
文|正经的烧杯
编辑|正经的烧杯
«——【·前言·】——»
在森林资源清查中,获取森林三维结构数据尤为重要,如地面三维信息、林木冠层、高度等。遥感影像与红外相片结合已被用来完成林业资源调查并绘制林相图、森林专题图等,但传统的光学遥感只能提供森林的二维信息。
机载激光雷达的出现,为此研究向前迈出一大步,激光雷达的贯通性和精准性使自动获取单木几何结构和重建真实三维成为现实。
在过几十年里,激光雷达技术在森林结构参数方面的提取研究已取得一系列进展,而单木分割则一直是该技术在林业研究上的热点方向。
某地区通过蜂鸟机载激光雷达系统在相同林区的上空,进行飞行数据采集,这样可以通过林区的顶部信息,进一步补充树冠的细节数据,分析处理得到林区的生物量、蓄积量、冠层高度、冠层覆盖度、郁闭度/间隙率、林窗参数、树密度,甚至林区单木的位置、高度。

本文基于机载激光点云数据,主要针对森林单木分割提取进行深入探究,利用基于CHM的单木分割、基于点云的单木分割、利用CHM生成的种子点分割以及利用层堆叠生成种子点分割4种不同分割方法。
进行分割结果的对比与分析,寻找最优分割算法,为今后林分参数估测、森林资源清查工作提供理论基础,为制定林业管理的方针政策以及科学化经营森林资源提供参考依据。

«——【·数据采集与预处理·】——»
本次研究区选自广西南宁市国有高峰林场,共22块针阔混交林样地,研究区内坡度介于24°~34°,大于24°的区域面积占整个研究区面积的3/4,林场内95%的树木为人工林,主要林木类型包括桉树、松树、杉木、八角、米老排等。
实验数据来源于广西林勘院,获取时间为2018年9月,使用R44直升机作为搭载飞行平台,雷达系统为奥地利RIEGL公司的VUX-1LR,该系统将激光测距、全球定位系统(GPS)和惯性导航系统(IMS)三者融为一体。图1为以高度显示的原始未分类点云数据。

实地林木数据采集:研究区内选取了杉木和桉树两种典型树种类型,共设置了22块样地,每块样地为20m×20m,其中杉木林有10块,桉树林有12块,共有1026棵单木数据。地面实测得到的单木参数详情见表1。

点云数据处理及模型生成:噪声点通常是明显高于或低于地物的回波点,表现为孤点或点簇,直接删除即可,而对于特征不明的噪声点,需结合人工目视解译加以判断。
本文采用空间分布去噪法去噪,该方法假设点云符合空间分布模型,然后把不符合空间分布规则的点视为噪声点并将其删除。

点云滤波选择基于改进的渐进加密三角网滤波算法,它最大程度的保留了地形相关信息,对于分离地面点与非地面点有较好的优势,而滤波只是简单地将地面点与非地面点区分,要得到更详尽点云,需进行点云分类。
本文研究主体是森林,综合考虑,涉及到四类点云数据分布规则,包括:地面点、低矮植被、中等高度植被以及未被分类点云。图2为分类结果。

为了降低点云数据受到的地形起伏的影响,还需要对分类结果进行归一化处理并生成DEM、DSM、CHM模型,为之后的单木分割奠定基础,图3为3种模型对比图。

«——【·单木分割方法对比·】——»
基于CHM的单木分割:CHM本身就是一种栅格图像,对它的处理可看作是对灰度图像的处理,较为经典的算法有区域增长法、注水算法、分水岭分割算法等。
综合对比本次选择分水岭分割算法来完成,该算法是一种与浸水过程相似的数学形态学算法,具体表现为:把图像中每一个CHM栅格像元的灰度值对应该像元的海拔高度,然后将灰度值取反。在图像中会存在一些点,称为局部极小值点,也就是树高点。

假设在这些点上凿一个洞并向内注水,注水点即极小值处,水就会以相同的速度从图像中的树高点开始浸没,最终形成连续的多个水槽。
当各个水槽中的水面汇集时,水位开始逐渐上升,这时会有一道堤坝建立在两水槽之间,整个过程完结后,每个树高点所在的位置都是被其相对应的堤坝包围起来的,分水岭的概念就是这些堤坝所形成。

最后视线可见只有堤坝顶部的位置,图像分割时,堤坝即边界,水槽即分割区域,图4是四个局部极小值作用得到积水盘过程的流溢模型。
其中图4a为输入信号;图4b为局部极小值处挖洞,初始化流溢,图4c为不同极小值对应水流相遇时构建水;图4d为最终流溢情况,3个分水线,4个积水。

最终分割的结果如图5所示。

«——【·基于点云的单木分割·】——»
直接基于点云数据分割单木较为常用的方法有:K-means聚类方法、基于图论归一化分割、区域增长结合阈值判断的方法等。本文选用的是区域增长结合阈值判断的方法(pointcloudsegmentation,PCS算法)。
该算法假设最高点为树的顶点,从这个点开始进行区域增长,最终分割出完整的一棵树,经过多次迭代直到分割出所有树木为止。

