
星期一的早晨,科技圈再次被一条新闻炸了锅——字节跳动发布了全新的知识推理测评集 SuperGPQA,许多业内人士纷纷开始讨论这个新鲜出炉的测评集背后到底有什么玄机。
据说,这个测评集难度颇高,让许多模型在上面都跌了跟头。
DeepSeek-R1 和 o1 在这个测评上也不过勉强及格,这一成绩瞬间引起了广泛的关注和热议。
大模型评测现状:通用基准的局限性大家都知道,过去几年,大模型评测集非常流行。
尤其是像 MMLU 和 GPQA 这样的评测集,几乎成了各家模型的必测项目。

看上去这些基准很强大,可是渐渐地,它们的弊端也暴露出来。
比如覆盖范围狭窄,许多学科根本没涉及到;还有一些题目质量也参差不齐,无法真正衡量一个模型的实力。
就拿 GPT-4o 来说吧,这个模型在 MMLU-Pro 上给出的准确率是 92.3%,貌似非常牛,但其实这些测评只是测试了它在一些固定学科上的表现,并没有深挖它处理长尾知识或者复杂推理任务的能力。
所以,这些通用基准其实没办法给出模型的真实能力。
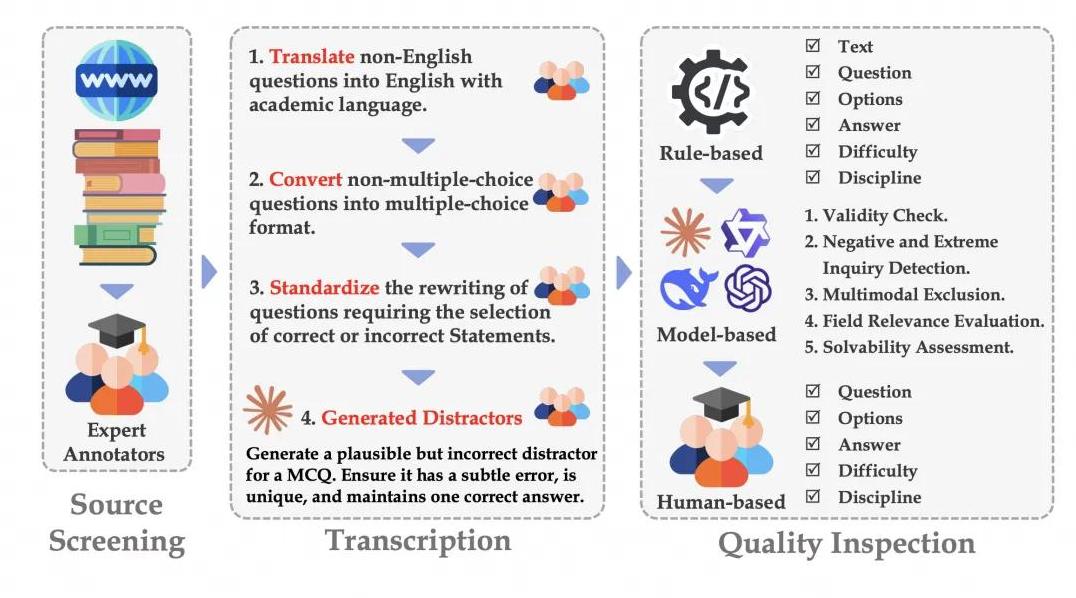
SuperGPQA 的诞生:全新测评标准的必要性为了填补这些空白,字节跳动联合了许多学术和业界的高手,开发了一个全新的评测集,叫 SuperGPQA。

这次评测的范围覆盖了 285 个学科,包含了 26529 道题目,成为了目前最全面的大模型知识推理评估体系。
通俗点说,就是这次的试卷从多个学科出题,几乎无所不包。
不仅如此,SuperGPQA 更是引入了多人协作的标注流程,从题目筛选到质量检测,都是由业内的专家和先进的语言模型共同完成的。
通过这样的专业手段,真正确保了题目质量的高度和区分度。
确切地说,SuperGPQA 就像是一场全新标准的考试,无论是题目数量还是难度都全面升级。
以往一些模型在传统评测集上可以轻松拿高分,但在这个新考试里,成绩就没那么漂亮了。

DeepSeek-R1 在 SuperGPQA 上的准确率才 61.82%,这相当于从以前的“学霸”变成了个刚及格的“普通学生”。
DeepSeek-R1 表现为何不如预期?
很多人都会好奇,像 DeepSeek-R1 这样的顶级模型,为什么在 SuperGPQA 上也会这么难拿高分?
其实原因很简单,就是因为这个新评测集的题目设计更全面,更具挑战性。
过去,许多测试题目比较固定,模型可以通过大量的训练数据来记住这些题目答案,但 SuperGPQA 的题目则不同。

它们不仅覆盖了多样化的学科,还设置了很多需要高阶推理和复杂计算的题目,避免了模型“刷题”得高分的情况。
在这样的测试下,真正决定模型表现的,就变成了它的推理和分析能力,而不仅仅是记忆力。
SuperGPQA:解决大模型评测痛点的利器SuperGPQA 还解决了许多传统评测集的痛点,比如学科覆盖不全和题目质量问题。
这个评测集不仅覆盖了 STEM 领域的大量学科,同时还把长尾学科如图书馆学、植物学、历史地理学等都包括进来。
更重要的是,所有题目都经过了严格的质量检测,确保了评测的公平和可靠。

尤其是在题目设计上,SuperGPQA 采取了统一化的标准,每道题的平均长度、选项数量都是一致的,这样就避免了因为题目本身的差异导致的评测误差。
另外,为了确保题目的高质量和高区分度,团队在每个阶段都进行了严格的质量反馈和审核,力求每道题都具备足够的挑战性。
推理模型霸榜,但表现仍低于人类水平尽管如此,当前的大模型在 SuperGPQA 上的表现距离人类还有不小的差距。
团队的实验结果显示,尽管 DeepSeek-R1 在所有评价模型中表现最好,但它的准确率也只有 61.82%,远低于人类研究生水平的 85% 以上。
这说明,尽管推理模型在不断进步,但在真实复杂的知识推理任务中,仍然有很大的改进空间。
这次的测评结果还揭示了几个有趣的发现。
首先是推理能力真的非常关键,顶级的推理模型在这个新测评上依然占据了前列位置。
国内的一些模型也展现了很强的实力,比如豆包大模型就拿到了聊天模型中第一名的好成绩。
学科表现差异仍然存在,模型在 STEM 领域表现较好,但在人文社科领域依然是短板。
测评数据集的未来展望一次成功的测评,往往可以推动技术的进一步提升。
SuperGPQA 这次展示的不仅是现有模型的能力,还为未来的发展指明了方向。
通过这些真实而严苛的测试,研究团队能够更清晰地了解模型在各种情况下的表现,从而进行针对性的改进。
对于字节跳动来说,这次的测评无疑也是一次形象上的提升,打破了外界对其技术基础投入不足的印象。
而对于整个行业来说,这样的严苛测试无疑促进了大模型的不断进步。
或许,在不远的将来,我们会看到更多更强大的知识推理模型出现,甚至有一天它们的表现能够真正媲美甚至超越人类。
在这个不断发展的领域,让我们拭目以待,看看接下来的技术变革会带来什么样的惊喜。
总之,SuperGPQA 的推出,让我们看到了一个全新的大模型评测世界。
它不仅让一些“学霸”重新认识到自己的不足,也为整个行业树立了更高的标准。
通过这样严谨且全面的测试,我们期待未来大模型在知识推理能力上能够有更大的突破,走得更远。
