真实标签的不完美性是机器学习领域一个不可避免的挑战。从科学测量数据到深度学习模型训练中的人工标注,真实标签总是包含一定比
视频作为一种富含信息且密集的媒介,已广泛应用于娱乐、社交媒体、安全监控和自动驾驶等领域。人类能够轻松理解视频内容,例如理
生成对抗网络(GANs)的训练效果很大程度上取决于其损失函数的选择。本研究首先介绍经典GAN损失函数的理论基础,随后使用
在人工智能技术快速迭代发展的背景下,大语言模型(LLMs)已成为自然语言处理与生成领域的核心技术。然而,将这些模型与人类
近年来,人工智能领域在多模态表示学习方面取得了显著进展,这类模型通过统一框架理解并整合不同数据类型间的语义信息,特别是图
SWEET-RL(Step-WisE Evaluation from Training-time information
在异常检测领域,尤其针对工业机械、核反应堆和网络安全等复杂系统,传统方法往往难以有效处理高维度且相互关联的数据流。多元状
RAL-Writer Agent是一种专业的人工智能写作辅助技术,旨在解决生成高质量、内容丰富的长篇文章时所面临的技术挑
预测不确定性量化在数据驱动决策过程中具有关键作用。无论是评估医疗干预的风险概率还是预测金融市场的价格波动范围,我们常需要
扩散模型已成为现代文本到图像 (T2I) 生成技术的核心,能够生成高质量图像,但其迭代式推理过程导致生成速度缓慢。多数模
广义优势估计(Generalized Advantage Estimation, GAE)由Schulman等人在201
自VQGAN和Latent Diffusion Models等视觉生成框架问世以来,先进的图像生成系统通常采用两阶段架构
本研究提出了一种新型强化学习(RL)框架SEARCH-R1,该框架使大型语言模型(LLM)能够实现多轮、交错的搜索与推理
生成模型已成为人工智能领域的关键突破,赋予机器创建高度逼真的图像、音频和文本的能力。在众多生成技术中,扩散模型和Flow
在深度学习的背景下,NVIDIA的CUDA与AMD的ROCm框架缺乏有效的互操作性,导致基础设施资源利用率显著降低。随着
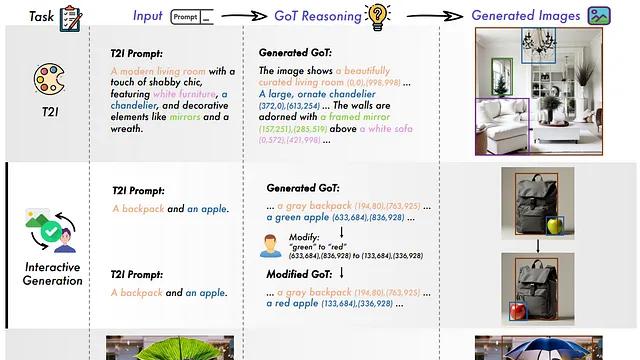
本文探讨GoT框架如何通过语义-空间思维链方法提升图像生成的精确性与一致性计算机视觉领域正经历一次技术革新:一种不仅能将
传统检索增强生成(RAG)架构因依赖静态检索机制,在处理需要顺序信息搜索的复杂问题时存在效能限制。尽管基于代理的推理与搜
原始"Attention Is All You Need"论文中提出的标准Transformer架构最初设计用于处理离散
在构建搜索引擎系统时,有效的评估机制是保证系统质量的关键环节。当用户输入查询词如"machine learning tu
神经网络技术已在计算机视觉与自然语言处理等多个领域实现了突破性进展。然而在微分方程求解领域,传统神经网络因其依赖大规模标
签名:提供专业的人工智能知识,包括CV NLP 数据挖掘等