在图像/视频生成任务中,传统的“下一个token预测”方法正面临严重的效率瓶颈。怎么办?来自浙大、上海AI Lab等机构的研究人员提出了一种全新的视觉生成范式——邻近自回归建模(Neighboring Autoregressive Modeling, NAR)。与传统的“下一个token预测”不同,NAR模型采用了“下一个邻域预测”的机制,将视觉生成过程视为一种逐步扩展的“外绘”过程。
具体来说,NAR模型从初始token开始,按照与初始token的曼哈顿距离从小到大依次生成token。这种生成顺序不仅保留了视觉内容的空间和时间局部性,还允许模型在生成过程中并行预测多个相邻的token。为了实现这一点,研究人员引入了维度导向的解码头,每个头负责在空间或时间的一个正交维度上预测下一个token。通过这种方式,NAR模型能够在每一步中并行生成多个token,从而大幅减少了生成所需的模型前向计算步骤。

下面具体来看。从“下一个token”到“下一个邻域”在当今的AI领域,视觉生成任务(如图像和视频生成)正变得越来越重要。无论是生成逼真的图像,还是创造连贯的视频,AI模型的表现都在不断提升。

然而,现有的视觉生成模型,尤其是基于自回归(Autoregressive, AR)的模型,面临着严重的效率瓶颈。传统的自回归模型通常采用“下一个token预测”的范式,即按照光栅顺序逐个生成图像或视频的token。这种方法虽然简单直观,但在生成高分辨率图像或长视频时,模型需要进行数千次甚至数万次的前向计算,导致生成速度极其缓慢。更糟糕的是,现有的加速方法往往以牺牲生成质量为代价。例如,一些方法尝试通过并行生成多个token来提高效率,但由于邻近图像token之间的强相关性以及上下文信息的缺失,这种方法容易导致生成质量下降。因此,如何在保持高质量生成的同时,大幅提升生成效率,成为了视觉生成领域的一个关键挑战。

为了解决上述问题,研究人员提出了邻近自回归建模(NAR)。正如一开头提到的,通过引入维度导向的解码头,使每个头负责在空间或时间的一个正交维度上预测下一个token,最终让NAR模型能够在每一步中并行生成多个token,从而大幅减少了生成所需的模型前向计算步骤。值得一提的是,维度导向的解码头设计非常灵活,能够轻松扩展到更高维的视觉内容生成。例如,在视频生成任务中,视频可以被视为三维数据(时间、行、列),NAR模型只需增加一个时间维度的解码头,即可在时间、行、列三个正交维度上并行生成token。对于由 t×n×n 个token表示的视频,NAR模型仅需 2n+t?2 步即可完成生成过程,远远少于传统“下一个token预测”模型所需的 tn2 步。这一显著的效率提升使得NAR模型在处理高分辨率视频生成任务时具有极大的优势。
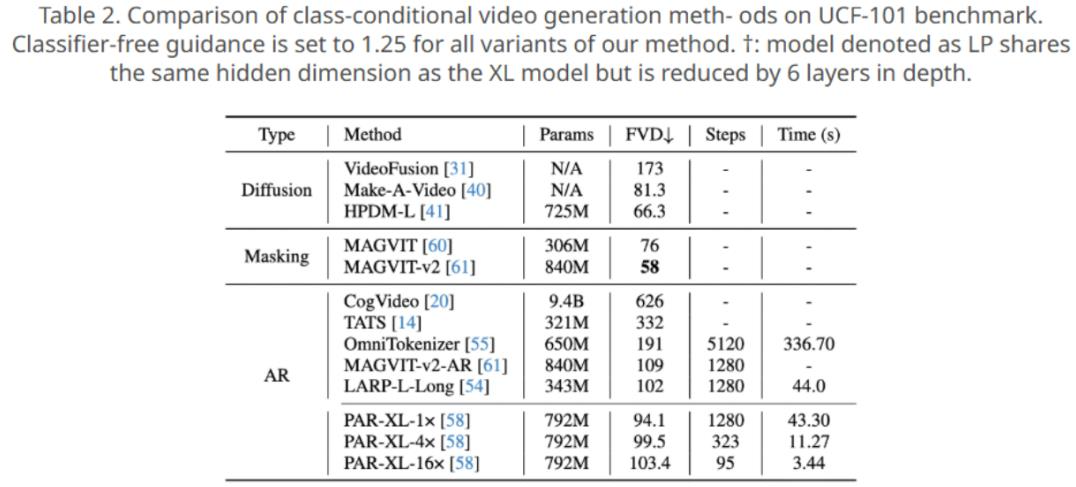
13.8倍吞吐提升研究人员在多个视觉生成任务上对NAR模型进行了全面评估,实验结果令人振奋:1、类别图像生成在ImageNet 256×256数据集上,拥有372M参数的NAR-L取得了比拥有1.4B参数的LlamaGen-XXL更低的FID(3.06 vs. 3.09),同时将生成步数减少了87.8%并带来了13.8倍的吞吐提升(195.4 images/s vs. 14.1 images/s)。与VAR-d16模型相比,NAR-M取得了更低的FID的同时(3.27 vs. 3.30),能带来92%的吞吐提升(248.5 images/s vs. 129.3 images/s)。这说明与现有的自回归生成方法相比,NAR模型在生成效率和质量上均取得了显著提升。2、类别视频生成在UCF-101数据集上,NAR模型相比基于“下一个词预测”(next-token prediction)的自回归模型在生成步骤上减少了97.3%。相比并行解码方法PAR,NAR在FVD更低的同时将吞吐提升了8.6倍。这得益于NAR模型在时间维度上的并行生成能力,确保了视频帧之间的连贯性和高质量生成。3、文本到图像生成在GenEval基准测试中,NAR模型仅使用了0.4%的训练数据(6M)便获得了和Stable Diffusion v1.5相持平的综合得分。与参数量更大且拥有1.4B训练数据的Chameleon-7B模型相比,NAR的综合得分更高(0.43 vs. 0.39)且将吞吐率提高了166倍。

这些实验结果不仅证明了NAR模型在生成效率上的巨大优势,还展示了其在生成质量上的卓越表现。概括而言,NAR模型为视觉生成任务提供了一种高效且高质量的解决方案,有望在未来的AI应用中发挥重要作用。