吴所谓(Ethan) 得物技术
2025年03月05日 18:31 上海

目录
一、背景
二、ANTLR4 简介
1. ANTLR4 特性
2. ANTLR4 的应用场景
3. ANTLR4入门
三、SparkSQL介绍
四、技术实现
1. 语法设计
2. 语法补全
3. 语法校验
4. 性能
5.编辑器应用
五、大模型下的SQL编辑器应用
1. NL2SQL应用场景
2. NL2SQL自动补全
六、总结
一
背景
随着得物离线业务的快速增长,为了脱离全托管服务的一些限制和享受技术发展带来的成本优化,公司提出了大数据Galaxy开源演进项目,将离线业务从全托管且封闭的环境迁移到一个开源且自主可控的生态系统中,而离线开发治理套件是Galaxy自研体系中一个核心的项目,在数据开发IDE中最核心的就是SQL编辑器,我们需要一个SQL解析引擎在SQL编辑提供适配得物自研Spark引擎的语法定义,实时语法解析,语法补全,语法校验等能力,结合业内dataworks和dataphin的实践,我们最终选用ANTLR作为SQL解析引擎底座。
二
ANTLR4 简介
ANTLR(一种语法解析引擎工具)是一个功能强大的解析器生成器,用于读取、处理、执行或翻译结构化文本或二进制文件。它广泛用于构建语言、工具和框架。ANTLR可以根据语法规则文件生成一个可以构建和遍历解析树的解析器。
ANTLR4 特性
ANTLR4 是一个强大的工具,适合用于语言处理、编译器构建、代码分析等多种场景。它的易用性、灵活性和强大的特性使得它成为开发者的热门选择。
强大的文法定义:ANTLR4 允许用户使用简单且易读的文法语法来定义语言的结构。这使得创建和维护语言解析器变得更加直观,同时在复杂文法构造上支持左递归文法、嵌套结构以及其他复杂的文法构造,使得能够解析更复杂的语言结构。抽象语法树遍历:ANTLR4 可以生成抽象语法树,使得在解析源代码时能够更容易地进行分析和变换。AST 是编译器和解释器的核心组件。同时提供了简单的 API 来遍历生成的语法树,使得实现代码分析、转换等操作变得简单自动语法错误处理:ANTLR4 提供了内置的错误处理机制,可以在解析过程中自动处理语法错误,并且可以自定义错误消息和处理逻辑可扩展性:ANTLR4 允许用户扩展和自定义生成的解析器的行为。例如,您可以自定义解析器的方法、错误处理以及其他功能。工具&社区生态:ANTLR4 提供了丰富的工具支持,包括命令行工具、集成开发环境插件和可视化工具,可以帮助您更轻松地开发和调试解析器。同时拥有活跃的社区,提供了大量的文档、示例和支持。这使得新用户能够快速上手,并得到必要的帮助。ANTLR4 的应用场景
Apache Spark: 流行的大数据处理框架,使用ANTLR作为其SQL解析器的一部分,支持SQL查询。
Twitter: Twitter 使用ANTLR来解析和分析用户的查询语言,这有助于他们的搜索和分析功能。
IBM: IBM使用ANTLR来支持一些其产品和工具中的DSL(领域特定语言)解析需求,例如,在其企业集成解决方案中。
ANTLR4入门
ANTLR元语言
为了实现一门计算机编程语言,我们需要构建一个程序来读取输入语句,对其中的词组和符号进行识别处理,即我们需要语法解释器或者翻译器来识别出一门特定语言的所有词组,子词组,语句。我们将语法分析过程拆分为两个独立的阶段则为词法分析和语法分析。

ANTLR语法遵循了一种专门用来描述其他语言的语法,我们称之为ANTLR元语言(ANTLR’s meta-language)。ANTLR元语句是一个强大的工具,可以用来定义编程语言的语法。通过定义词法和语法规则,可以基于antlr生成解析器和词法分析器。
1、自顶向下
在语言结构中,整体的辨识都是从最粗的粒度开始,一直进行到最详细的层次,并把它们编写成为语法规则,ANTLR4就是采用自顶向下的,词法语法分离,上下文无关的语法框架来描述语言。
// MyGLexer.g4lexer grammar MyGLexer;SEMICOLON: ';';LEFT_PAREN: '(';RIGHT_PAREN: ')';COMMA: ',';DOT: '.';LEFT_BRACKET: '[';RIGHT_BRACKET: ']';LEFT_BRACES: '{';RIGHT_RACES: '}';EQ: '=';FUNCTOM: 'FUNCTION';LET: 'LET';CONST: 'CONST';VAR: 'VAR';IF: 'IF';ELSE: 'ELSE';WHILE: 'WHILE';FOR: 'FOR';RETURN: 'RETURN';// MyGParser.g4parser grammar MyGParser;options { tokenVocab = MyGLexer;}// 入口规则program: statement* EOF;statement: variableDeclaration | functionDeclaration | expressionStatement | blockStatement | ifStatement | whileStatement | forStatement | returnStatement; ......2、语言模式
