
作者丨刘洁
编辑丨岑峰
来自清华大学的高阳团队在最新一届机器人顶级会议 CoRL 2024(Conference on Robot Learning)中荣获 X-Embodiment Workshop最佳论文奖。
CoRL 是全球机器人学习领域的顶级学术会议,每年汇聚来自全球顶尖学府的创新研究,评选出的最佳论文通常代表着前沿技术与重大突破。
清华团队此次获奖的论文标题为《Data Scaling Laws in Imitation Learning for Robotic Manipulation》,关注的是数据规模定律在机器人操作中的模仿学习中的应用,尤其是能否通过适当的数据规模来实现零样本泛化。

研究团队收集了超过 40,000 次演示,并进行了 15,000 多次机器人实测。结果表明,策略的泛化能力主要依赖于环境和对象的多样性,而非单纯的演示数量。
在此基础上,他们设计了一种高效的数据收集方案,仅需四个采集者花一下午便能获取足够数据,使两个任务在新环境和新对象上的成功率达到约 90%。
随后,团队将机器人部署在各种野外环境中,包括火锅店、咖啡馆、电梯、喷泉和其他以前未收集数据的地方。结果显示,模型在这些全新的环境中展现出极好的泛化能力,超出预期。
这篇论文的作者是来自清华大学交叉信息研究院的高阳和他的学生林凡淇、胡英东、盛平岳、Chuan Wen、游嘉诚,其中林凡淇、胡英东、Chuan Wen 同属于上海期智学院和上海人工智能实验室。
论文链接:https://data-scaling-laws.github.io/paper.pdf
项目网址:https://data-scaling-laws.github.io/
代码:https://github.com/Fanqi-Lin/Data-Scaling-Laws
数据:https://huggingface.co/datasets/Fanqi-Lin/Processed-Task-Dataset/tree/main
1实验设计研究团队选择使用手持夹持器(UMI)在不同环境中收集人类演示数据,并使用扩散策略(Diffusion Policy)对数据进行建模,主要研究了策略的泛化性能如何随着训练环境数量、物体数量和演示数量的变化而变化。
实验选择了 Pour Water(倒水)和 Mouse Arrangement(鼠标移动)作为案例研究任务,并在此基础上扩展到 Fold Towels(叠毛巾)和 Unplug Charger(拔掉充电器)任务,收集了超过 40,000 次演示,并在超过 15,000 次实际机器人操作中进行了评估。

具体的实验任务分为对象泛化、环境泛化以及跨环境和对象泛化三种类型,分别针对同一环境下的不同物体、不同环境下的同一物体和不同环境下的不同物体收集演示,随机选择部分演示进行训练,并评估策略在未知情况下的的表现。每个实验设置下,策略在 8 个未见过的环境中进行评估,每个环境有 5 次试验。

实验结果表明,策略的泛化能力与训练物体数量、环境数量和训练环境-物体对数关系密切,符合幂律分布。
对象泛化
随着训练物体数量的增加,策略在未见过的物体上的表现显著提高。当训练物体数量达到 32 时,策略在未见过的物体上的表现超过了 0.9。
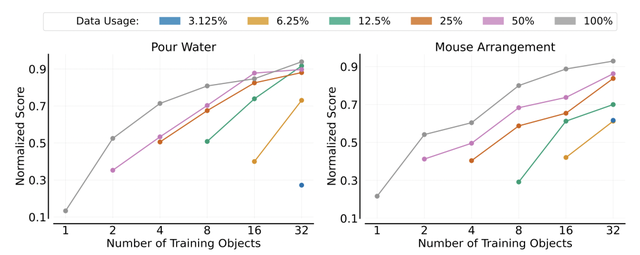
环境泛化
增加训练环境数量显著提高了策略在未见过的环境上的表现。即使演示数量保持不变,环境扩展仍然有效。

