DeepSeek热潮将在预训练、后训练(二次训练)和推理三大细分市场都带来巨大改变。
文|周享玥
编|赵艳秋
DeepSeek狂潮下,2025年的智算市场正在发生巨变。
业界观察,不同于DeepSeek刚出来时,一些人士对于“其算法优化可能导致智算市场需求下降”的猜测,在经历了连续几周的发酵后,市场上的算力需求正呈现短期内的快速爆发趋势。
“最近两个礼拜,来找我们咨询购买能够完整运行671B DeepSeek R1模型的AI服务器的客户数正在直线上升。”2月13日,在IDC与浪潮信息联合发布《2025年中国人工智能计算力发展评估报告》(简称《报告》)的现场,浪潮信息高级副总裁刘军告诉数智前线。
在这次《报告》中,市场分析机构IDC和智算Infra大厂浪潮信息一起,对DeepSeek给智算市场带来的变化、当下最新的智算市场格局进行了深入解读,并分享了今年智算市场发展的一些重要趋势。
01
DeepSeek狂潮下,2025年智算市场如何变?
DeepSeek是条鲶鱼,正在将市场重新调动起来。
C端用户热情高涨,即便是老人、小孩儿,知道DeepSeek的也不在少数,B端和G端的应用探索大幅提速,每天都有新一波企业和机构官宣接入DeepSeek。
算力需求在短期内激增。春节后第一周,国内外芯片厂商都在紧锣密鼓加紧适配工作,据行业人士预测,推理端的适配将会优先完成,训练端的工作则将持续一段时间。服务器厂商们也在最近接到不少咨询和采购订单。
而从中长期来看,多位行业人士均告诉数智前线,这波DeepSeek热潮将有望在预训练、后训练(二次训练)和推理三大细分市场都带来巨大改变,带动智算市场的进一步发展。
在预训练端,去年市场上一度弥漫着一股悲观情绪,Scaling Law(规模法则)被怀疑即将失效,一些大模型企业也逐渐放弃预训练。但随着DeepSeek的故事范本生效,这种趋势即将扭转,一些玩家可能有信心重返战场。
“如果DeepSeek通过算法优化,用一万张卡搞出了别人十万张卡的模型,就会有人想,我用十万张卡,用DeepSeek的这种工程模式和技术架构会训练出什么。”IDC中国副总裁周震刚说,这对全球所有大模型玩家,都是一种激励。
2月13日,OpenAI首席执行官萨姆·奥尔特曼在社交平台X上公布,OpenAI将在未来几个月内推出名为GPT-5的模型,该模型将整合OpenAI的大量技术。几天后的2月18日,马斯克正式发布了Grok 3大模型。
而在后训练端,DeepSeek带来的效率提升,正在让这个市场被加强。《报告》显示,目前Scaling Law正在从预训练扩展到后训练和推理阶段,基于强化学习、思维链等算法创新在后训练和推理阶段更多的算力投入,可以进一步大幅提升大模型的深度思考能力。
“Hugging Face上,最近每天都有基于DeepSeek去做微调、蒸馏出来的各种新版本出来。”周震刚举例说,这将对整个智算市场产生巨大推动。
推理端,则被业界认为是一个极具潜力的市场。“DeepSeek相当于瓦特时刻。瓦特把蒸汽机改良之后,实现了一个稳定的动力输出,蒸汽机得以进入各个行业。”一位行业人士说,“大模型就是蒸汽机,被改良后,可以进入各行各业。”
“DeepSeek点燃了企业客户对于大模型在企业内部做业务部署和业务结合的热情,客户大量尝鲜,经历自我试用PoC阶段后,就会思考如何在业务场景中实现更加批量的部署和应用。”刘军告诉数智前线,他们预计,后面一轮的推理算力采购需求,会比这一轮的采购量来得更大,持续时间更久。
《报告》中也对此做了总结——基于杰文斯悖论的现象表明,DeepSeek带来的算法效率的提升并未抑制算力需求,反而因更多的用户和场景的加入,推动大模型普及与应用落地,重构产业创新范式,带动数据中心、边缘及端侧算力建设。
数据显示,2024年中国人工智能算力市场规模达190亿美元,2025年将达到259亿美元,同比增长36.2%,2028年还将进一步增加至552亿美元。

智算服务市场也将高速增长。2024年,中国智算服务市场整体规模已达50亿美元,到2028年将增至266.91美元,2023-2028年五年年复合增长率为57.3%
其中,智算集成服务市场(即私有化部署市场)及GenAI IaaS市场是未来重要的两个增量市场,五年年复合增长率分别达到73%和79.8%,预计至2028年智算集成服务市场规模占比可达47%,GenAI IaaS市场规模占比达48%。

