeek大模型,效果如何呢?
我们找来了当下比较新的轻薄本,Intel平台和AMD平台各一台,测试一下不同平台在本地运行DeepSeek大模型的表现。

当然我们在本地部署的DeepSeek只能是蒸馏版,因为满血版DeepSeek-R1模型高达671b的参数根本不是小飞机平台所能容纳的,好在还有六个蒸馏后不同规模的小模型,方便玩家根据自己的硬件配置选择合适的模型规模。
DeepSeek-R1大模型和由它蒸馏而来的六个小模型都是开源的,每个人都可以下载部署到自己的设备上。
选择合适的模型规模,关键就在于运行设备的显存或内存容量,当然对于普通玩家,特别是笔记本用户来说,主要还是看内存大小。
这也就是AI PC概念出现以来,电脑的内存容量已经普遍从32GB起步的原因,就连被戏称“用金子做内存”的苹果,最新的Mac Mini M4也把内存升级到16GB起步。
二、测试平台介绍:各有优势 但都是最强移动处理器的竞争者
条件所限,我们没有找到两台完全对等的笔记本进行对比,只能选取比较接近的配置,分别搭载了Intel酷睿Ultra 9 285H处理器、AMD锐龙AI 9 HX370处理器,都是各自平台轻薄本能搭载的最强处理器,定位上旗鼓相当。

Intel酷睿Ultra 9 285H处理器基于Arrow Lake架构,拥有6个性能核,8个能效核和2个低功耗能效核,一共16核心,但不支持超线程技术,所以总线程数也是16, 性能核最大睿频频率为5.4GHz,拥有24MB高速缓存。
它内建Intel锐炫140T显卡,包含8个Xe核心,同时还内置NPU,能够提供高达13 TOPS的算力。
CPU+GPU+NPU全平台总算力达到99 TOPS,为本地运行大模型提供了很好的支撑。

AMD锐龙AI 9 HX370处理器基于Zen 5架构,4个Zen 5核心和8个Zen 5c核心,支持超线程技术,总共是12个核心24线程,最高加速频率为5.1GHz,拥有12MB的L2 高速缓存和24MB的L3 高速缓存。
内建AMD Radeon 890M显卡,包含16个GPU核心。
当然也有独立的NPU引擎,而且算力高达55 TOPS,是迄今最强的。

需要注意的是,Intel酷睿Ultra 9 285H处理器的TDP高达45W,AMD锐龙AI 9 HX370处理器的TDP只有28W。
当然,Intel和AMD都允许笔记本制造商根据具体产品设计,在一定范围内设定处理器功耗。


我们这次准备的两台笔记本,Intel方面是一台轻薄本,实际烤机测试CPU稳定释放功率只有35W左右,而AMD方面是一台全能本,还搭载了一块NVIDIA RTX 4060Laptop独立显卡(已禁用),拥有更强劲的散热配置和功耗表现,实际烤机测试中可以稳定释放高达60W的功率。
笔记本平台并不像台式机主板一样可以方便地在BIOS中对CPU功耗性能等进行限制,所以这个测试并不是一个非常严谨的性能对比测试,只能说分别测试一下各自的表现情况和我们的使用体验,请读者朋友们自行比较。
三、DeepSeek-R1模型测试:iGPU算力也可流畅运行本地部署的14B模型
Ollama是一个开源的大语言部署服务工具,只需iGPU即可部署大模型。
我们这次测试就是基于Ollama框架,在本地部署DeepSeek-R1的蒸馏版模型,测试使用iGPU的运行效率。
Ollama作为一个开源软件,功能依赖全球开发者的共同维护,自然也会有一些特别的分支。
我们此次测试,专门找来了针对 intel 推理框架和AMD ROCm推理框架分别优化过的Ollama版本,更能体现Intel和AMD硬件在各自最佳环境下的运行效率。