跨环境和对象泛化
同时增加环境和物体数量显著提高了策略的泛化能力。与单独扩展环境或物体相比,同时扩展两者的效果更好,且额外的演示对性能的提升更快饱和。

林凡淇

林凡淇,清华大学交叉信息研究院 (IIIS) 的一年级博士生,指导老师是高阳教授。此前在清华大学计算机科学与技术系获得学士学位。
他的研究重点是 Embodied AI(具身智能),这是一个集成机器人、计算机视觉和自然语言处理的跨学科领域。具体来说,他的目标是使机器人能够通过大规模数据实现人类水平的操作能力。同时,他还热衷于利用基础模型来增强机器人的能力。
胡英东

胡英东,清华大学交叉信息研究院 (IIIS) 的四年级博士生,指导老师是高阳教授。此前在北京邮电大学 (BUPT) 获得学士学位。
他的研究重点也是具身智能,他研究了开发通用机器人系统的基本挑战,这些系统可以在各种非结构化的现实世界环境中有效地适应和推广其学习行为。
盛平岳

盛平岳,清华大学交叉信息科学研究院 (IIIS) 姚班的一名本科生。他的研究兴趣集中在机器人技术、模仿学习和算法上。
Chuan Wen
 Chuan Wen,清华大学交叉信息科学研究院 (IIIS) 的博士生,指导老师是高阳教授,同时与宾夕法尼亚大学 GRASP 实验室的 Dinesh Jayaraman 教授密切合作。此前在上海交通大学电子工程系获得学士学位,师从张亚教授和王新兵教授。他目前还是伯克利人工智能研究 (BAIR) 的访问学者,由 Pieter Abbeel 教授和林星宇博士指导。
Chuan Wen,清华大学交叉信息科学研究院 (IIIS) 的博士生,指导老师是高阳教授,同时与宾夕法尼亚大学 GRASP 实验室的 Dinesh Jayaraman 教授密切合作。此前在上海交通大学电子工程系获得学士学位,师从张亚教授和王新兵教授。他目前还是伯克利人工智能研究 (BAIR) 的访问学者,由 Pieter Abbeel 教授和林星宇博士指导。游嘉诚
游嘉诚,清华大学交叉信息研究院 (IIIS) 的一年级博士生。高阳
 高阳,上海期智研究院 PI,清华大学交叉信息研究院助理教授。于美国加州大学伯克利分校获得博士学位,师从 Trevor Darrell 教授。在获得博士学位后,于加州伯克利大学与 Pieter Abbeel 等人合作完成了博士后研究。研究方向为强化学习与机器人。高阳博士目前主持具身视觉与机器人实验室 (Embodied Vision and Robotics,简称EVAR Lab),专注于利用人工智能技术赋能机器人,致力于打造通用的具身智能框架。4最佳论文奖本次 CoRL 2024 也已经宣布了最佳论文的获奖名单,分别为来自 Kuo-Hao Zeng 等人的《PoliFormer: Scaling On-Policy RL with Transformers Results in Masterful Navigators》,和来自 Franck Djeumou 等人的《One Model to Drift Them All》。
高阳,上海期智研究院 PI,清华大学交叉信息研究院助理教授。于美国加州大学伯克利分校获得博士学位,师从 Trevor Darrell 教授。在获得博士学位后,于加州伯克利大学与 Pieter Abbeel 等人合作完成了博士后研究。研究方向为强化学习与机器人。高阳博士目前主持具身视觉与机器人实验室 (Embodied Vision and Robotics,简称EVAR Lab),专注于利用人工智能技术赋能机器人,致力于打造通用的具身智能框架。4最佳论文奖本次 CoRL 2024 也已经宣布了最佳论文的获奖名单,分别为来自 Kuo-Hao Zeng 等人的《PoliFormer: Scaling On-Policy RL with Transformers Results in Masterful Navigators》,和来自 Franck Djeumou 等人的《One Model to Drift Them All》。PoliFormer: Scaling On-Policy RL with Transformers Results in Masterful Navigators