如图6所示,该算法从种子点A(即全局极大值)开始,主要根据间距临界值和最小间距规则,通过对更低的点进行估计,将A发展为一个树聚类。如点A是最高点,因此将点A视作一号树木的树顶,此时把低于A的点相继分类。
点B被分类成二号树木,因为间距dAB大于一个设定的临界值,然后设置点C,点C的间距dAC小于临界值。
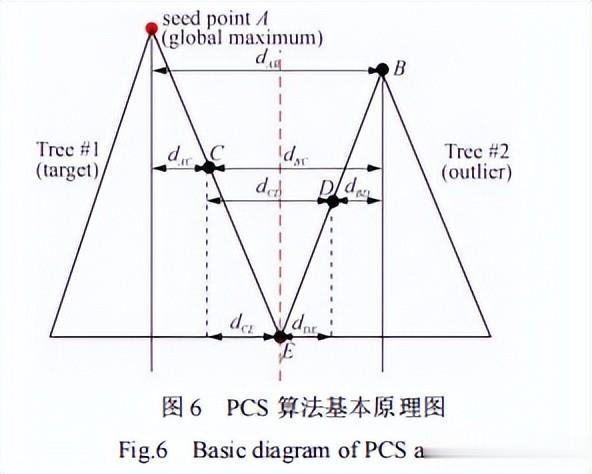
通过与点A和点B的比较,点C的类别被设定为一号树木,因为dAC小于dBC。通过与点B和点C的比较,点D被分类成二号树木,通过与点C和点D的比较,点E被分类成二号树木,以此类推。
根据间距临界值和最小间距规则,临界值应当与冠层半径相当,因此本文设置距离阈值为2m,距离地面高度值为2m,该值的大小设置关乎算法能识别到的最矮单木的高度,提取到的单木结果如图7所示。

«——【·利用CHM生成种子点分割·】——»
利用CHM生成种子点的单木分割主要分两步:在CHM的基础上生成种子点,通过种子点获取单木的相关信息,主要是位置有关的数据,在生成的种子点基础上完成单木分割,将获取到的相关信息当作种子点,完成对点云的单木分割。

在实验过程中,可以反复增减种子点的个数,通过调节种子点的数量提高林木识别与分割的精度,最大最小树高、高斯平滑因子以及半径的参数设置是该算法的关键。
树高设置是分割树高范围的基础,根据研究区实际情况设置树高最大值为60m,最小值为1m;平滑因子的大小是分割单木数量的依据,过大或过小都会造成分割不准确。

该值设为1m;半径是高斯平滑在使用过程中的窗口大小设置,这个数值通常表现为奇数且为冠幅直径大小的平均值,设置为5m。
图8a为生成种子点的结果。最后根据点云数据和种子点数据,使用基于种子点分割功能来完成最终研究区的单木分割。

依次将生成的种子点对应点云数据,所采用的种子点文件最少要包括4组信息,分别为:树木编号、横坐标、纵坐标以及树高。图8b为分割结果。
«——【·利用层堆叠生成种子点分割·】——»
利用层堆叠生成种子点算法首先将经过归一化处理的点云数据进行水平数据分层,设置一个种子点,在每一分层数据中使用K-Means聚类方法,将点云数据反复迭代和计算集群中心得到不变的种子点。

其次进行多边形集群,在各个多边形周围建约50cm大小的缓冲区,建立缓冲区目的是把主要集群和其他集群分离开,确保不会将点云数据漏分。
然后将每一层的集群多边形堆叠和平滑,会产生许多0.5m分辨率的栅格化重叠多边形,大量多边形重叠在一起表示为一棵树。

再使用固定窗口判断出局部最大值,而被识别出的这些局部最大值也就是树木的中心点,代表着整个冠层中重叠度最高的点,即树木最高点。
最后将区域增长与阈值判断这两种方法相结合(PCS算法)完成最后的单木分割,层堆叠算法判别出种子点及最终分割结果如图9所示。

«——【·单木分割结果分析·】——»
单木分割结果精度分析:单木分割识别的精度评价标准多种多样,一般而言,可以通过匹配单木的树冠顶点或者识别出的树冠边界轮廓来评价,就是所谓的“点”和“多边形”两种不同形式的评价标准。
可匹配的方式主要为4种:“点对点”“点对多边形”“多边形对点”“多边形对多边形”。考虑到实测单木是位于单木树冠的顶点,本文采用“点对点”的匹配方式对单木的识别结果进行评价。

