编辑:润 拉燕
【新智元导读】来自阿联酋的免费商用开源大模型登顶Hagging Face排行榜,AI大模型创业者的春天就这样到来了。
大模型时代,什么最重要?
LeCun曾经给出的答案是:开源。

当Meta的LLaMA的代码在GitHub上被泄露时,全球的开发者们都可以访问这个第一个达到GPT水平的LLM。
接下来,各种各样的LLM给AI模型开源赋予了各种各样的角度。
LLaMA给斯坦福的Alpac和Vicuna等模型铺设了道路,搭好了舞台,让他们成为了开源的领头羊。
而就在此时,猎鹰「Falcon」又杀出了重围。

Falcon 猎鹰
「Falcon」由阿联酋阿布扎比的技术创新研究所(TII)开发,从性能上看,Falcon比LLaMA的表现更好。
目前,「Falcon」有三个版本——1B、7B和40B。
TII表示,Falcon迄今为止最强大的开源语言模型。其最大的版本,Falcon 40B,拥有400亿参数,相对于拥有650亿参数的LLaMA来说,规模上还是小了一点。
规模虽小,性能能打。
先进技术研究委员会(ATRC)秘书长Faisal Al Bannai认为,「Falcon」的发布将打破LLM的获取方式,并让研究人员和创业者能够以此提出最具创新性的使用案例。

FalconLM的两个版本,Falcon 40B Instruct和Falcon 40B在Hugging Face OpenLLM排行榜上位列前两名,而Meta的LLaMA位于第三。

值得一提的是,Hugging Face是通过四个当前比较流形的基准——AI2 Reasoning Challenge,HellaSwag,MMLU和TruthfulQA对这些模型进行评估的。
尽管「Falcon」的论文目前还没公开发布,但Falcon 40B已经在经过精心筛选的1万亿token网络数据集的上进行了大量训练。
研究人员透露,「Falcon」在训练过程非常重视在大规模数据上实现高性能的重要性。
我们都知道的是,LLM对训练数据的质量非常敏感,这就是为什么研究人员会花大量的精力构建一个能够在数万个CPU核心上进行高效处理的数据管道。
目的就是,在过滤和去重的基础上从网络中提取高质量的内容。
目前,TII已经发布了精炼的网络数据集,这是一个经过精心过滤和去重的数据集。实践证明,非常有效。
仅用这个数据集训练的模型可以和其它LLM打个平手,甚至在性能上超过他们。这展示出了「Falcon」卓越的质量和影响力。

此外,Falcon模型也具有多语言的能力。
它理解英语、德语、西班牙语和法语,并且在荷兰语、意大利语、罗马尼亚语、葡萄牙语、捷克语、波兰语和瑞典语等一些欧洲小语种上也懂得不少。
Falcon 40B还是继H2O.ai模型发布后,第二个真正开源的模型。然而,由于H2O.ai并未在此排行榜上与其他模型进行基准对比,所以这两个模型还没上过擂台。
而回过头看LLaMA,尽管它的代码在GitHub上可以获取,但它的权重(weights)从未开源。
这意味着该模型的商业使用受到了一定程度的限制。
而且,LLaMA的所有版本都依赖于原始的LLaMA许可证,这就使得LLaMA不适合小规模的商业应用。
在这一点上,「Falcon」又拔得了头筹。
唯一免费的商用大模型!
Falcon是目前唯一的可以免费商用的开源模型。
在早期,TII要求,商业用途使用Falcon,如果产生了超过100万美元以上的可归因收入,将会收取10%的「使用税」。
可是财大气粗的中东土豪们没过多长时间就取消了这个限制。
至少到目前为止,所有对Falcon的商业化使用和微调都不会收取任何费用。
土豪们表示,现在暂时不需要通过这个模型挣钱。

而且,TII还在全球征集商用化方案。
对于有潜力的科研和商业化方案,他们还会提供更多的「训练算力支持」,或者提供进一步的商业化机会。

项目提交邮箱:Submissions.falconllm@tii.ae
这简直就是在说:只要项目好,模型免费用!算力管够!钱不够我们还能给你凑!
对于初创企业来说,这简直就是来自中东土豪的「AI大模型创业一站式解决方案」。