计算机语言常见4种语言模式:序列(sequence)、选择(choice)、词法符号依赖 (token dependency),以及嵌套结构(nested phrase)。以下是ANTLR对4种模式的语法规则描述。

3、语法歧义
在自顶向下的语法和手工编写的递归下降语法分析器中,处理表达式都是一件相当棘手的事情,这首先是因为大多数语法都存在歧义,其次是因为大多数语言的规范使用了一种特殊的递归方式,称为左递归。
expr : expr '*' expr | expr '+' expr | INT ;我们举个运算符优先级带来的语法歧义问题,同样的规则可以匹配多个输入字符流。

在其他语法工具中,通常通过指定额外的标记来指定运算符优先级。而在ANTLR4中通过备选分支的排序来指定优先级,越靠前优先级越高。
代码自动生成
ANTLR可以根据lexer.g4和parser.g4自动生成词法分析器,语法分析器,监听器,访问器等。
antlr4ng -Dlanguage=TypeScript -visitor -listener -Xexact-output-dir -o ./src/lib ./src/grammar/*.g
语法解析与业务逻辑解耦
在ANTLR4中语法解析和业务逻辑的高度解耦是一个重要的设计理念,优点就是同一个 AST 结构能够在不同的业务逻辑实现之间实现复用。不同的业务逻辑(如执行、转换、优化等)可以对同一个 AST 进行不同的处理,而不需要关心解析过程。核心几个设计方案如下:
访问者模式:ANTLR4通过访问者模式支持业务代码可访问特定“词法”或“语法”节点执行自定义的操作,通过这个方式完全解耦AST(抽象语法树)生成和业务逻辑,词法分析器和解释器专注于AST生成,而业务可以通过访问器的扩展支持业务定制化诉求。语法和语义的独立性:ANTLR4中可以独立进行语法解析和语义分析,可以在 AST 中进行语义检查和业务逻辑处理。这种分离使得开发者可以更灵活地处理输入的语法和语义。AST生成:ANRL4通过语法解析器生成结构化AST(抽象语法树),不同业务逻辑可以不断复用同一个AST。上下文模式:解析器在处理输入数据时,上下文会在解析树中传递信息。每当进入一个新的语法规则时,都会创建一个新的上下文实例上下文可以存储解析过程中需要的临时信息,例如变量的值、数据类型等。上下文信息主要结合访问器模式进行使用,同时也解决了在解析复杂语句如多层嵌套结构的层级调用问题。三
SparkSQL介绍
Spark SQL 是 Apache Spark 的一个模块,专门用于处理结构化数据,Spark SQL 的特点包括:
高效的查询执行:通过 Catalyst 优化器和 Tungsten 执行引擎,Spark SQL 能够优化查询执行计划,提升查询性能。与 Hive 的兼容性:Spark SQL 支持 HiveQL 语法,使得用户可以轻松迁移现有的 Hive 查询。支持多种数据源:Spark SQL 可以从多种数据源读取数据,包括 HDFS、Parquet、ORC、JDBC 等。四
技术实现
语法设计
在Aparch Spark源码中就是使用ANTLR4来解析和处理SQL语句,以下为Apach Spark中基于ANTLR元语言定义的词法分析器和语法分析器,在语法定义上我们只需要基于这套标准的SparkSQL语法去适配得物自研引擎的能力,做能力对齐。
Lexer.g4https://github.com/apache/spark/blob/master/sql/api/src/main/antlr4/org/apache/spark/sql/catalyst/parser/SqlBaseLexer.g4Parser.g4https://github.com/apache/spark/blob/master/sql/api/src/main/antlr4/org/apache/spark/sql/catalyst/parser/SqlBaseParser.g4语法补全
以下我们以字段补全场景为例解析从语法定义,语法解析,语法补全,上下文信息采集各个流程节点剖析最后完成的表字段信息精准推荐。在下列语法场景中,存在多层Select语法嵌套,同时表du_emr_test.empsalary tableB和表du_emr_test.hujh_type_tk AS tableB设置了同一别名, 如图在父子查询中都使用了同一个表别名(tableB),当用户在父子查询中分别输入tableB.时,这时候需要结合当前上下文语境,对tableB别名推荐不同表的字段。
