1、百度:全栈技术积累颇丰,AI应用场景全覆盖
模型与技术积累丰厚,传统业务奠定先发优势。从模型上看,百度手握文心系列模型(ERNIE1.0,ERNIE2.0,ERNIE3.0,ERNIE3.0-Titan)和PLATO系列模型(PLATO1,PLATO2,PLATO-XL),均积累多年,且和自家核心业务息息相关。此外,百度还有一个从软件到AI芯片全栈打通的Paddle训练框架生态,其对标PyTorch和TenserFlow,也属国内独家。在核心业务上,百度在国内牢牢把握着搜索端入口,相比于谷歌则更加从容,不需要应付同行的快速挑战,可以以自己的节奏过渡到“大模型+搜索”的问答搜索业务新模式。同时,基于海量中文数据集沉淀,百度也将获得海量中文问答式搜索反馈数据,该稀缺数据足以让百度巩固和继续扩大在这方面的优势,形成“数据飞轮”效应。
文心大模型处于百度全栈布局中的模型层。百度经过11年积累了全栈人工智能技术,从芯片层、框架层、模型层到应用层。这四层之间形成层到层到反馈、端到端优化,尤其是模型层的文心大模型和框架层的飞桨(产业级开源开放平台),在开发文心一言的过程中,它们的协同优化起到了至关重要的作用。模型层的文心大模型包括NLP大模型、CV大模型和跨模态大模型,在此基础上开发了大模型的开发工具、轻量化工具和大规模部署工具,而且支持零门槛的AI开发平台以及全功能AI开发平台。

2019年第一个文心大模型和如今的文心一言一样是NLP模型,具备三条发展主线。文心NLP大模型发展过程有三条主线,第一条主线是文心ERNIE,文心ERNIE 3.0以及文心ERNIE 3.0 Titan模型当时在SuperGLUE和GLUE都超过了人类排名第一的水平;第二条主线是文心ERNIE在跨模态、跨语言以及长文档、图模型等方面获得了突出进展,在各种榜单尤其视觉语言相关榜单上获得第一;第三条主线是对话生成大模型文心PLATO,其在对话的流畅性上得到很大提升。

知识增强大模型ERNIE具备持续学习框架。在文心ERNIE的框架中,可以不断从不同的数据和知识上学习,而且不断地构建新任务,比如文本分类任务、问答任务、完形填空任务等。大模型从不同任务中持续学习,使能力得到持续提升,从而拥有更多知识。在此基础上,百度研发了知识增强的预训练模型,该模型能够从大规模知识图谱和海量无结构数据中学习,突破异构数据统一表达的瓶颈问题;该模型也能够融合自编码和自回归结构,既可以做语言理解,也可以做语言生成;另外,基于飞桨4D混合并行技术(4D混合并行是指训练的时候同时有4种不同并行方式),能够节省50%的时间,从而实现更高效地支持超大规模模型的预训练。在以上三个特色基础上,百度发布了当时全球首个知识增强的千亿大模型ERNIE3.0,拥有2600亿参数,在60多项的NLP任务上取得世界领先。同时,在这个模型上的实际应用中,能把参数压速到99%,使该模型的效果得到大幅提升。


在Fine-tuning任务上,文心ERNIE可以用在不同任务中,用任务数据做微调。文心ERNIE在21类54个Fine-tuning任务中取得领先。这些任务分布广泛,包括语言理解、语言生成、知识推理等。同时,文心ERNIE在零样本和小样本学习的能力也突出,尤其在文本分类、阅读理解、知识推理、指代消解等任务中取得全面领先。相比Bert,ERNIE在理念上引入了知识图谱等外部知识信息,例如语料里的人名、地名、机构名、句子间结构关系和逻辑关系等等。在这些特征的赋能下,相比GPT-3,文心ERNIE在复杂知识推理能力上有8个百分点的绝对提升。