论文作者:Kuo-Hao Zeng, Zichen Zhang, Kiana Ehsani, Rose Hendrix, Jordi Salvador, Alvaro Herrasti, Ross Girshick, Aniruddha Kembhavi, Luca Weihs 论文摘要:研究团队提出了 POLIFORMER(Policy Transformer),这是一个仅使用 RGB 的室内导航代理,通过端到端的强化学习在规模上进行训练,并且能够在没有适应的情况下泛化到现实世界。POLIFORMER 使用了一个基础的视频变压器编码器和因果变压器解码器,实现了长期记忆和推理能力。它经过数亿次交互,在各种环境中进行了训练,利用并行化和多机部署以实现高效训练和高吞吐量。
论文摘要:研究团队提出了 POLIFORMER(Policy Transformer),这是一个仅使用 RGB 的室内导航代理,通过端到端的强化学习在规模上进行训练,并且能够在没有适应的情况下泛化到现实世界。POLIFORMER 使用了一个基础的视频变压器编码器和因果变压器解码器,实现了长期记忆和推理能力。它经过数亿次交互,在各种环境中进行了训练,利用并行化和多机部署以实现高效训练和高吞吐量。 POLIFORMER 是一个精通的导航器,在两个不同的实施例中——LoCoBot 和 Stretch RE-1机 器人,以及四个导航基准测试中都产生了最先进的结果。它突破了以往工作的局限,实现了 CHORES-S 基准测试中前所未有的 85.5% 的成功率,绝对成功率提高了 28.5%。POLIFORMER 还可以轻松扩展到多种下游应用,如物体跟踪、多对象导航和开放词汇导航,无需微调。
POLIFORMER 是一个精通的导航器,在两个不同的实施例中——LoCoBot 和 Stretch RE-1机 器人,以及四个导航基准测试中都产生了最先进的结果。它突破了以往工作的局限,实现了 CHORES-S 基准测试中前所未有的 85.5% 的成功率,绝对成功率提高了 28.5%。POLIFORMER 还可以轻松扩展到多种下游应用,如物体跟踪、多对象导航和开放词汇导航,无需微调。One Model to Drift Them All: Physics-Informed Conditional Diffusion Model for Driving at the Limits
论文作者:Franck Djeumou, Thomas Jonathan Lew, NAN DING, Michael Thompson, Makoto Suminaka, Marcus Greiff, John Subosits 论文摘要:如果使自动驾驶车辆能够在轮胎力饱和的极限条件下可靠运行,将提高它们的安全性,特别是在紧急避障或恶劣天气等场景中。然而,解锁这一能力由于任务的动态本质和对道路、车辆及其动态相互作用的不确定属性的高敏感性而具有挑战性。
论文摘要:如果使自动驾驶车辆能够在轮胎力饱和的极限条件下可靠运行,将提高它们的安全性,特别是在紧急避障或恶劣天气等场景中。然而,解锁这一能力由于任务的动态本质和对道路、车辆及其动态相互作用的不确定属性的高敏感性而具有挑战性。受到这些挑战的启发,研究团队提出了一个框架,利用包含不同环境中不同车辆轨迹的无标签数据集,学习用于高性能车辆控制的条件扩散模型。
研究团队设计的扩散模型能通过物理信息驱动的动力学模型的多模态参数分布来捕捉复杂数据集的轨迹分布。通过在生成过程中进行在线测量,将扩散模型集成到实时模型预测控制框架中,用于在极限条件下驾驶,并展示了它能够即时适应给定的车辆和环境。 在丰田Supra和Lexus LC 500上的广泛实验表明,单个扩散模型在操作时能够在不同轮胎和不同道路条件下可靠地实现自动驾驶漂移。该模型在特定任务上的专家模型的性能匹配,同时在泛化到未见条件方面表现优于它们,为自动驾驶在处理极限下的通用、可靠方法铺平了道路。
在丰田Supra和Lexus LC 500上的广泛实验表明,单个扩散模型在操作时能够在不同轮胎和不同道路条件下可靠地实现自动驾驶漂移。该模型在特定任务上的专家模型的性能匹配,同时在泛化到未见条件方面表现优于它们,为自动驾驶在处理极限下的通用、可靠方法铺平了道路。雷峰网成立了机器人读者群,希望进群的读者请添加编辑微信 aitechreview、并备注姓名-单位-职位。