SELECT tableB.c1 FROM ( SELECT tableB.empno, tableC.department FROM du_emr_test.empsalary as tableB LEFT JOIN du_emr_test.employees AS tableC WHERE tableC.department = tableB.depname ) AS tableALEFT JOIN du_emr_test.hujh_type_tk AS tableBWHERE tableB.c1 = tableA.dename


在子查询中我们期望推荐tableB来自du_emr_test.empsalary tableB的字段信息,而在最外层中我们期望的是du_emr_test.hujh_type_tk的字段,如上图。
基于以上场景我们核心要解决2个问题:
问题1:当前光标应该提示哪些推荐语法类型
目前,开源方案ANTLR-C3引擎就能完美解决我们问题,用户在编辑器实时输入时,获取当前光标位置,实时做语法解析,然后基于开源的ANTLR-C3引擎能力结合ANTLR 生成的AST即可获取当前光标位置所需要的语法规则。
问题2: 获取当前上下文信息以实现精准推荐
根据不同业务场景需要采集的上下文信息不同,基于字段推荐的场景,我们需要获取当前光标位置处可以推荐的表信息,表别名信息,结合编辑器能力实时获取表对应的字段信息进行字段推荐补全,而上下文信息的采集,我们可以通过ANTLR生成的监听器来实现。
语法定义
以下我们用ANTLR元语言实现一段简化版的SQL查询场景的语法规则(QueryStatment),方便我们理解。
lexer grammar SqlLexer;// 基础词法COMMA: ',';LEFT_PAREN: '(';RIGHT_PAREN: ')';IDENTIFY: (LETTER | DIGIT | '_' | '.')+;fragment DIGIT: [0-9];fragment LETTER: [A-Z];SEMICOLON: ';';parser grammar SqlParser;program: statment* EOF;statment: queryStatment SEMICOLON?;// 查询语句queryStatment: SELECT columnNames FROM ( tableName | (LEFT_PAREN queryStatment LEFT_PAREN) ) whereExpression? relationsExpresssion? SEMICOLON?;// 字段columnNames: columnName (COMMA columnName)*;tableName: IDENTIFY AS? tableAlis;tableAlis: IDENTIFY;columnName: IDENTIFY AS? columnAlis;columnAlis: IDENTIFY;whereExpression: WHERE booleanExpression;booleanExpression: (NOT | BANG) booleanExpression # logicalBinary | left = booleanExpression operator = AND right = booleanExpression # logicalBinary | left = booleanExpression operator = OR right = booleanExpression # logicalBinary;relationsExpresssion: LEFT JOIN tableName whereExpression? | RIGHT JOIN tableName whereExpression?;代码生成

以下是部分生成代码:
1、词法分析器