(左侧为Intel酷睿Ultra 9 285H运行截图,右侧为AMD锐龙AI 9 HX370运行截图)
为了避免图形UI造成的延迟和对性能的影响,我们直接在命令行中同DeepSeek-R1:14B模型进行对话,我们准备了4个问题,分别是:
你是谁?
最简单的问题,用来检查DeepSeek大模型是否正确工作。
模仿李白的风格,写一首七律·登月。
简单的文字写作能力。
一亿之内最大的质数是多少?
数学能力其实不是DeepSeek这种推理模型的长处,但也可以测试一下。
帮我写一份5月份前往南疆的旅行攻略。
对DeepSeek的语义理解/推理能力和文字写作能力进行测试。
同样我们对DeepSeek-R1大模型另外两个更小规模的蒸馏版本7B和1.5B,也都进行了测试,测试成绩汇总如下:
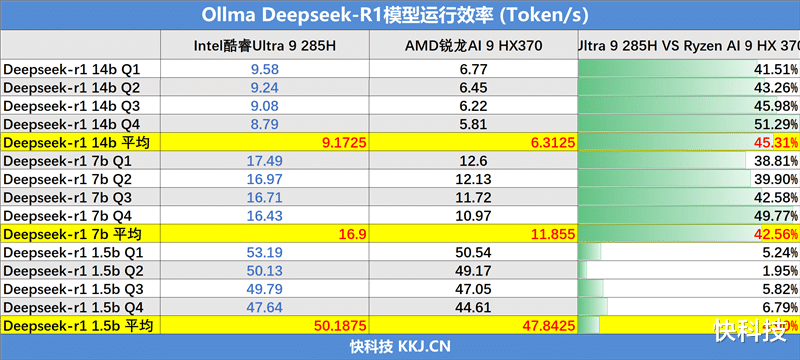

模型规模越小,执行速度越快,但相对的AI智力下降也非常明显,经常会出现无法回答或者先入死循环的状态。
14B规模的模型的反应速度和回答准确率表现都比较优秀,在测试平台上运行效果非常好(但数学问题的回答准确度还是不太行)。
从测试结果上来看,Intel酷睿Ultra 9 285H在针对Intel优化过的Ollama上的每秒token输出更高一些,在14B和7B规模模型中,对比AMD锐龙AI 9 HX370都有40%左右的领先,而在1.5B规模模型中,双方性能表现都很强,但Intel平台仍有5%左右的优势。
当然这个测试也并不能代表Intel处理器在AI性能上就一定比AMD处理器强很多,每秒输出的Token数也不是决定AI性能表现的唯一评价维度,但至少从实际测试的结果上来看,针对Intel 优化过的框架确实拥有更好的支持,让Intel处理器的性能表现更强。
四、AI大模型能力测试:Deepseek-R1:14B模型编程已经实用
我们也测试了一下Deepseek-R1:14B模型在Intel酷睿Ultra 9 285H处理器的轻薄本上实际表现,测试一下使用本地Intel iGPU算力来编程,效果如何。
我们首先安装了一个针对Intel酷睿Ultra处理器优化的AI应用工具:Flowy AI PC软件,然后在其中使用Deeoseek-R1:14B模型来编写一个基于HTML语言的贪吃蛇游戏。


按照Deepseek给出的操作说明,我们很容易就可以把这个由AI写出来的贪吃蛇游戏运行起来,虽然比较简陋,但基本的游戏功能已经没有问题了。
Intel酷睿Ultra 9 285H处理器搭配Deepseek-R1:14B模型,能力已经具备一定实用价值了,已经可以帮助用户提高编程速度和工作效率了。
五、总结:Intel 全力推广OpenVINO 效果已经开始展现
得益于DeepSeek的开源,让本地部署AI大模型变的前所未有的容易,即使是在轻薄本这种并不以性能见长的移动平台上,运行本地大模型也能有相当不错的性能表现。
在我们的测试中,Intel酷睿Ultra 9 285H处理器展现出相当强劲的实力,使用开源部署工具Ollama(Intel优化版),在本地部署DeepSeek-R1:14B,仅依靠CPU的算力,就可以实现接近10 Token/s的输出速度,比AMD锐龙AI 9 HX370处理器的输出高了40%以上,而且这个成绩还是在CPU实际功率相差接近一倍的情况下得出的。

这也从一个侧面说明,AI大模型的高效运行,不仅仅是硬件性能的问题,软件的适配同样重要,甚至比硬件性能更重要一些。
就像谈论AI算力,NVIDIA是个绕不开的名字一样,NVIDIA的CUDA和硬件相辅相承,共同构成了宽阔的护城河,Intel和AMD作为追赶者,必须付出巨大的努力和代价才有机会在这个领域挑战NVIDIA的地位。
Intel现在不遗余力地推广OpenVINO,我们已经看到了结果。也许硬件的真实性能强弱难以量化比较,但从我们这次的体验来看,Intel酷睿Ultra 9 285处理器在用户实际使用中,确实能发挥出比AMD锐龙AI 9 HX370处理器更强的性能。
再加上Intel连续举办的人工智能创新应用大赛,用真金白银鼓励开发者开发基于OpenVINO的AI应用,Intel平台的AI应用正在迎来一个百花齐放的时代。
DeepSeek大模型极大地抹平了桌面平台面临的算力鸿沟之后,AI应用的丰富程度,专用推理架构的普及程度,硬件性能的发挥水平,共同决定了谁才是AI PC时代的王者。
Intel现在在全力推广OpenVINO,我们也不希望AMD被拉开太远,NVIDIA算力霸权的挑战者越多越好。
