
没想到,拥有“AI”后的世界已经发展成这样了!
自从去年ChatGPT面世后,今年5月谷歌也坐不住了,宣布要搞AI大模型,但由于种种原因,一直等到大半年后的今天,才正式发布了新一代大语言模型“Gemini”。

这还不够,它还会教人念中文并区分四个声调,甚至能手把手教你做饭,有种上班是老师,下班秒变“小厨师”的感觉,任谁看了不直呼一句“厉害”!

废话不多说,下面我们就来看看,这个AI大模型有多厉害!

长话短说,谷歌将Gemini定义为一款“原生多模态”模型!直白点解释就是,Gemini一出厂就是“全科发展”,多种感官在模型内统一学习,而不是单独学习再拼接到一起。
这里拿出OpenAI做典型,OpenAI的GPT-3.5一开始是纯文字大语言模型,直到GPT-4才安排了视觉等多模态能力,这种组装拼接吧,就好比先学了语文再学数学,极大可能带来“偏科”问题。

但全面发展的Gemini就不同,它从第一天起就设计成原生多模态结构,相当于“所有科目一起学”,用谷歌的话讲,它能无缝理解、操作不同类型的信息,包括文本、代码、音频、图像和视频等,不需要额外转换,各种模态的性能也更为平衡。
这里再举个简单的例子:同样是要理解图像信息,像GPT-4这样的非原生多模态结构模型,需要先借助OCR(光学字符识别技术)先“认出来”图里是什么——转成文本,再放到语言模型中进行语义理解。而Gemini能基于图像马上进行理解,这种端到端的理解,不会让信息在“转录”过程中丢失。
这样一对比,想必大家就都懂了。

看来,谷歌称Gemini超越了GPT-4,还真不是瞎吹牛!值得一提的是,谷歌这次一口气提供了Gemini的三个尺寸模型:Gemini Ultra、Gemini Pro、Gemini Nano,并分别对其进行了优化。
其中,Gemini Ultra版本功能最强大,能够完成高度复杂的任务,主要面向数据中心和企业级应用;Gemini Pro则是性能最好的模型,可以执行多种任务,将通过谷歌的类ChatGPT聊天机器人Bard,为众多谷歌AI服务提供支持,加持谷歌的Gmail、Maps Docs和YouTube等服务。


键盘自动生成回复语
整体来看,Gemini的多样化设计,使其能够在各种设备上运行,从手机到大型数据中心均适用,其优势显而易见。
话虽这么说,但纸上谈兵可没有信服力!

既然是被拿来“硬刚”GPT-4的模型,Gemini当然少不了经历一番测试。
根据内部消息,在推出Gemini之前,谷歌就对该模型进行过一系列标准测试。结果显示,性能上,Gemini训练所用的算力达到GPT-4的五倍,非常出色。其中,特别是在语言理解、推理、数学和编程测试中表现更佳。
尤其是Gemini Ultra,在32个常用的学术基准的30个上,已经超越GPT-4。并且Gemini Ultra在大规模多任务语言理解任务上,得分高达90.0%,是首个超越人类专家的模型。

确实,对于普通人而言,Gemini也大有用处,它可以同时识别和理解文本、图像、音频等各种形式的输入内容,因此能更好地理解细微的信息,回答与复杂主题相关的各类问题。
具体来看,对于图像理解方面,根据谷歌在发布会放出的演示视频,Gemini是玩“你画我猜”的一把好手,不仅能准确地描绘出测试者在纸上画出的图形,还能根据测试者画出的轮廓,猜测出她绘制的是什么东西。
此外,它还能根据给出的文字和图像,正确猜出所指电影的名字;又或者根据所给的服装图像,告诉你使用场景,甚至为这套搭配取名。

甚至它还能把图像,转变成代码......

而在音频理解上,Gemini也是一把好手,例如用户上传了一段非英语的音频,然后又录了一段英语的音频来提问。
这听起来似乎有点麻烦,但Gemini却可以轻松解决,它能同时处理两段不同语言的音频,并精准输出所需要的摘要内容,让人眼前一亮。

还没完!Gemini还能根据指示,教工作人员“鸭子”的普通话发音,并解释了汉语声调,点个赞!

更厉害的是,它还能教你做饭,例如煎个蛋?
你可以用语音问Gemini,还可以把手头有的食材拍个照片发过去,然后Gemini就会结合配图中的食材,及所发送的音频需求,来一步步教你怎么做出完美的煎蛋。没想到,有一天AI也能指导做饭,各位不会做饭星人有救了。