02
从追求量,到追求一个更高效的系统
《报告》中另外一个值得业界关注的关键点是,要想解决大模型落地过程中高性能算力供不应求及算力利用率低等问题,不止要“扩容”,还得“提效”。
扩容很好理解,即提升算力供给能力。在这一点上,去年,业界已经兴起过一波智算热潮,各地智算中心建设热情高涨,涌现出了不少智算大单。据数智前线不完全统计,2024年的公开招投标市场,涌现出了超460个智算中心相关项目,其中,亿元以上大单至少有62个。


而从整体市场来看,《报告》预计,2023至2028年,中国智能算力规模和通用算力规模的五年年复合增长率将分别达46.2%和18.8%,较上一版本预期值33.9%和16.6%有显著提升。

而“提效”方面,除了降低算力成本,也是为了降低能耗,这对于大模型能否落地、能否跑通商业闭环,至关重要。

《报告》中提出了“提效”的四大关键举措。
第一,以用定建,以应用为导向,进行AI基础设施建设规划,避免资源浪费。这不仅适用于企业私有化部署自己的人工智能基础设施,也十分契合于当下的智算中心建设。
此前,不少智算中心都存在利用率不高的问题,从去年开始,一些智算中心在规划初期,已经主要考虑各地的产业结构,以应用为导向来进行资源规划。比如不同的地方,可能有制造、动漫、机器人、无人智驾、低空经济等不同产业,它们对智算规模的需求不尽相同,不同芯片之间的配比也有可能不同。
最近几周,全国各地的多个智算中心都在官宣DeepSeek的部署上线,如河南空港智算中心、无锡太湖亿芯智算、南京智算中心等。DeepSeek带动的应用潮,有可能给智算中心带来新机会。
“但这也需要做出不小努力,不是简单说跑个DeepSeek的API上去就可以了。”刘军告诉数智前线,行业企业要将AI变成生产力,一定要和它自己的行业和业务数据去结合,而这个过程中,需要大量的工具和服务来进行针对性的优化,“比如人家用了一下发现吐一个字要两秒钟,就很难接受。”
第二,提升模算效率,降低算力开销。在这一点上,DeepSeek做了一个很好的示范。其通过创新性融合FP8、MLA(多头潜在注意力)和MoE(混合专家)架构,大幅提升了性能和效率。
其中的一些思路,也是业界此前在大模型的发展中遇到困难后,所共同去探索的方向。
“去年开始,大家发现,基于Dense架构的模型,再往前去演化到要训练一个超过五千亿、一万亿参数模型时,所需的算力、时间、数据量,都是当前技术条件下实现不了的。“刘军回忆,他们做过一个评估,这种情况下,需要20万张卡训练一年,才能把一个万亿的Dense模型高质量训练出来。
为此,从去年开始,业界就已经不约而同转向探索以MoE的方式,通过更高效算力投资的方式来实现更高质量的模型。比如DeepSeek从V2开始就采用的MoE架构,海外的Mistral此前也曾发布MoE架构模型。
去年5月,浪潮信息发布的源2.0-M32,同样采用了MoE的思路,通过提出和采用“基于注意力机制的门控网络”技术,构建包含32个专家的混合专家模型,大幅提升模型算力效率,单Token下训练和推理所需的算力资源仅为Llama-70B的1/19。
“业界此前已经在做类似工作,但DeepSeek给了我们更加明确的信号。”刘军说,”下一阶段,大家会从原来单纯追求量的增长,买了多少卡,变成追求如何变成一个更高效的系统。”
第三,优化算力基础设施架构。如采用先进的计算架构,提升单计算节点性能,提高计算效率。优化内存层次结构,减少数据传输延迟,增强数据处理速度。利用智能调度算法合理分配计算任务,优化集群管理方面,确保资源高效利用。
第四,增强数据支持,减少无效计算。比如可以通过建立高质量的数据集,并构建统一的数据存储和访问接口,简化数据流动与共享,为AI模型训练提供强有力的支持。
《报告》也显示,未来18个月内,为了将大模型引入生产,除了硬件的升级会是企业的首要投资目标外,软件和服务方面的支出也会是企业生成式AI项目的主要支出方向。
“2024年开始,用户在软件方面的投资增长越来越快,随着DeepSeek带来的应用尝鲜潮的持续奔腾,相应的软件和服务、定制化解决方案的开发会越来越多。”IDC中国副总裁周震刚说。