// SqlLexer.ts public static readonly COMMA = 1; public static readonly LEFT_PAREN = 2; public static readonly RIGHT_PAREN = 3; public static readonly IDENTIFY = 4; public static readonly SEMICOLON = 5; // 词法分析器可以使用的通道 public static readonly channelNames = [ "DEFAULT_TOKEN_CHANNEL", "HIDDEN" ]; // 包含了所有字面量记号的名称 public static readonly literalNames = [ null, "','", "'('", "')'", null, "';'" ]; // 包含为每个记号分配的符号名,这些符号在生成解析器时用于标识记号 public static readonly symbolicNames = [ null, "COMMA", "LEFT_PAREN", "RIGHT_PAREN", "IDENTIFY", "SEMICOLON" ]; // ANTLR 生成的类中的一个字段,列出了所有定义的规则 public static readonly ruleNames = [ "COMMA", "LEFT_PAREN", "RIGHT_PAREN", "IDENTIFY", "DIGIT", "LETTER", "SEMICOLON", ];2、语法分析器
ANTLR自动为每个规则生成了一个解析方法,以下是tableName的 ANTLR 中的解析器方法,具备了处理标识符、可选的别名和错误处理的能力。
// SQLParse.ts// ANTLR自动生成了一个解析 SQL 表名的 ANTLR 中的解析器方法,具备了处理标识符、可选的别名和错误处理的能力public tableName(): TableNameContext { let localContext = new TableNameContext(this.context, this.state); this.enterRule(localContext, 8, SqlParser.RULE_tableName); let _la: number; try { this.enterOuterAlt(localContext, 1); { this.state = 60; this.match(SqlParser.IDENTIFY); this.state = 62; this.errorHandler.sync(this); _la = this.tokenStream.LA(1); if (_la === 8) { { this.state = 61; this.match(SqlParser.AS); } } this.state = 64; this.tableAlis(); } } catch (re) { if (re instanceof antlr.RecognitionException) { this.errorHandler.reportError(this, re); this.errorHandler.recover(this, re); } else { throw re; } } finally { this.exitRule(); } return localContext; }自动补全
ANTLR4代码补全核心(antlr4-c3) 是一个开创性的工具,它为ANTLR4生成的解析器提供了一个通用的代码补全解决方案。无论你的项目是处理哪种编程语言或领域特定语言(DSL),只要是基于ANTLR就能够利用这个库实现精准的代码建议和自动补全,极大地增强开发体验。通过antlr4-c3 能力我们通过手动配置需要收集的语法规则,获取在当前光标处需要推荐的语法规则类型。
1、语法规则
通过ANTLR4工具我们可以自动生成Sqllexer.ts词法解析器,SqlParser.ts语法解析器,SqlParserLister.ts访问器,SqlParseVisitor.ts监听器,在SqlParser 语法解析器自动生成了我们在语法定义中的语法规则。
preferredRules = new Set([ SqlParser.RULE_tableName, SqlParser.RULE_columnName,]);2、代码补全
以下我们实现一套简化版的代码补全能力。
当用户在编辑器实时输入时,调用getSuggestionAtCaretPosition获取当前语境中需要推荐的信息,包含语法规则,关键词,上下文信息,在结合业务层数据做自动补全,其中包含5个核心步骤:
