刘瑾在公司已经连续加班了一个星期,用掉了三瓶咖啡和无数零食,只为爬取一份网络数据。
那些复杂的网页结构和不断变化的反爬机制,搞得他几近崩溃。
就在他准备放弃的时候,他同事神秘兮兮地推送了一个链接给他:“你听说过 Crawl4AI 吗?
看看这个吧,或许能帮你解决问题。
”在点开链接的那一瞬间,一个全新的爬虫世界向他展开了。
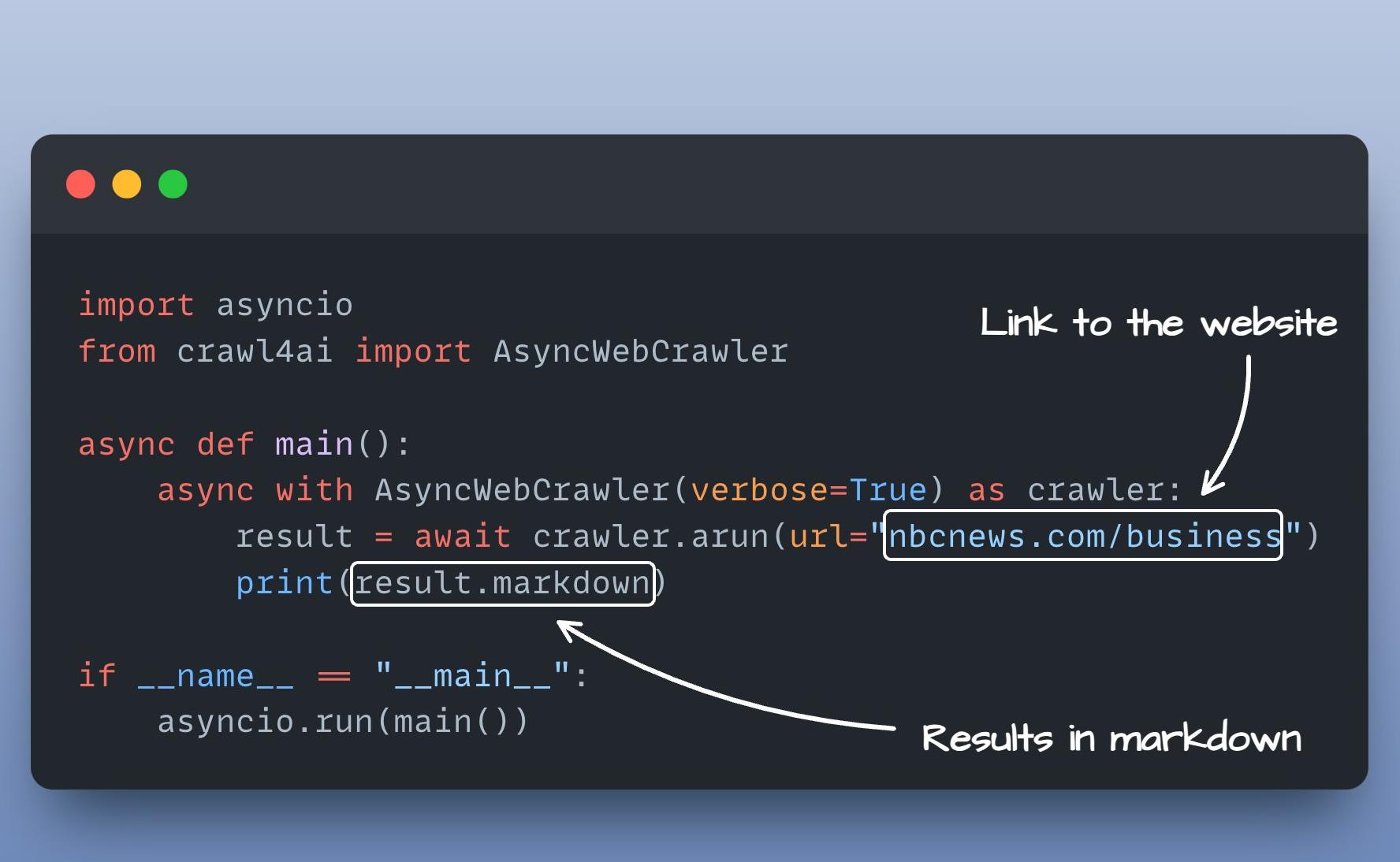
Crawl4AI 是什么?
