
某天,朋友小李在群里发了一道题:“小明有个苹果,小红有条狗,请问小红没有什么?
大家纷纷留言,答案五花八门。
小李继续追问:“那像GPT这样的智能模型能回答出来吗?
这个问题引发了大家的热烈讨论。
智能模型真的能像我们一样理解并推理出复杂的关系吗?
什么是组合关系推理?
你有没有想过,我们在日常生活中是如何理解和推理各种关系的?
像一种食物的原料,一个人的社会关系,甚至是事件的因果关系,这些都属于组合关系推理。
组合关系推理(Compositional Relational Reasoning, CRR)是一种能力,它让我们可以理解多个实体之间复杂的关系并基于这些关系进行推理。
例如,你记得小明有个苹果,小红有条狗,当你继续思考小红没有什么时,你能合理地做出“水果”这个答案。
这就是组合关系推理的威力。
GAR基准测试的设计与挑战研究者们为了测试像GPT这样的语言模型是否也具备这种能力,设计了一个名为GAR(广义关联回忆,Generalized Associative Recall)的基准测试。
这个测试非常有意思,它包括了很多有挑战性的任务,目的是考察模型在复杂场景下的表现。
举个例子,GAR不仅测试模型能不能直接回忆出上述的简单关系,还增加了难度,比如:从“小明有个苹果”到“苹果是一种水果”,再到“小红没有水果”。
这中间需要跨越多个逻辑步骤,非常考验模型的推理能力。
即使是目前最先进的模型,在这些任务上的表现也并不理想,常常会“蒙圈”,暴露出它们在组合推理能力上的不足。
现有模型在GAR任务中的表现我们来看看现在的主流模型是怎么表现的。

研究者测试了几个开源模型,比如Llama-2/3以及闭源的GPT-3.5/4。
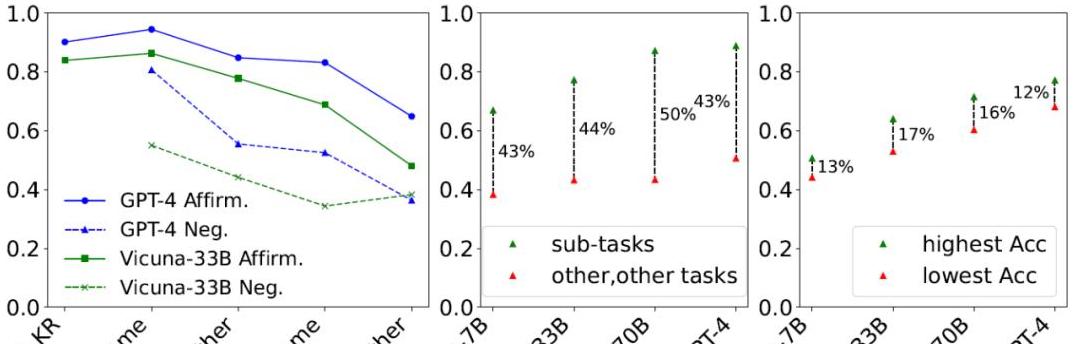
结果显示,当任务难度增加时,所有模型的表现都会显著下降。
比如,模型可以回答“小明有苹果”中的苹果是什么,小红有什么,但当需要将这些信息结合起来,比如问“小红没有什么水果?
这种现象被称为“组合性差距”。
更大的模型,如GPT-4,虽然在简单任务上表现更好,但遇到复杂组合任务时,表现反而不如一些较小的模型,这表明增加模型规模不完全解决问题。
LLM内部的推理机制为了进一步了解这些模型在内部是怎么做出这些推理的,研究者们使用了一种叫“归因补丁(attribution patching)”的方法。
这种方法就像是给模型做CT扫描,可以让我们看到它在处理任务时依赖的关键单元。
他们发现,在一个名为Vicuna-33B的模型中,有一组叫做“核心回路”的机制,在不同任务中被重复使用。

更有趣的是,这些模型依赖于某些注意力头来做出推理判断。
比如,有些注意力头被称为“True head”和“False head”,它们分别对应着抽象的“真”和“假”概念。
这些头在不同任务中都起到了至关重要的作用,是推动模型进行组合推理的基础。
通过干预关键注意力头提升LLM表现既然这些关键注意力头这么重要,有没有办法通过干预它们来提升模型的表现呢?
研究者们选择了几个有代表性的分类任务,测试了不同规模的Vicuna模型,发现通过对True/False头的干预,可以显著提高模型的准确率。
举个例子,他们观察到在任务“判断某个句子是对还是错”中,真头和假头的激活状态能有效区分出真假陈述。
通过干预这些关键头,他们见证了模型准确率的提高,比如对Vicuna-7B模型,在干预后准确率提高了17%。
这表明,这些关键注意力头在不同模型中都表现出一致的效果,说明它们在组合推理任务中扮演了重要角色。
研究意义
这项研究有着重大的意义。
它揭示了现有大语言模型在组合关系推理任务中的核心缺陷。
它通过深入研究模型内部的推理机制,为将来模型的改进提供了方向。
例如,通过优化关键注意力头的功能,我们或许能显著提升模型的推理能力。
研究团队的工作已经在这方面取得了一些初步成果,他们利用这样的思路设计了一个名为DCFormer的新模型,表现出比原有模型更强的推理能力。
此外,这项研究还强调了设计更具多样性的基准的重要性,以便在真实世界的复杂任务中测试和改进模型的表现。
通过揭示现有大语言模型在组合关系推理上的不足,以及探索提升其性能的方法,这项研究为未来改进人工智能模型提供了新的思路和灵感。
我们有理由相信,随着技术的发展,这些模型将在不久的将来更加接近人类的推理能力,甚至超越我们的期待。
这不仅是科技的进步,更是我们对智能未来的一种美好期待。