高质量的训练数据
根据开发团队称,FalconLM 竞争优势的一个重要方面是训练数据的选择。
研究团队开发了一个从公共爬网数据集中提取高质量数据并删除重复数据的流程。
在彻底清理多余重复内容后,保留了 5 万亿的token——足以训练强大的语言模型。
40B的Falcon LM使用1万亿个token进行训练, 7B版本的模型训练token达到 1.5 万亿。

(研究团队的目标是使用RefinedWeb数据集从Common Crawl中仅过滤出质量最高的原始数据)
更加可控的训练成本
TII称,与GPT-3相比,Falcon在只使用75%的训练计算预算的情况下,就实现了显著的性能提升。
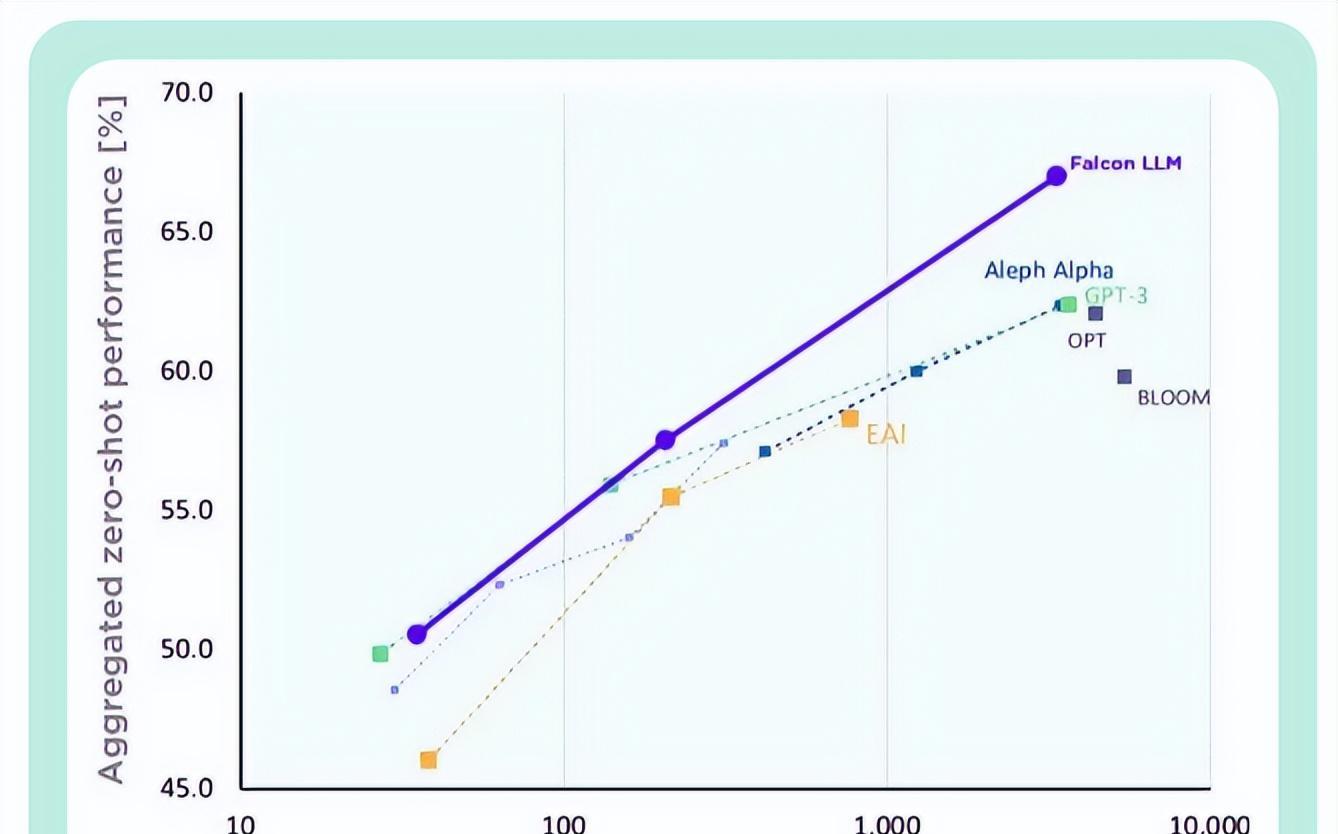

而且在推断(Inference)时只需要只需要20%的计算时间。
Falcon的训练成本,只相当于Chinchilla的40%和PaLM-62B的80% 。
成功实现了计算资源的高效利用。
参考资料:
