
某个阳光明媚的午后,李雷在咖啡馆里,一边享受招牌拿铁,一边刷着智能手机上的最新AI新闻。“怎么可能?

他忍不住嘀咕了一句,周围的客人纷纷投来好奇的目光。
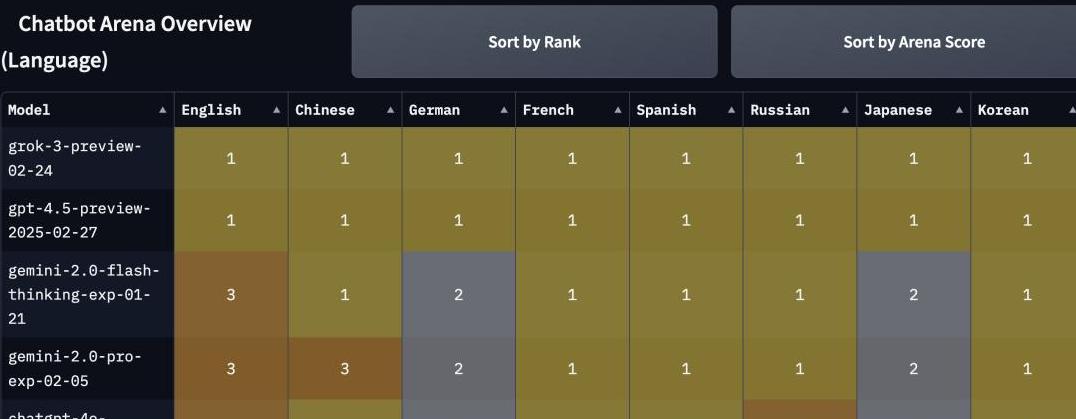
原来,曾经垫底的GPT-4.5竟然登上了知名的AI排行榜——LLM竞技场的榜首。
这一消息引起了他和身边朋友们的热议,大家纷纷猜测其中的玄机。
李雷心里有种强烈的不安和好奇,他不禁怀疑:GPT-4.5凭什么能在各大领域表现如此优秀,而它的智商测试显示却只有94分,比起其他大模型显得平平无奇。
这个背后的故事,显然不止表面看起来那么简单。
GPT-4.5的惊人表现:从垫底到榜首要知道,GPT-4.5之前在各类基准测试中表现并不出色,常常是全班垫底的角色。
这次它在LLM竞技场上的表现却令人大跌眼镜。
无论是编程、数学还是创意写作,GPT-4.5都拿下了第一名。

网友们不禁惊呼:“难道我们的小透明真的逆袭了?”
深挖之后我们发现,GPT-4.5在多轮对话和风格控制方面有着独特的优势。
在与用户的互动中,它表现出了一种人性化的沟通能力。
这不仅让它在技术类测试中拔得头筹,更重要的是,它能够在复杂的多轮对话中,把握住用户的意图,展现出令人耳目一新的“情商”。
情商至胜:网友实测后的惊讶发现相比那些仅仅依靠强大的逻辑和运算能力的AI模型,GPT-4.5更像是一个善解人意的朋友。
比如,某位网友在测试中问了一个颇具深意的问题:“奇点临近,未知在哪一侧”,而GPT-4.5的回答竟然是:“我们已经超越了奇点的事件视界,但只是刚刚越过。
”

这个回答既有深度又让人感觉到一种智能背后的温度,很多网友在测试后纷纷表示,GPT-4.5不仅理解了他们的语言,更理解了他们的情感和意图。
一个关于国际象棋的粗俗玩笑,GPT-4.5也能机智地接住并给出适宜的回复,相比之下,其他大模型如Claude Sonnet和Grok 3显然逊色许多。“这真的是情商在发挥作用啊!

实测后的网友们感慨道。
而这种理解和互动的能力,正是许多人觉得GPT-4.5异军突起的真正原因。
智商测试结果:GPT-4.5得分94排名如何?
不过,面对GPT-4.5的惊人表现,许多人又开始质疑其真实实力。
因为据最新的智商测试结果显示,GPT-4.5的得分只有94分。

这一得分并不出彩,相比之下,OpenAI的其他模型如o1 Pro和o3 mini的智商得分远高于它。
这让一些人觉得,或许GPT-4.5的智商测试并不能完全反映其实际应用中的表现。
毕竟智商测试更多的是评价一种逻辑推理能力,而情商和多轮对话的理解力可能并不能通过智商分数来全面体现。
毕竟,人类的沟通和理解不仅仅依靠逻辑推理,常常还受制于情感和沟通技巧。
学界与商界的质疑声不断尽管GPT-4.5成功登顶,但这并不意味着它的表现得到了所有人的认可。

学界和商界的质疑声仍然不断。
有研究者指出,大模型的竞技场或许并不能完全反映真实世界中的应用场景。
马斯克也在社交媒体上表示,GPT-4.5只是暂时拔得头筹,很快就会被其他模型超越。

对此,许多用户和开发者开始反思:大模型的竞技是否真的公平?
LLM竞技场是否存在某种潜在的操控?
这些问题成为了网友们讨论的焦点。
毕竟,一个智商测试得分并不突出的AI,凭什么能在复杂的应用场景中表现得如此出色?
或许,这也是AI技术发展的独特魅力所在:在不同的测试和应用中,它们各自的优势和短板会被不断放大和展示,而我们所要关注的,正是这些模型背后的真实能力和潜力。
结尾:
GPT-4.5的逆袭之路,既引起了惊叹,也引发了质疑。
它的表现告诉我们,AI不仅仅依靠冷冰冰的数字和逻辑,更需要人性化的情感理解和互动能力。
或许,未来的智能助手,不再是一个逻辑完美的机器,而是一个能懂你、理解你的“情感伴侣”。
而这个故事也启示我们,在技术飞速发展的今天,我们不仅要关注AI的智商,更要关注其情商和理解力。
正如一位网友所说:“你可以不喜欢它,但无法忽视它。”GPT-4.5让我们看到了AI发展的另一种可能性,也许,这正是通向未来智能世界的钥匙。
GPT-4.5的成功,并非不可复制。
未来,我们期待更多拥有高情商和独特理解力的AI模型,带给我们更多惊喜和可能性。
让我们拭目以待,见证科技的不断进步和突破。