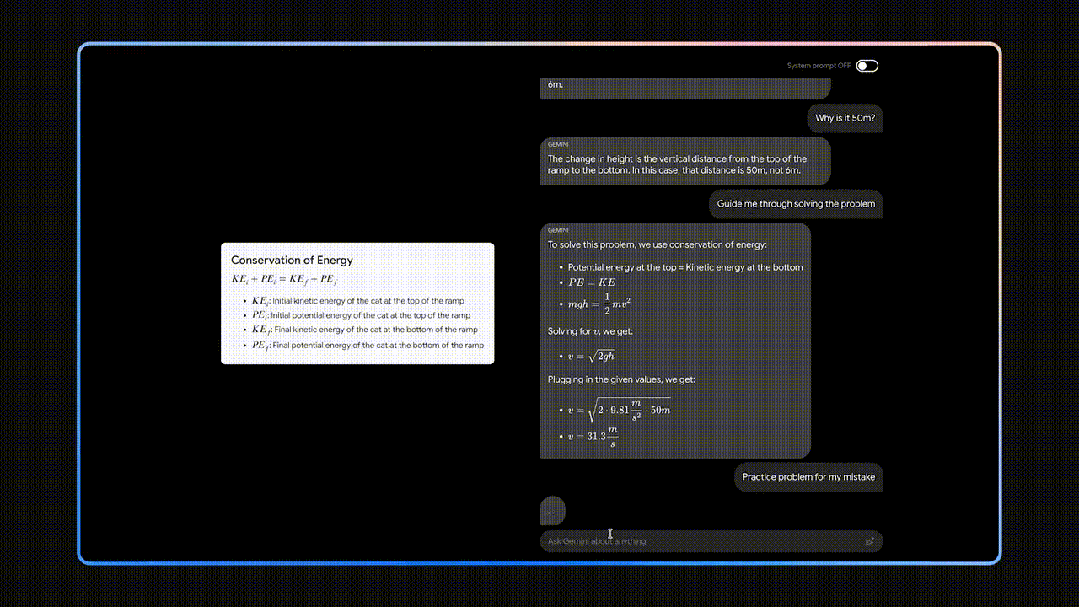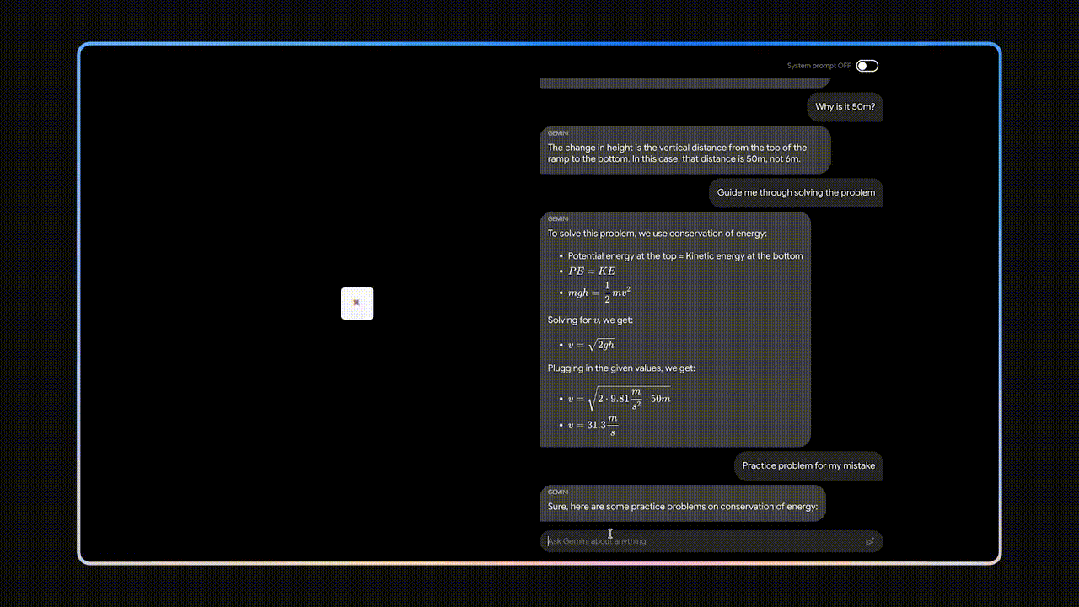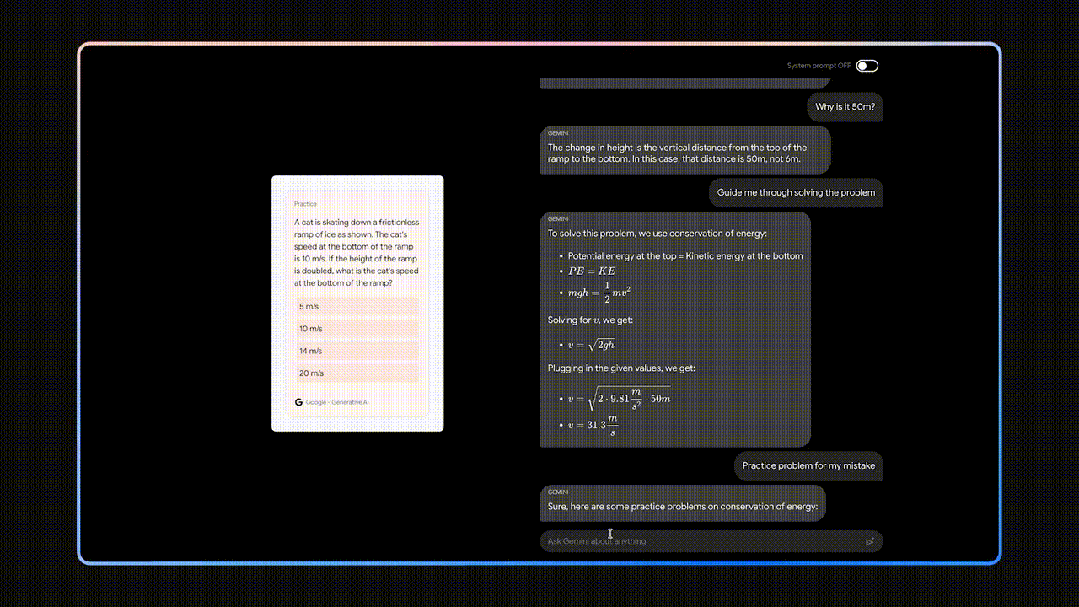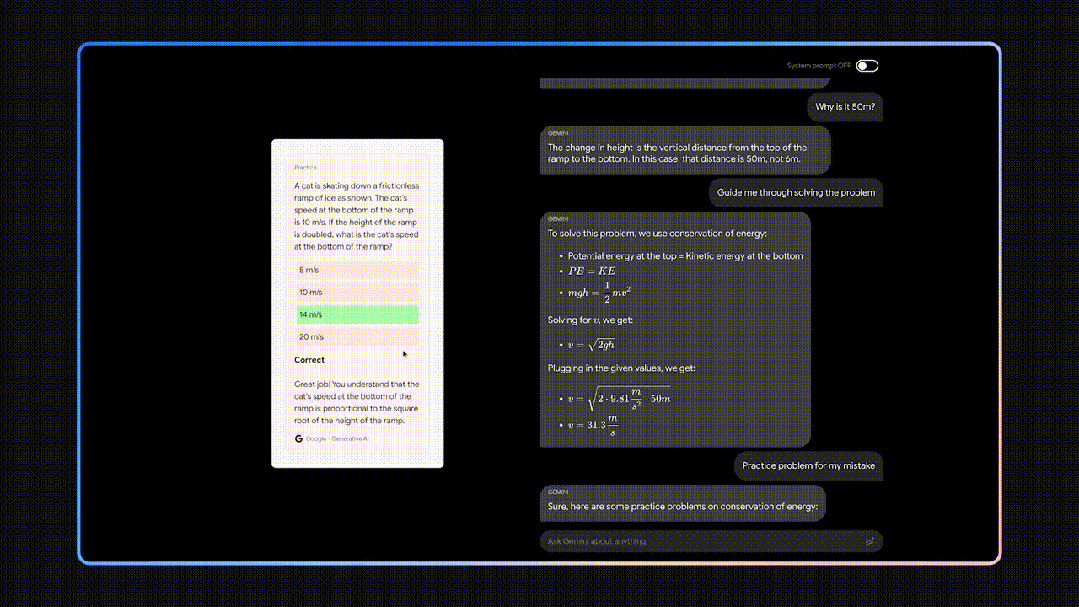
对于很多家长来说,辅导孩子作业也是下班后“必不可少的工作”,但有时一些题目自己也不会,或者因为一些别的事,没时间辅导孩子,该怎么办呢?答案很简单,拍张图交给Gemini就完事了。
它在给出正确答案的基础上,还能针对解答过程中孩子不懂的步骤给出具体解释,甚至它还可以指出孩子解答过程中具体出错的点。最后,你还可以直接让Gemini输出一个和出错类型相似的题目,让孩子再巩固一下知识点。

