TCP粘包是指在网络传输过程中,多个数据包被合并成一个连续的数据流发送或接收,导致应用层无法正确解析原始数据边界的现象。这一现象如同快递包裹被无序捆绑,接收方难以准确拆分不同包裹内容,直接影响数据处理的准确性和系统稳定性。
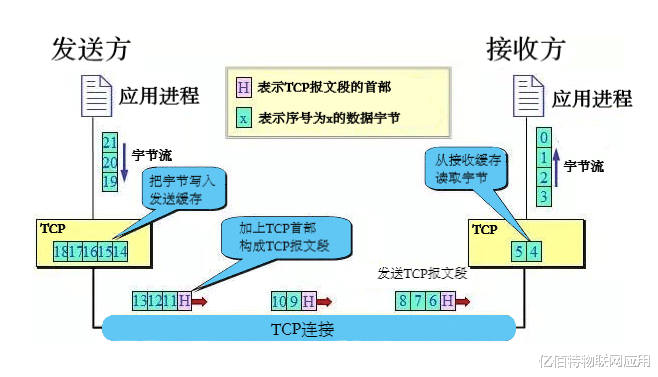
1.发送端合并机制
Nagle算法通过延迟发送小数据包来减少网络传输次数,这在提高带宽利用率的同时,也可能导致多个数据包被合并发送。例如,游戏客户端每秒发送的多个操作指令可能被合并成一个大包。
2.接收端读取延迟
当应用层未能及时读取接收缓冲区数据时,后续到达的数据会被继续写入缓冲区,形成粘包。典型代码示例:
#未及时读取缓冲区导致粘包
data=socket.recv(1024)#处理逻辑延迟
process(data)
3.网络层传输特性
以太网默认MTU为1500字节,数据包超过MTU会被分片传输,分片可能在中间节点被错误合并,引发粘包。同时,网络的拥塞控制机制,如慢启动阶段发送方合并小数据包,网络拥塞时调整窗口大小,也可能改变数据包合并与发送顺序,导致粘包。
TCP粘包的解决方案1.固定长度协议
通过约定固定长度的数据包实现数据边界识别,适用于数据长度已知的场景:
#发送端
data=b'hello'#填充至固定长度10字节
packet=data.ljust(10)
socket.send(packet)
#接收端while True:
packet=socket.recv(10)
process(packet.strip())
适用于数据长度固定的场景,如监控系统数据采集、工业控制指令传输。
2.分隔符标记法
在数据包末尾添加特殊分隔符(如\n\r),适用于文本协议解析:
#发送端
message="data1\n\rdata2\n\r"
socket.send(message.encode())
#接收端buffer=b''while True:
buffer+=socket.recv(1024)
while b'\n\r'in buffer:
line,buffer=buffer.split(b'\n\r',1)
process(line)
3.长度前缀法
在数据包头部添加4字节长度字段,明确标识后续数据长度:
#发送端
data=b'important_data'
length=len(data).to_bytes(4,'big')
socket.send(length+data)
#接收端def recv_all(sock,size):
data=b''
while len(data)<size:
chunk=sock.recv(size-len(data))
data+=chunk
return data
length_data=recv_all(socket,4)
length=int.from_bytes(length_data,'big')
data=recv_all(socket,length)
4.协议栈优化
• 调整Nagle算法参数(TCP_NODELAY)
• 使用更高效的序列化协议(如Protobuf)
• 应用层心跳机制保持连接活性
方案选择建议
实际开发中,建议优先采用长度前缀法,在保证通用性的同时支持高效解析。对于性能敏感型系统,可结合协议栈优化措施提升传输效率。
总结与思考TCP粘包是网络编程中的经典问题,其本质是传输层与应用层协议的语义差异。通过理解发送/接收机制和网络传输特性,选择合适的解决方案,能够有效解决粘包问题。在实际开发中,建议结合抓包工具(如Wireshark)进行流量分析,根据具体场景设计最优方案。