获取当前语法解析器实例。获取当前光标位置对应的Token。生成AST。获取当前语境上下文信息。通过ANTLR-C3获取当前位置候选语法规则。public getSuggestionAtCaretPosition( sqlContent: string, caretPosition: CaretPosition preferredRules: Set ): Suggestions | null { // 1、 使用SqlParse解析器获取 const sqlParserIns = new SqlParse(sqlContent) // 2、获取当前光标处token const charStreams = CharStreams.fromString(sqlContent); const lexer = new SqlLexer(charStreams); const tokenStream = new CommonTokenStream(lexer); tokenStream.fill() const allTokens = tokenStream.getTokens(); let caretTokenIndex = findCaretToken(caretPosition, allTokens); // 3、获取AST抽象语法树 const parseTree = sqlParserIns.program() // 4、通过监听器采集上下文表信息(下面上下文分析部分阐述细节) const tableEntity = getTableEntitys() // 异常场景兼容存在多条sql, 获取有效最小SQL范围给到antlr4-c3做推荐。 const statementCount = splitListener.statementsContext?.length; const statementsContext = splitListener.statementsContext; // 5、antlr4-c3接入获取推荐语法规则 let tokenIndexOffset: number = 0; const core = new CodeCompletionCore(sqlParserIns); // 推荐规则 来自SQLparse解析器的规则(元语言定义) core.preferredRules = preferredRules; // 通过AST和当前光标Token获取推荐类型 const candidates = core.collectCandidates(caretTokenIndex, parseTree); // ruleType -> preferredRules // const [rules, tokens] = candidate; const rules = []; const keywords = [ for (let candidate of candidates.rules) { const [ruleType] = candidate; let synContextType; switch (ruleType) { case SqlParser.RULE_tableName: { syntaxContextType = 'table'; break; } case SqlParser.RULE_columnName: { syntaxContextType = 'column'; break; } default: break; } if (synContextType) { rules.push(syntaxContextType) } } // 获取对应keywords for (let candidate of candidates.tokens) { const displayName = sqlParserIns.vocabulary.getDisplayName(candidate[0]); const keyword = displayName.startsWith("'") && displayName.endsWith("'") ? displayName.slice(1, -1) : displayName keywords.push(keyword); } return { rules, keywords, tableEntity }; }在这里我们简化了流程,忽略了很多异常case的处理,自动补全的前提是在当前语法规则正确,而在多级子查询嵌套场景我们需要考虑到过滤异常QueryStatment, 在当前光标出最小范围有效的QueryStatment做补全。这时候需要配合监听器去做上下文采集做容错性更高的自动补全。
上下文分析

如图:每个table都归属于一个QueryStatment表达式, 查询中又存在子层级查询的嵌套。我们需要通过上下文收集以下信息:
每个查询语句的信息,包含Position位置信息,记录当前的查询开始行,结束行,开始列,结束列。查询语句的关联关系,即记录当前查询语句父级查询语句对象。表实体信息包含表名,表位置信息,表别名信息,当前表归属于那个查询语句。则我们需要监听3个语法规则包含QueryStatment, TableName,TableAlias, 采集QueryStatment信息,Table信息同时将table与当前归属的QueryStatment做关联, 还有与别名信息作配对关联。这就要求在不同监听器之间的信息需要做共享,上下文信息需要做传递和保留。ANTLR常用的3种信息共享方案包含:
使用访问器方法来返回值,使用类成员在事件方法之间共享数据,在语法定义中使用树标记来存储信息。在这里我们使用第二种(在这里我们简化了SQL的语法定义,在实际场景中语法层级深度和复杂度远比当前高,这也使得方案1和3实际操作起来更麻烦,规则嵌套层级深使得方案一和方案三开发成本和维护成本更高)
1、监听器(SqlParserLister)
通过ANTLR4工具我们可以自动生成SqlParserLister.ts监听器进行自定义扩展。
// SqlParserListener.tsexport QueryStatmentContext extends antlr.ParserRuleContext { public override enterRule(listener: SqlParserListener): void { if(listener.enterQueryStatment) { listener.enterQueryStatment(this); } } public override exitRule(listener: SqlParserListener): void { if(listener.exitQueryStatment) { listener.exitQueryStatment(this); } } } export TableNameContext extends antlr.ParserRuleContext { public override enterRule(listener: SparkSqlParserListener): void { if(listener.enterTableName) { listener.enterTableName(this); } } public override exitRule(listener: SparkSqlParserListener): void { if(listener.exitTableName) { listener.exitTableName(this); } } }// ....export TableAliasContext extends antlr.ParserRuleContext { public KW_AS(): antlr.TerminalNode | null { return this.getToken(SparkSqlParser.KW_AS, 0); } public override enterRule(listener: SparkSqlParserListener): void { if(listener.enterTableAlias) { listener.enterTableAlias(this); } } public override exitRule(listener: SparkSqlParserListener): void { if(listener.exitTableAlias) { listener.exitTableAlias(this); } }}2、自定义监听器扩展
通过SqlParserListener我们可以自定义采集上下文信息。在
监听进入QueryStatment表达式采集当前表达式信息到_queryStmtsStack。监听退出TableNameToken时采集当前Table信息,并关联当前QueryStatment。监听退出TableAliasToken时采集信息,并关联到Table实体。监听退出QueryStatment表达式推出_queryStmtsStack// tableEntityCollect export SqlEntityCollector implements SqlParserListener { super() { this._tableEntitiesSet = new Set(); this._queryStmtsStack = []; this._tableAliasStack = []; this._currentTable = ''; } enterQueryStatment(ctx: QueryStatmentContext) { this.pushQueryStmt(ctx); } exitQueryStatment(ctx: QueryStatmentContext) { this.popQueryStmt(); } exitTableName(ctx: