网络爬虫是一种常见的数据采集技术,与屏幕抓取不同,屏幕抓取只复制屏幕上显示的像素,网络爬虫提取的是底层的HTML代码,以及存储在数据库中的数据。一般使用抓包工具获取HTML,然后使用网页解析工具提取数据。
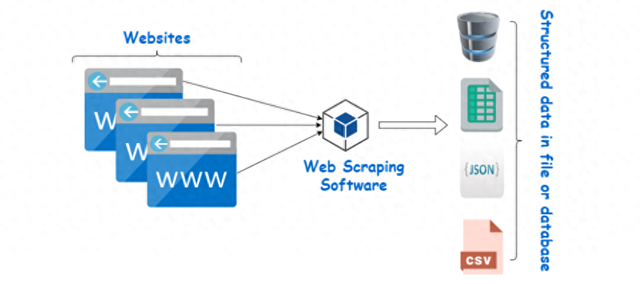
你可以使用Python编写爬虫代码实现数据采集,也可以使用自动化爬虫工具,这些工具对爬虫代码进行了封装,你只需要配置下参数,就可以自动进行爬虫。
这里推荐一款不错的自动化爬虫工具-亮数据。
亮数据平台提供了强大的数据采集工具,比如Web Scraper IDE、亮数据浏览器、SERP API等,能够自动化地从网站上抓取所需数据,无需分析目标平台的接口,直接使用亮数据提供的方案即可安全稳定地获取数据。
网站:
亮数据浏览器支持对多个网页进行批量数据抓取,适用于需要JavaScript渲染的页面或需要进行网页交互的场景。

另外,亮数据浏览器内置了自动网站解锁功能,能够应对各种反爬虫机制,确保数据的顺利抓取。它能兼容多种自动化工具,如Puppeteer、Playwright和Selenium等,用户可以根据需求选择合适的工具进行数据抓取。
主要优势:
平台化操作:无需搭建服务器,可直接在平台上创建、管理爬虫任务数据源丰富:支持网页、API、数据库等多种数据源模板化服务:提供丰富的爬虫模板,快速创建爬虫任务使用方法:
注册亮数据爬虫账号创建爬虫任务,选择数据源选择爬虫模板或编写爬虫代码设置任务参数,包括采集规则、数据存储等点击“启动任务”按钮,即可获取数据
比如说通过亮数据解锁器抓取亚马逊网站智能手机商品名称和价格信息,可以实现批量无忧抓取。


输出:

再比如使用亮数据浏览器抓取纽约时报新闻标题和发布时间数据



以上只是简单的示例,更复杂的数据抓取也都可以实现。
官网地址:
有数据抓取需求的可以试试,非常简单,能节省大量时间和精力!!