Crawl4AI,是一个专为数据采集设计的开源工具,你可以把它想象成一个超级智能的小助手。
它基于 Playwright 的多浏览器内核,再加上 ChatGPT 的大语言模型,这两个结合起来,你会发现数据采集不再是件痛苦的事,而是变得智能高效。
Crawl4AI 如同一个数据采集的万能钥匙,不管是复杂的网页交互还是动态加载的内容,它都能轻松搞定。
多浏览器内核支持还记得那些动辄就跳出反爬机制的网页吗?
刘瑾就曾被各种验证码、动态加载折腾得死去活来。
Crawl4AI 的妙招就是它的多浏览器内核支持。
它能够在 Chromium、Firefox 和 WebKit 上运行。

这意味着,Crawl4AI 几乎可以模拟任何主流浏览器的真实用户行为。
它不仅稳定高效,更能轻松绕过各种各样的反爬机制。
你再也不必担心数据会因为网页的特殊设置而无法抓取到。
智能交互与 ChatGPT 的结合有次刘瑾为了抓取一家大型电商网站上的数据,他不得不手动填写一百多份表单来绕开防护措施。
那一天,他的脑袋里只剩下无限循环的表单和验证码。
Crawl4AI 的出现就像一束光照进了他的日常工作。
借助 ChatGPT 的自然语言处理能力,Crawl4AI 变得更聪明了。
无论是填写表单、处理验证码,还是应对动态加载的内容,Crawl4AI 都能够像人一样理解和处理。
这种智能交互能力,大大减少了手动操作的时间和精力。
插件化架构与高效性能每个数据采集任务的需求都不同,指望一个固定的爬虫来胜任,是不现实的。
Crawl4AI 采用了插件化设计,意味着你可以根据自己的具体需求自行编写和集成插件。
刘瑾最爱这个功能,他觉得这就像是给工具箱增加了各种专业工具,只需要根据不同的任务配上不同的工具,就能轻松完成各种采集任务。
而且,Crawl4AI 的性能同样让人心服口服。

它在处理大规模的数据采集任务时,不但效率高,而且稳定。
刘瑾再也不用担心电脑会因为数据量大而卡顿,甚至崩溃了。
应用场景广泛Crawl4AI 的实用性不仅在于它的智能和高效,还在于它广泛的应用场景。
拿刘瑾所在的电商行业来说,实时获取商品信息、价格变动、用户评价等数据,为市场分析和商业决策提供了可靠的支持。
其实,无论是舆情监测、内容抓取,还是学术研究、数据挖掘,甚至金融信息采集,Crawl4AI 都能轻松胜任。
这让刘瑾充满了干劲,他在脑中构思着各种应用场景,并且跃跃欲试。
总结与启示Crawl4AI 就像一个聪明又勤奋的助手,帮助我们更高效地完成那些曾经看似不可能的数据采集任务。
它不仅给刘瑾这样的数据工程师带来了福音,也让更多领域和行业受益匪浅。
在未来,随着人工智能和大数据技术的不断前进,Crawl4AI 的潜力将会更无限,甚至可能彻底改变我们对数据采集和处理的理解方式。
刘瑾决定把这一套新的数据采集解决方案应用到他的工作中,期待着它能为他带来更多惊喜。
而作为普通的数据信息工作者,我们也应该尝试拥抱新的技术,跟上时代的步伐,为自己和行业开辟出更加宽广的天地。
毕竟,数据是未来的钥匙,而先进的工具则是帮我们开启这把钥匙的那双手。
让我们一起期待,Crawl4AI 在更多领域发挥积极作用,为我们带来前所未有的变化。