TableNameContext) { this.pushTableEntity(ctx); this.setCurrentTable(ctx); } exitTableAlias(ctx: TableAliasContext) { this.pushTableEntity(ctx); } pushQueryStmt() {} // 采集QueryStmt信息 popQueryStmt() {} // 推出当前QueryStmt,进入下个同级Stmt pushTableEntity() {} // 采集当前表信息,关联当前Stmt pushTableEntity() {} // 采集关联表 enterProgram() {} // 清空重置 getTableEntity() { return this.TableEntity(ctx) } }在这里我们简化了语法定义的规则便于讲解,但在实际中语法规则的整体嵌套层级是很深的,从以下的SparkSql语法定义中我们可以看到右侧聚合的表达式高达200+个,单个表达式的备选分支最多高达140+,这也加大了上下文分析采集的复杂度,即我们无法简单的从QueryStmt当前QueryStatmentContext中获取全量信息。

3、触发监听器采集上下文信息
getTableEntitys() { const collectListener = new SqlEntityCollector(sqlContent, caretTokenIndex); const parse = new SqlParse(sqlContent); const parseTree= sqlParserIns.program(); ParseTreeWalker.DEFAULT.walk(collectListener, parseTree); return collectListener.getTableEntity()}语法校验
ANRLR在生成语法分析器中内置了自动错误报告和恢复策略,能够在遇到句法错误时自动产生错误消息,为每个句法错误产生一条错误消息。
词法错误
常见的词法错误包含字符遗漏,词法错误。举个例子,在spark标准语法定义中 tableName规则不支持表变量场景(${variable}),如果要兼容这里词法,就需要在语法定义中变更tableName的语法规则定义。

以下是语法定义变更:
新增词法规则$, {, }。新增语法规则identifyVar支持变量模式。SqlLexer.g4// 新增词法LEFT_BRACE : '{';RIGHT_BRACE : '}';VARIABLE : '$';SqlParse.g4// before tableName: IDENTIFY AS? tableAlis; tableName: identifyVar AS? tableAlis; identifyVar : IDENTIFY // odps_table_a | IDENTIFY? VARIABLE LEFT_BRACE IDENTIFY RIGHT_BRACE IDENTIFY? // odps_table_a_${variable} odps_table_a_${prefix_variable}_abs自动恢复机制
语法分析器不应该在遇到非法的成员定义时结束,而是应尽最大可能匹配到一个合法的类定义,ANRTL4自动错误恢复机制能在语法分析器在发现语法错误后还能继续进行尝试语法解析和自动恢复。
1、异常捕获
ANRLT自动生成的语法解析器中自动为每个规则包裹异常捕获能力,并在catch中尝试错误恢复。

2、恢复策略
一般情况下,语法分析器在遇到无法匹配的错误时会尝试最简单的符号补全和移除来尝试解析,都不管用时,这时候就会用更高阶的策略来进行恢复。包括扫描后续词法符号来恢复,从不匹配的词法符号中恢复,从子规则的错误中恢复,捕获失败的语义判定。
虽然ANTLR提供了很多策略来进行错误恢复,但在实际业务场景中,需要结合考虑语法、语境的复杂度去权衡性能与更友好的错误提示之间的抉择。在复杂场景中ANTLR表现并不理想,在一些复杂语法和语境的情况下解析器在检测错误时难以做出合理的决策,例如:递归和嵌套结构中会使得错误恢复变得很复杂,导致解析器无法做出合理决策。还有在上下文敏感的语境中,错误恢复机制基本无法提供有效恢复。
性能
在 ANTLR 4 中,语法复杂度、语法歧义、语法规则嵌套深度与预测算法的选择都会显著影响解析器的性能和准确性。Spark SQL语法规则达200+,备选分支最高达140, 嵌套深度达20+,同时又存在负责循环嵌套场景, 这也意味着在整个语法解析,语法错误的处理过程是很复杂的,当遇到复杂大SQL量和一片狼籍的语法错误SQL,会导致语法解析过程变得缓慢引发性能问题。目前在性能优化上,有以下几个方向。