跨语言大模型ERNIE-M解决小语种语料资源不足的问题。在跨语言的学习过程中,中文和英文语种语料资源较为丰富,但诸多小语种语料资源缺乏,因此,百度用少量平行语料和大量非平行语料通过回译的机制进行学习的方式来解决问题。该过程使用统一模型建模了96种语言,并在5类语言任务上刷新世界最好结果,例如在自然语言推断、语义相似度、阅读理解、命名实体识别、跨语言检索等任务中,都获得了极大提升,同时在权威跨语言理解榜单XTREME上获得第一。
跨模态大模型ERNIE-ViL首次引入场景知识,助力跨模态任务有效执行。引入场景知识的目的是为了理解图像中细粒度的语义,比如房子、车子和人之间的关系以及车的颜色等。通过构建场景图的方式,模型能够对图像进行细粒度的语义理解,从而在跨模态任务上取得最好的效果,比如视觉问答、视觉常识推理、图像检索等。ERNIE-ViL在权威视觉常识推理任务VCR榜单上也排名第一。

借助跨模态语义对齐算法,图文转化效果处于全球领先水平。文心ERNIR-ViLG作为全球最大规模的中文跨模态生成大模型,其特点是在一个模型中能同时兼顾文本到图像的生成,以及图像到文本的生成,通过跨模态的语义对齐算法,实现双向生成。现在模型参数规模已经达到了百亿级,并且在效果上领先于OpenAI DALL·E。

ERNIE-Sage图模型通过知识图谱对搜索中的关联信息进行增强。鉴于应用中很多场景具备关联知识,为了建模关联知识,百度提出了文心ERNIE-Sage的图模型。基于该模型,能在搜索中通过文档的Title和Query,去构建Query与Title、Query和Query之间的关系,同时也能通过知识图谱的知识去增强这种关联。为了解决在应用中长尾数据稀疏的问题,百度加入了知识图谱信息以及其他领域知识信息,以便能够更好地增强图模型知识之间的关联,以及通过图学习、预训练方法的加持,来提升文本图语义的理解,这样的模型被百度广泛用在搜索、地图等应用中。在地图中,能够建模POI之间的关系,通过图的模式能够使用户的搜索效率提升,很好地纠错地图语义的理解。
基于隐变量和角色建模,PLATO实现多样化回复。在对话生成中,尤其在开放域的对话生成中,需要对用户的任何话语进行连贯且有意义的回复,任何上文序列都应该有合理的答复且存在多个合理的答复。基于该现象,百度提出了隐变量的大规模对话生成模型,通过隐变量和角色建模,能够很好实现建模,以及针对上文生成多样化回复。基于该框架发布的文心PLATO-XL具备规模大、效果好、能耗低的特点,PLATO-XL有110亿个参数,其模仿人类自然语气的能力很强,且拿下了“全球对话技术顶级赛事DSTC”等多个冠军。