在这种背景下,客户需要更全栈化的支持。针对这些需求,浪潮信息目前已提供全链条、全栈化的人工智能技术服务,从AI server计算的硬件、“源”大模型、AI station算力调度平台到EPAI大模型落地工具。
03
推理市场爆发,2028年推理工作负载占比将达73%
《报告》中还提出一个重要的趋势,推理算力有望迎来大爆发,2025年推理的工作负载占比将达到67%。“当前我们接到的所有购买需求,几乎都是推理的。”浪潮信息高级副总裁刘军告诉数智前线。
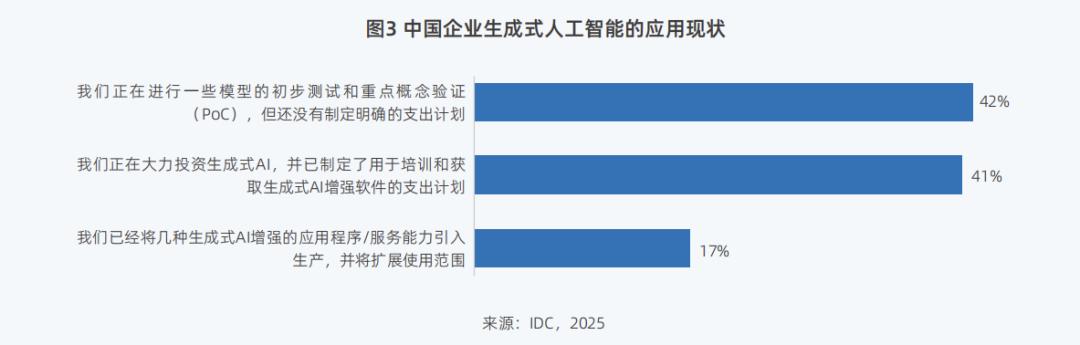
目前42%的中国企业已开始进行大模型的初步测试和重点概念验证,17%的企业已将技术引入生产阶段,并应用于实际业务中。
与之相对应的是,2024年,国内推理与训练的工作负载占比已分别达到65%和35%。《报告》预计,到2028年,推理工作负载占比还将进一步达到73%,远超训练算力27%的占比。

面对这一趋势,公有云市场的各云计算大厂和运营商们都已摩拳擦掌,火速宣布支持DeepSeek模型调用或部署,并卷起价格战,争夺市场。
而在私有云或者说私有化部署方面,业界观察,这一市场预计将成为推动推理算力增长的一股重要力量。“企业将要建设自己的小型智算中心,部署1~10台服务器(百卡之内),或10来20台服务器(百卡规模)。”一位智算领域人士表示。
刘军也告诉数智前线,1~20台的区间,会是企业客户未来一段时间采购私有化算力比较适合的规模。
“但这应该会经历一个过程,大家不会特别盲目,一上来就不顾一切,上好多机器。”刘军说,在早期,企业应该会先购买一定数量的AI服务器回去构建环境,去针对自己的业务开展PoC,验证对自己的业务很有帮助后,才会上一个比较大的量。
IDC副总裁周震刚则预测,在这种背景下,开源+一体机的模式,“很可能是未来一段时间内一个非常爆发性的需求。”
“过去几年这种需求相对较少,因为一体机做推理还可以,做训练可能没有那么大的算力,而推理又可以直接通过service解决,也不一定本地部署这么一个推理机。但DeepSeek出来后,市场上对一体机的需求在大幅度上升。最近有很多企业都在跟我们沟通,希望了解一下这个市场规模是什么样的。”周震刚告诉数智前线。
浪潮信息2月11日刚推出的元脑R1推理服务器,也在最近受到不少企业关注。据悉,该产品通过系统创新和软硬协同优化,单机即可部署运行DeepSeek R1 671B模型。
“为什么要强调单机就能把它跑下来?因为现在有好多方案是比较麻烦的,模型尺寸大了后,如果你不得不用四台机器才能装下这样一个模型,对客户去适用这个环境就是一个很大的门槛,而如果你一台机器,回去开机把模型装上,马上就能用上Chatbox、CherryStudio,就会极大方便大家去尝试满血版671B的模型。”刘军说。
无独有偶,天翼云、联想百应等也都在最近推出了基于DeepSeek等技术的一体机。一场关于推理算力的竞争已经开始。
“真正到了推理场景,大家关心的是我的用户体验好不好,在保证用户体验的情况下,每元钱能有多少Token。”刘军告诉数智前线,体验和性价比将决定算力厂商在推理市场中的生存能力。
在他看来,推理目前要重点解决两方面的问题,一个是怎么用更少的机器把模型装进去、跑起来,另一个则是产生Token的速度是不是够快。
“我们很多工作都在围绕这两个方面来开展。”刘军举例说,比如他们会通过PD分离的策略,将推理的两个重要阶段——预填充(Prefill)和 解码(Decode)解耦部署,通过构建分离式算力资源池,缩短计算时间,降低计算成本,提高资源利用率。
不管是推理端,还是训练端,智算市场作为大模型落地的重要支撑,在未来几年内将保持高速增长。在应用爆发的临界点到来之前,保有热情,但不盲目激进,仍是最适合当下的一个行为准则。