缓存优化
在antlr4中词法解析和语法解析能力和业务是完全解耦的,这也意味着底层基于同个SQL内容解析出来的tokens和parserTree都是可以在不同业务逻辑应用里复用。我们可以通过缓存tokens,parseTree减少词法解析和语法解析的损耗。
语法优化
通过减少语法树的层级和优化表达式减少解析过程中“二义性”的次数,可以加速语法解析的速度,优化AST生成性能。合理使用语法定义中用法,例如树标记(用于上下文通信数据共享),在语法解析过程中会为每个标记生成上下文,这也意味着每个局部结果都会保留,会有更大的内存消耗。
预测模型选择
在语法解析中不同预测模型的选择对解析性能有显著影响,针对不同的场景需要评估时效性与正确性之间的衡量。
ANTLR4预测模型:
https://www.antlr.org/api/Java/org/antlr/v4/runtime/atn/PredictionMode.html

我们可以选择性价比更高的SLL预测模型作为语法分析策略,结合定制化的错误监听器做错误纠正。
编辑器应用
编辑器集成
与MonacoEditor集成流程可查看此文章 https://blog.shizhuang-inc.com/article/MTUzNzY?fromType=personal_blog
辅助编程
1、信息项提示(表,函数,字段)

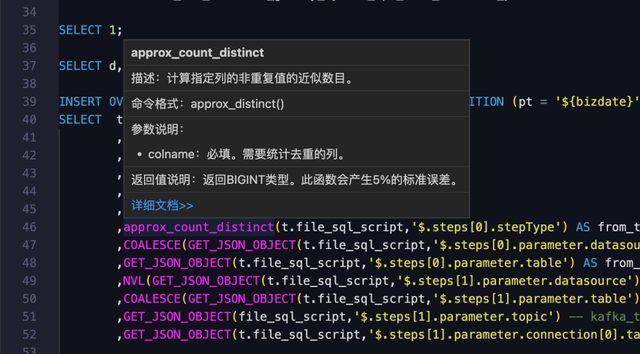

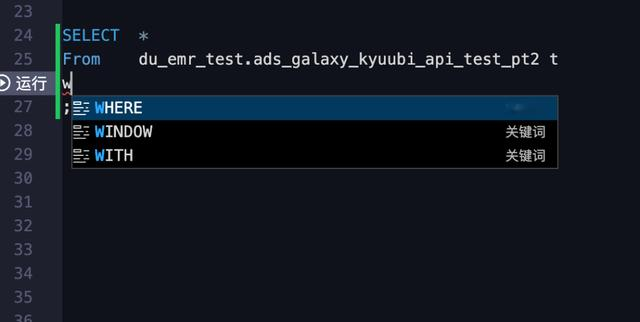
2、自动补全(库,表,字段,语法)


五
大模型下的SQL编辑器应用
随着大模型的蓬勃发展,在数据产品中的应用也逐步得到了验证和落地,目前,Galaxy还没有接入Copilot, 内部暂时还没有基于SQL的Copilot。业界较成熟的是阿里云的Dataworks, DataWorks于2023年推出了Copilot 产品, 核心2个方向,一个方向是智能 SQL 编程助手,辅助 SQL 编程,支持 NL2SQL 及 SQL 代码补全;另一个方向是 AI Agent,提供 LUI(自然语言用户界面),以提升产品功能操作的便捷性和用户体验。
NL2SQL应用场景
基于SQL的Copilot一般在以下几个应用场景比较深入和广泛的落地效果:简单数据查询,SQL 优化与转换,SQL 语法查询与讲解, 函数查询,功能咨询,注释生成,SQL 解释,SQL 一键纠错。
NL2SQL自动补全
代码补全是编程类 Copilot 的主要场景和能力,单市场上主流的编程类 Copilot 对 SQL 支持的好的并不多见。众所周知,SQL 代码补全比其他高级语言的代码补全更具挑战性,主要原因有以下几个方面:
上下文和环境的依赖性:SQL 代码不是独立存在的,而是依赖于数据表的元数据信息以及表与表之间的关联关系。SQL 语义多样性:实现同一种查询结果,可以有多种 SQL 写法,如何实现“最佳”写法存在挑战。语法简洁但高度专业化:SQL 语法简洁但每一个关键字、函数或语法都有特定的含义,大模型要准确理解这些得通过针对性的训练学习。执行计划和性能考量: 这跟数据库底层的执行计划有关,需要考虑如何书写才能使 SQL 的性能最优。数据库特异性:市面上不同的数据库往往存在不同的 SQL 方言,存在差异,针对这种差异性我们要投入大量时间做 SQL 数据集准备、数据标注、模型微调。高度业务相关性:SQL 语句通常与特定业务高度相关,比如一个指标存在特定的计算口径,这是与公司业务相关,通用的大模型也无法提前学习。目前较成熟的代码补全核心场景主要在有规律的代码连续推荐场景(例如:字段、字段别名推荐,注释推荐、分区字段推荐、Group by 字段推荐,上下文自动联想推荐等)。
六
总结
通过SQL引擎能力建设我们在Galaxy数据研发IDE上支持了个性化词法规则定制能力,包含字段别名支持中文, 表变量等场景, 同时通过语法解析和监听器能力,支持实时识别各类的语法规则,包含表,函数,字段等做辅助编程提示和做精准化的库,表,字段代码补全和推荐。
后续我们仍面临很大的挑战,在非专业的数据开发背景、复杂的业务定制需求、语言定义的复杂性和嵌套深度等因素共同导致了解析器的开发难度。目前,在语法校验自动纠错提示上,虽然ANTLR的提供了自动错误恢复机制但整体表现并不理想,后续2个方向,第一,接入大模型的能力。第二,从基础语法定义上进行重构,减少语法歧义和层级优化。为了应对这些挑战,我们需要加强对 ANTLR 和 Spark SQL语言,数据处理的理解,以便顺利使用和扩展解析器。
参考资料
ANTLRANTLR4-C3DataWorks Copilot:大模型时代数据开发的新范式ANTLR4权威指南 - [美] 特恩斯·帕尔 著