2、腾讯:优化大模型训练,加速大模型应用落地
腾讯2022年底发布国内首个低成本、可落地的NLP万亿大模型——混元AI大模型。HunYuan协同腾讯预训练研发力量,旨在打造业界领先的AI预训练大模型和解决方案,以统一的平台,实现技术复用和业务降本,支持更多的场景和应用。当前HunYuan完整覆盖NLP大模型、CV大模型、多模态大模型、文生图大模型及众多行业/领域任务模型,自2022年4月,先后在MSR-VTT、MSVD等五大权威数据集榜单中登顶,实现跨模态领域的大满贯;2022年5月,于CLUE(中文语言理解评测集合)三个榜单同时登顶,一举打破三项纪录。基于腾讯强大的底层算力和低成本高速网络基础设施,HunYuan依托腾讯领先的太极机器学习平台,推出了HunYuan-NLP 1T大模型并登顶国内权威的自然语言理解任务榜单CLUE。
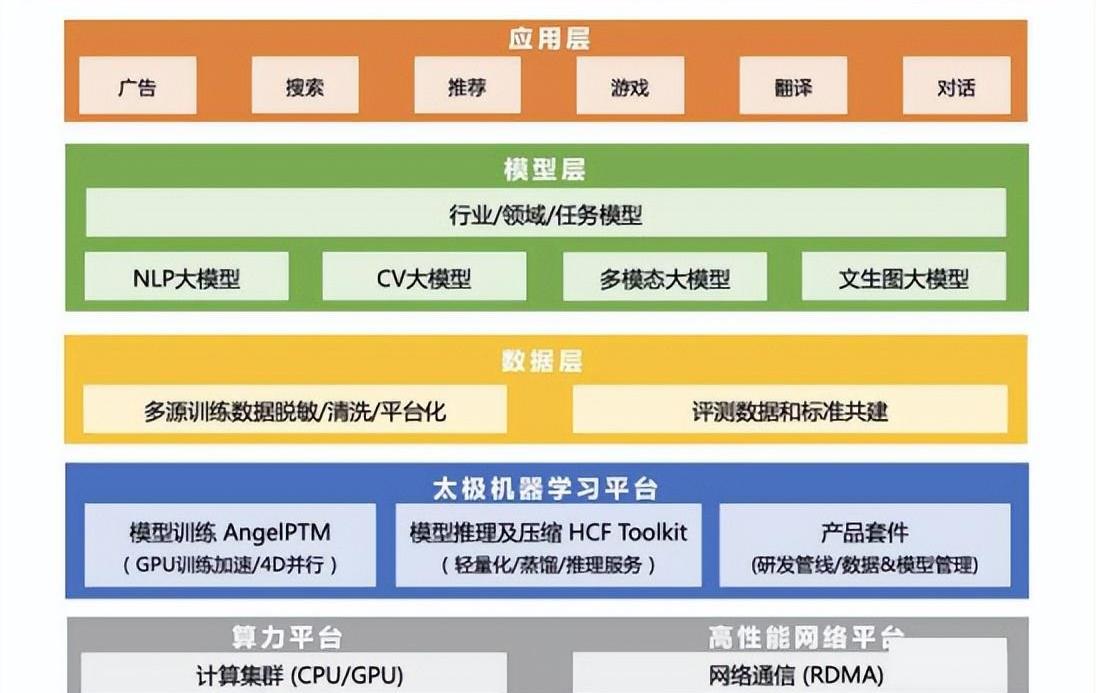

探索大模型应用机制,实现工业界快速落地。HunYuan模型先后在热启动和课程学习、MoE路由算法、模型结构、训练加速等方面研究优化,大幅降低了万亿大模型的训练成本。用千亿模型热启动,最快仅用256卡在一天内即可完成万亿参数大模型HunYuan-NLP 1T的训练,整体训练成本仅为直接冷启动训练万亿模型的1/8。此外,业界基于万亿大模型的应用探索极少,对此腾讯研发了业界首个支持万亿级MoE预训练模型应用的分布式推理和模型压缩套件“太极-HCF ToolKit”,实现了无需事先从大模型蒸馏为中小模型进而推理,即可使用低成本的分布式推理组件/服务直接进行原始大模型推理部署,充分发挥了超大预训练模型带来的模型理解和生成能力的跃升,HunYuan也成为业界首个可在工业界海量业务场景直接落地应用的万亿NLP大模型。