分割的精度评价大致分为3种情况:准确分割、多度分割与欠分割。针对识别的结果本文采用了信息检索与统计学中的准确率、召回率和F测度来完成评价。

其中Nc为正确识别单木总数;Nr为实测可见单木总数;Nd为识别出的单木总数;Pd为准确率;Pr为召回率(或查全率),其表达的是算法分割出的单木占总实际真实单木数量的比例。
F为测度,若算法能够识别出与实测树木对应所有单木时,F=100%,相反地识别出的单木全部变现为伪单木时,F=0%;通常来说,F测度值的大小代表着单木识别结果的好坏,值越高表示识别精度越高。
表2是实验中22块样地的单木识别结果统计,表中A代表基于CHM的单木分割算法,B代表基于点云分割的单木算法,C代表利用CHM生成种子点的单木分割算法,D代表利用层堆叠生成种子点的单木分割算法。

结果表明:利用层堆叠生成种子点提取单木准确率最高,共识别767棵树木,准确识别548棵,识别率为78.51%,准确率为71.45%。
A与B的结果相接近,C算法准确率略低于D算法。A算法共识别出621棵单木,识别率为63.56%,准确率为60.86%;B算法准确识别了425棵树木,识别率为66.43%,准确率为65.49%;C算法稍微高一些,共识别出704棵树木,其中准确识别数量为493棵。

4种算法对比后,选择最优算法:层堆叠生成种子点分割方法进行相关性分析。将识别的单木数、准确识别数与实测数据进行分析,绘制出散点图,如图10所示。
可见该算法的单木识别度很高,R2=0.809,准确识别单木数量的精度也是极高的,R2=0.868,说明该算法在分割单木时表现稳定,验证了其可行性。

«——【·单木分割结果影响因素分析·】——»
单木分割的精度与很多因素相关,包括研究区大小、树冠高度、叶面积指数、郁闭度、采集过程中的噪声、处理过程中的误差等。
通常传统机载激光雷达系统所记录的信号为多次离散回波信号,其中大多数为首次回波信号,中间次回波与最后回波体现在采集过程中单木的中间及以下部位,所以会导致一定数量的有效回波未被记录,如:来自于冠层、地面以及其它不同地方的回波信息。

同时机载激光雷达收集到的点云数据中不可避免地含有大量的噪声点,当研究区域的植被覆盖率较高时,针对不同的激光雷达,其对应的识别率也会存在较大差异。
森林密度的影响表现度也较大,假设研究区中相同种类的森林树木,但它们的稀疏程度不一致,密度较小的样地识别度肯定是较高的。

而密度大小相同,不同种类的树木,如针叶林与阔叶林,用不同的提取方法识别到的树木数量不同,因为总体来说阔叶林树冠较大且密会比较难以区分开树与树之间的分界线,会产生错分或漏分情况。
四季变化及森林的生长状况也是影响单木分割的重要因素,有大量相关研究表明不同季节下的树木形态不一样,所以会影响最终结果。

冬季时,大多数林木的树叶掉落,较为稀少,将此时段采集到的数据用于单木分割实验,研究发现单木识别率相较于夏季林木生长旺盛时段明显偏高。
最后树高变异系数是表达树木高度变异离散程度的参数,它在一定程度上反映了样地树木的邻近程度,该系数也会对单木分割造成一定的影响,变异系数越大,单木分割的精度就会越低。

只有全面研究和分析过单木分割的精度与那些因素有关系,才可以针对不同类型的研究区、复杂的森林状况合适地选择不同的分割方法进行单木分割以及处理数据过程中产生后续问题的解决,这样便于进一步对单木分割算法及时进行改进。
«——【·结语·】——»
激光雷达在获取森林垂直结构数据方面有很大的优势,它能高效获取一定范围内的林分参数,目前很少有关于不同单木分割方法的对比研究,本文用4种分割方法完成了单木识别,并对分割的结果进行精度分析与评价,结果表明4种方法的准确分割率均在60%以上。

精度最高的是利用层堆叠生成种子点分割方法,分割率为71.45%,能识别出样地内78.51%的单木,准确识别率为71.45%,准确识别单木数量与实测数量的相关性也是极高的,R2=0.868,这证明了该方法的实用价值。
基于CHM分割与直接基于点云分割的精度差不多,这两个算法本身并不复杂,也是在单木分割研究中最常用的方法,对于森林类型较为简单的研究区域可选择这两种方法也能达到预期效果。

机载激光雷达获取数据在一定程度上具有优势,但单一的采集设备要单次且全面地获取全部数据还是比较困难的。
森林茂密地区,雷达获取到的单木信息只有树干以上较为完整,树干以下基本获取不到,这就会造成单信息的缺失,尤其针对胸径、树干直径等。

未来研究单木分割提取可以结合地面三维激光扫面技术、背包技术等,这样可以更全面准确地采集研究区数据。
本文主要树种是杉木与桉树,树种类型较单一,今后研究中可以增加更多种类森林,以便更加全面地研究单木分割算法对不同种类研究区的影响。