而为了进一步展现升级后的Bard有多强,谷歌还请了油管教育博主Mark Rober,全程使用Bard作为辅助工具,从零开始画图纸,最后真的造出了一架巨大的纸飞机。

说了这么多,其实无论是指导做饭,还是辅助造纸飞机,都直观说明了,Gemini确实给普通大众的生活,带来了一定帮助,让AI真正融入日常。
说了这么多,总之从谷歌公布的一系列参数和操作展示来看,Gemini的“AI能力”有目共睹,确实越来越像一位真正的“人类助手”!

现如今,人工智能迎来发展浪潮,对于谷歌而言,在AI即使早在AI领域深耕多年,拥有优质人才和深厚技术积累,却被OpenAI抢了先,以至于后面不得不奋力追赶。

细数下来,今年3月OpenAI发布GPT-4,随后谷歌搞了一款Bard的聊天机器人,但可惜这款对标ChatGPT的机器人并没有获得很大的市场声量。后面的故事也不少,谷歌连续官宣战略合作、紧急发布多个AI工具等等,这些大动作,无疑都表明了谷歌在强烈反击。直到“谷歌大脑”与Alphabet旗下的人工智能实验室DeepMind合并后,数百名AI精兵疯狂冲刺,才有了Gemini的诞生。
现在凭借Gemini的强大实力,谷歌终于扬眉吐气,据说Gemini官宣发布后,不少OpenAI的研究员也都发文祝贺谷歌。

但话说回来,多模态领域还在技术探索初期,Gemini的发布也只是掀起了其中一角,但这也将直接导致全球的AI大模型竞赛进入新一轮竞争,那么就期待下谷歌或OpenAI,会不会再掀起巨大水花吧。