打造高效率开发工具,降低模型训练成本。为了使大模型能够在可接受的推理成本下最大化业务效果,腾讯设计了一套“先蒸馏后加速”的压缩方案实现大模型的业务落地,并推出太极-HCF ToolKit,它包含了从模型蒸馏、压缩量化到模型加速的完整能力,为AI工程师打造从数据预处理、模型训练、模型评估到模型服务的全流程高效开发工具。其中,太极-HCF distributed(大模型分布式推理组件)融合了分布式能力和单卡推理优化,兼顾分布式高效推理能力的构建和易用性建设。太极-SNIP(大模型压缩组件)结合量化、稀疏化和结构化剪枝等多种加速手段,进一步加速了student模型的推理速度。总之,腾讯在技术上从蒸馏框架和压缩加速算法两方面,实现了迭代更快,效果更好,成本更低的大模型压缩组件。
降低显存压力,突破模型参数扩大瓶颈。随着预训练模型的参数不断增大,模型训练需要的存储空间显著增加,如万亿模型仅模型状态需要17000多G显存,仅仅依靠显存严重束缚着模型参数的扩大。因此,基于Zero-Infinity的理念,腾讯自主研发了太极AngelPTM,AngelPTM将多流异步化做到了极致,在充分利用CPU和GPU进行计算的同时最大化的利用带宽进行数据传输和NCCL通信,使用异构流水线均衡设备间的负载,最大化提升整个系统的吞吐。
HunYuan商业化拓展迅速,大模型效益得到验证。HunYuan先后支持了包括微信、QQ、游戏、腾讯广告、腾讯云等众多产品和业务,通过NLP、CV、跨模态等AI大模型,不仅为业务创造了增量价值而且降低了使用成本。特别是其在广告内容理解、行业特征挖掘、文案创意生成等方面的应用,在为腾讯广告带来大幅GMV提升的同时,也初步验证了大模型的商业化潜力。
3、阿里:聚焦通用底层技术,开源释放大模型应用潜力
率先探索通用统一大模型,快速提升参数量级。阿里达摩院一直以来深耕多模态预训练,并率先探索通用统一大模型。2021年,阿里达摩院先后发布多个版本的多模态及语言大模型,在超大模型、低碳训练技术、平台化服务、落地应用等方面实现突破。其中使用512卡V100 GPU实现全球最大规模10万亿参数多模态大模型M6,同等参数规模能耗仅为此前业界标杆的1%,极大降低大模型训练门槛。M6具有强大的多模态表征能力,通过将不同模态的信息经过统一加工处理,沉淀成知识表征,可以为各个行业场景提供语言理解、图像处理、知识表征等智能服务。跟其他大模型类似,M6也是以预训练模型的形式输出泛化能力,下游只需提供场景化数据进行优化微调,就能快速产出符合行业特点的精准模型。2022年4月,清华大学、阿里达摩院等机构联合提出“八卦炉”(BaGuaLu)模型,其为第一项在新一代神威超级计算机上训练脑尺度模型的工作,通过结合特定于硬件的节点内优化和混合并行策略,在前所未有的大型模型上实现了良好的性能和可扩展性,BaGuaLu可以使用混合精度训练14.5万亿参数模型,其性能超过1 EFLOPS,并有能力训练与人脑中突触的数量相当的174万亿参数模型。

持续聚焦大模型通用性及易用性,打造了国内首个 AI 统一底座。2022年9月,达摩院发布阿里巴巴最新通义大模型系列,其打造了国内首个AI统一底座,并构建了通用与专业模型协同的层次化人工智能体系,将为AI从感知智能迈向知识驱动的认知智能提供先进基础设施。通义大模型整体架构中,最底层为统一模型底座,通义统一底座中借鉴了人脑模块化设计,以场景为导向灵活拆拔功能模块,实现高效率和高性能。中间基于底座的通用模型层覆盖了通义-M6、通义-AliceMind和通义-视觉,专业模型层深入电商、医疗、娱乐、设计、金融等行业。

M6-OFA覆盖多模态任务,在一系列视觉语言任务中实现了SOTA性能。基于统一学习范式,通义统一底座中的单一M6-OFA模型,将涉及多模态和单模态(即NLP和CV)的所有任务都统一建模成序列到序列(seq2seq)任务,可以在不引入任何新增结构的情况下同时处理图像描述、视觉定位、文生图、视觉蕴含、文档摘要等10余项单模态和跨模态任务,并达到国际领先水平,这一突破最大程度打通了AI的感官。M6-OFA统一多模态模型在一系列视觉语言任务中实现了SOTA性能,在Image Caption任务取得最优表现,长期在MSCOCO榜单排名第一。

开源深度语言模型,模块化统一趋势明显。通义-AliceMind是阿里达摩院开源的深度语言模型体系,包含了通用语言模型StructBERT、生成式PALM、结构化StructuralLM、超大中文PLUG、多模态StructVBERT、多语言VECO、对话SPACE1.0/2.0/3.0和表格STAR1.0/2.0,过程中形成了从文本PLUG到多模态mPLUG再到模块化统一模型演化趋势。2022年,基于AliceMind/StructBERT模型结果在中文语言理解测评基础CLUE上获得了三榜第一。另外,270亿参数版AliceMind-PLUG也是当时规模最大的开源语言大模型。
视觉大模型在电商、交通等领域应用空间巨大。通义视觉大模型自下往上分为底层统一算法架构、中层通用算法和上层产业应用。根据阿里云社区资料,通用-视觉大模型可以在电商行业实现图像搜索和万物识别等场景应用,并在文生图以及交通和自动驾驶领域发挥作用。

4、华为:昇腾AI打造全栈使能体系,定位行业级CV应用
打造业界首例,盘古NLP与CV大模型赶超迅速。2021年,华为云发布盘古系列超大规模预训练模型,包括30亿参数的视觉(CV)预训练模型,以及与循环智能、鹏城实验室联合开发的千亿参数、40TB训练数据的中文语言(NLP)预训练模型。盘古NLP大模型是业界首个千亿参数中文大模型,具备领先的语言理解和模型生成能力,2021年当时在权威的中文语言理解评测基准CLUE榜单中,盘古NLP大模型在总排行榜及分类、阅读理解单项均排名第一,刷新三项榜单世界历史纪录。盘古NLP大模型预训练阶段学习超40TB文本数据,并通过行业数据的小样本调优,提升模型在场景中的应用性能;盘古CV大模型发布时也是业界最大CV大模型,旨在解决AI工程难以泛化和复制的问题。盘古CV大模型的出现,让AI开发进入工业化模式,即一套流水线能够复制到不同的场景中去,大大节约研发人力和算力。

聚焦CV领域,开启工业化AI行业适配。由于高价值的数字化场景主要以视觉为主,因此华为近年来聚焦在CV模型的行业适配上。盘古CV大模型首次兼顾图像判别与生成能力,能同时满足底层图像恢复与高层语义理解需求,能够简单高效融合行业知识,快速适配各种下游任务。盘古CV大模型已经在百余项实际任务中得到验证,大幅提升了业务测试精度,能够节约90%以上的研发成本。例如在电力行业,应用盘古CV大模型利用海量无标注电力数据进行预训练和筛选,并结合少量标注样本微调的高效开发模式,独创性地提出了针对电力行业的预训练模型;在医药研发领域,华为研发了盘古药物分子大模型,实现了针对化合物表征学习的全新深度学习网络架构,进行了超大规模化合物表征模型的训练,在20余项药物发现任务上实现性能最优(SOTA)。总之,盘古CV模型在适配行业应用过程中均在降低开发成本的优势下,实现了样本筛选效率、筛选质量、平均精度的显著提升。

昇腾(Ascend)AI能力提供大模型全流程使能体系,构筑盘古大模型演化基石。企业用户要开发大模型,需要考虑基础开发、行业适配、实际部署等问题,华为直接打造的大模型开发使能平台,覆盖从数据准备、基础模型开发、行业应用适配到推理部署全开发流程,发布了大模型开发套件、大模型微调套件以及大模型部署套件。在大模型开发套件中,昇思MindSpore与ModelArts结合既提供了像算法开发基础能力,还具备了像并行计算、存储优化、断点续训的特殊能力。在算法开发上,昇思MindSpore提供了易用编程API,既能满足多种需求,算法还能百行代码就可实现千亿参数的Transformer模型开发;昇腾MindX提供的大模型微调套件,其功能包括两部分:一键式微调、低参数调优,即通过预置典型行业任务微调模板、小样本学习等手段,直接冻结局部参数,自动提示或者直接激活特定的参数;在推理部署方面,昇腾AI在MindStudio中提供了分布式推理服务化、模型轻量化、动态加密部署三方面能力,通过多机多卡分布式推理,可以大幅提高计算吞吐量。
面向各模态应用领域,量身打造异构计算架构CANN。昇腾AI全栈涵盖了计算硬件层、异构计算架构层、AI框架层面和应用使能层面。计算硬件是AI计算的底座,有了强力的芯片及硬件设备,上层的加速才有实施的基础。面向计算机视觉、自然语言处理、推荐系统、类机器人等领域,华为量身打造了基于“达芬奇(DaVinci)架构”的昇腾AI处理器,提升用户开发效率和释放昇腾AI处理器澎湃算力,同步推出针对AI场景的异构计算架构CANN,CANN通过提供多层次的编程接口,以全场景、低门槛、高性能的优势,支持用户快速构建基于平台的AI应用和业务。

END -
本文内容转载“计算机文艺复兴”公众号,仅供交流学习之用,若有侵权请联系删除
